集成FlinkCDC
Paimon 支持多种通过模式演化将数据提取到 Paimon 表中的方法。这意味着添加的列会实时同步到Paimon表中,并且不会为此重新启动同步作业。 目前支持以下同步方式:
- MySQL同步表:将MySQL中的一张或多张表同步到一张Paimon表中。
- MySQL同步数据库:将整个MySQL数据库同步到一个Paimon数据库中。
- API同步表:将您的自定义DataStream输入同步到一张Paimon表中。
- Kafka同步表:将一个Kafka topic的表同步到一张Paimon表中。
- Kafka同步数据库:将一个包含多表的Kafka主题或多个各包含一表的主题同步到一个Paimon数据库中。
1. MySQL
添加Flink CDC连接器,然后重启yarn-session集群和sql-client:
[jack@Node02 ~]$ cd /opt/module/flink-1.20.2/lib
[jack@Node02 lib]$ ll
总用量 312152
-rw-r--r--. 1 jack jack 198366 6月 13 19:00 flink-cep-1.20.2.jar
-rw-r--r--. 1 jack jack 563714 6月 13 19:01 flink-connector-files-1.20.2.jar
-rw-r--r--. 1 jack jack 412253 9月 10 07:55 flink-connector-mysql-cdc-3.4.0.jar
-rw-r--r--. 1 jack jack 102375 6月 13 19:02 flink-csv-1.20.2.jar
-rw-r--r--. 1 jack jack 125897594 6月 13 19:05 flink-dist-1.20.2.jar
-rw-r--r--. 1 jack jack 204407 6月 13 19:02 flink-json-1.20.2.jar
-rw-r--r--. 1 jack jack 21060634 6月 13 19:04 flink-scala_2.12-1.20.2.jar
-rw-r--r--. 1 jack jack 53226520 9月 1 00:46 flink-sql-connector-hive-3.1.3_2.12-1.20.2.jar
-rw-r--r--. 1 jack jack 15714643 6月 13 19:05 flink-table-api-java-uber-1.20.2.jar
-rw-r--r--. 1 jack jack 38424518 6月 13 19:04 flink-table-planner-loader-1.20.2.jar
-rw-r--r--. 1 jack jack 3548975 6月 13 19:00 flink-table-runtime-1.20.2.jar
-rw-r--r--. 1 jack jack 1832290 8月 31 23:44 hadoop-mapreduce-client-core-3.4.1.jar
-rw-r--r--. 1 jack jack 356379 5月 19 13:13 log4j-1.2-api-2.24.3.jar
-rw-r--r--. 1 jack jack 348513 12月 10 2024 log4j-api-2.24.3.jar
-rw-r--r--. 1 jack jack 1914666 12月 10 2024 log4j-core-2.24.3.jar
-rw-r--r--. 1 jack jack 25319 12月 10 2024 log4j-slf4j-impl-2.24.3.jar
-rw-r--r--. 1 jack jack 2481560 9月 1 06:25 mysql-connector-j-8.0.33.jar
-rw-r--r--. 1 jack jack 53287592 8月 31 23:38 paimon-flink-1.20-1.2.0.jar
-rw-r--r--. 1 jack jack 11628 9月 9 07:42 paimon-flink-action-1.2.0.jar1.1 同步MySQL的表
语法说明如下:
<FLINK_HOME>/bin/flink run \
/path/to/paimon-flink-action-0.8.2.jar \
mysql-sync-table
--warehouse <warehouse-path> \
--database <database-name> \
--table <table-name> \
[--partition-keys <partition-keys>] \
[--primary-keys <primary-keys>] \
[--computed-column <'column-name=expr-name(args[, ...])'> [--computed-column ...]] \
[--mysql-conf <mysql-cdc-source-conf> [--mysql-conf <mysql-cdc-source-conf> ...]] \
[--catalog-conf <paimon-catalog-conf> [--catalog-conf <paimon-catalog-conf> ...]] \
[--table-conf <paimon-table-sink-conf> [--table-conf <paimon-table-sink-conf> ...]]参数说明:
| 配置 | 描述 |
|---|---|
| --warehouse | Paimon仓库路径 |
| --database | Paimon Catalog中的数据库名称 |
| --table | Paimon表名称 |
| --partition-keys | Paimon表的分区键。如果有多个分区键, 请用逗号连接,例如"dt,hh,mm"。 |
| --primary-keys | Paimon表的主键。如果有多个主键,请用逗号连接, 例如"buyer_id,seller_id"。 |
| --computed-column | 计算列的定义。参数字段来自MySQL表字段名称。 |
| --mysql-conf | Flink CDC MySQL源表的配置。每个配置都应以"key=value"的格式指定。 主机名、用户名、密码、数据库名和表名是必需配置,其他是可选配置。 |
| --catalog-conf | Paimon Catalog的配置。 每个配置都应以"key=value"的格式指定。 |
| --table-conf | Paimon表sink的配置。 每个配置都应以"key=value"的格式指定。 |
如果指定的Paimon表不存在,此操作将自动创建该表。其schema将从所有指定的MySQL表派生。如果Paimon表已存在,则其schema将与所有指定MySQL表的schema进行比较。
## MySQL一张表同步到Paimon一张表, =两边不能有空格
bin/flink run \
-Drest.address=gbasehd112 \
-Drest.port=44214 \
/opt/gbaseHD/flink-1.16.2/lib/paimon-flink-action-0.8.2.jar \
mysql-sync-table \
--warehouse hdfs://gbasehd111:8020/user/hive/warehouse/ \
--database test \
--table sensor_cdc \
--primary-keys id \
--mysql-conf hostname=gbasehd111 \
--mysql-conf username=root \
--mysql-conf password=gbasehd123456 \
--mysql-conf database-name=test \
--mysql-conf table-name='sensor' \
--mysql-conf jdbc.properties.useSSL=false \
--mysql-conf jdbc.properties.useUnicode=true \
--mysql-conf jdbc.properties.characterEncoding=utf8 \
--catalog-conf metastore=hive \
--catalog-conf uri=thrift://gbasehd113:9083 \
--table-conf bucket=4 \
--table-conf changelog-producer=input \
--table-conf sink.parallelism=4什么是changelog-producer
changelog-producer表示将数据另外写入到变更日志文件,该日志文件可以在读取期间直接读取,配置的选项有:
- "none":没有变更日志文件。
- "input":刷新内存表时双写变更日志文件,变更日志来自输入。
- "full-compaction":每次需要压缩生成变更日志文件。
- "lookup":在提交数据写入之前通过"lookup"生成变更日志文件。
如果报错如下,提示rest.address must be set: 解决办法是加入参数:
解决办法是加入参数:
-Drest.address=gbasehd112 \
-Drest.port=44214 \执行后会发现Paimon会自动给我们建表:
Flink SQL> use catalog hive_catalog;
[INFO] Execute statement succeeded.
Flink SQL> use test;
[INFO] Execute statement succeeded.
Flink SQL> show tables;
+-------------------+
| table name |
+-------------------+
| dm_source_tbl_cdc |
+-------------------+
1 row in set
Flink SQL> desc dm_source_tbl_cdc;
+-------------+--------------+-------+---------+--------+-----------+---------+
| name | type | null | key | extras | watermark | comment |
+-------------+--------------+-------+---------+--------+-----------+---------+
| id | BIGINT | FALSE | PRI(id) | | | 主键 |
| tbl_name | VARCHAR(50) | FALSE | | | | 表名 |
| tbl_comment | VARCHAR(500) | TRUE | | | | 注释 |
| tbl_remark | VARCHAR(300) | TRUE | | | | 备注 |
+-------------+--------------+-------+---------+--------+-----------+---------+
4 rows in set如果修改MySQL的数据,把id=1的数据修改,发现Paimon会自动变更数据:
Flink SQL> select * from dm_source_tbl_cdc;
+----+----------------------+--------------------------------+--------------------------------+--------------------------------+
| op | id | tbl_name | tbl_comment | tbl_remark |
+----+----------------------+--------------------------------+--------------------------------+--------------------------------+
| +I | 1 | test | 测试 | 备注 |
| +I | 4 | jack | 杰哥 | 杰哥 |
| +I | 3 | tuanzi | tuanzi | tuanzi |
| +I | 2 | user | 用户表 | test |
| +I | 5 | 新网银行 | 二楼 | it |
| +I | 6 | 久远银海 | 22楼 | 民政 |
| +I | 8 | 北京 | 成都 | test |
| +I | 999 | 中国 | test | 四川 |
| +I | 7 | 直通万联 | 11楼 | 车险 |
| +I | 9 | 南航 | 白云山机场 | learn |
| -D | 1 | test | 测试 | 备注 |
| +I | 1 | 圆圆 | 测试 | 备注 |在HDFS上面可以看到不仅存储数据,由于设置的是changelog-producer=input, 所以还保存了changelog的信息: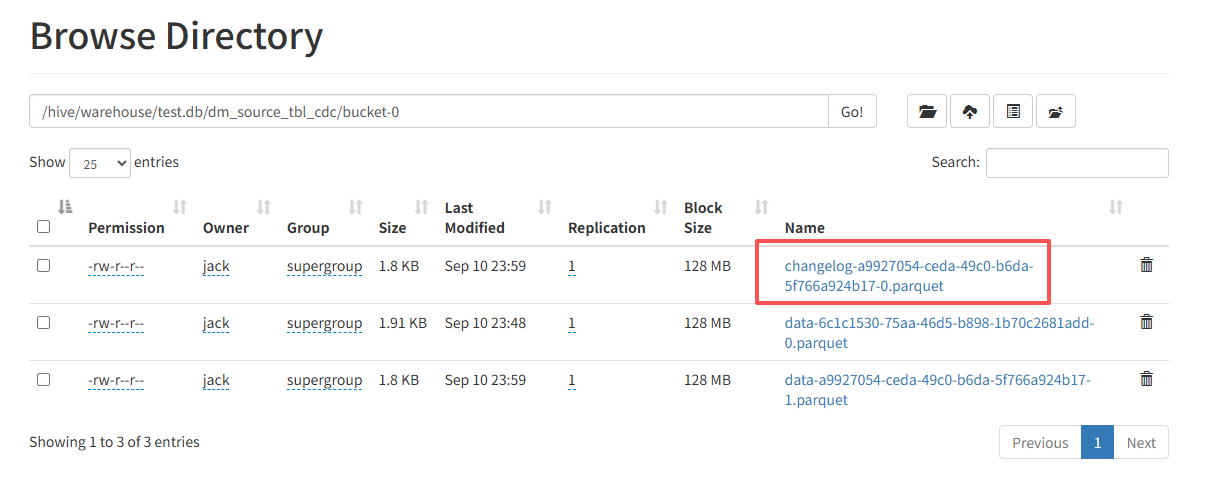
1.2 同步数据库
语法说明如下:
<FLINK_HOME>/bin/flink run \
/path/to/paimon-flink-action-0.8.2.jar \
mysql-sync-database
--warehouse <warehouse-path> \
--database <database-name> \
[--ignore-incompatible <true/false>] \
[--table-prefix <paimon-table-prefix>] \
[--table-suffix <paimon-table-suffix>] \
[--including-tables <mysql-table-name|name-regular-expr>] \
[--excluding-tables <mysql-table-name|name-regular-expr>] \
[--mysql-conf <mysql-cdc-source-conf> [--mysql-conf <mysql-cdc-source-conf> ...]] \
[--catalog-conf <paimon-catalog-conf> [--catalog-conf <paimon-catalog-conf> ...]] \
[--table-conf <paimon-table-sink-conf> [--table-conf <paimon-table-sink-conf> ...]]参数说明:
| 配置 | 描述 |
|---|---|
| --warehouse | Paimon仓库路径 |
| --database | Paimon Catalog中的数据库名称 |
| --ignore-incompatible | 默认为false,在这种情况下,如果Paimon中存在MySQL表名, 并且它们的schema不兼容,则会抛出异常。 您可以显式将其指定为true以忽略不兼容的表和异常。 |
| --table-prefix | 所有需要同步的Paimon表的前缀。 例如希望所有同步表都以"ods_"作为前缀,则可以指定"--table-prefix ods_"。 |
| --table-suffix | 所有需要同步的Paimon表的后缀。 用法与"--table-prefix"相同。 |
| --including-tables | 用于指定要同步哪些源表。 您必须使用" |
| --excluding-tables | 用于指定哪些源表不同步。用法与"--include-tables"相同。 如果同时指定了"--except-tables",则"--except-tables"的优先级高于"--include-tables"。 |
| --excluding-tables | 用于指定哪些源表不同步。用法与"--include-tables"相同。 如果同时指定了"--except-tables", 则"--except-tables"的优先级高于"--include-tables"。 |
| --mysql-conf | Flink CDC MySQL源表的配置。每个配置都应以"key=value"的格式指定。 主机名、用户名、密码、数据库名和表名是必需配置,其他是可选配置。 |
| --catalog-conf | Paimon Catalog的配置。每个配置都应以"key=value"的格式指定。 |
| --table-conf | Paimon表sink的配置。每个配置都应以"key=value"的格式指定。 |
只有具有主键的表才会被同步。对于每个需要同步的MySQL表,如果对应的Paimon表不存在,该操作会自动创建该表。其schema将从所有指定的MySQL表派生。如果 Paimon 表已存在,则其schema将与所有指定MySQL表的schema进行比较。
## MySQL中的数据库同步到Paimon中
bin/flink run \
-Drest.address=gbasehd112 \
-Drest.port=44214 \
/opt/gbaseHD/flink-1.16.2/lib/paimon-flink-action-0.8.2.jar \
mysql-sync-database \
--warehouse hdfs://gbasehd111:8020/user/hive/warehouse/ \
--database test \
--table-prefix "ods_" \
--table-suffix "_cdc" \
--mysql-conf hostname=gbasehd111 \
--mysql-conf username=root \
--mysql-conf password=gbasehd123456 \
--mysql-conf database-name=test \
--catalog-conf metastore=hive \
--catalog-conf uri=thrift://gbasehd113:9083 \
--table-conf bucket=4 \
--table-conf changelog-producer=input \
--table-conf sink.parallelism=4 \
--including-tables 'user_info|order_info|activity_rule'如果前面同步表的命令已经在执行了, 如何在不停止任务的情况下额外的表呢?效果达到已有的表继续从停止的位置继续同步,新加入的表同步也包含历史数据?可以参考下面的做法:
1.3 添加同步表
/bin/flink run \
--fromSavepoint /sp/paimon \
-Drest.address=gbasehd112 \
-Drest.port=44214 \
/opt/gbaseHD/flink-1.16.2/lib/paimon-flink-action-0.8.2.jar \
mysql-sync-database \
--warehouse hdfs://gbasehd111:8020/user/hive/warehouse/ \
--database test \
--mysql-conf hostname=gbasehd111 \
--mysql-conf username=root \
--mysql-conf password=gbasehd123456 \
--mysql-conf database-name=test \
--catalog-conf metastore=hive \
--catalog-conf uri=thrift://gbasehd113:9083 \
--table-conf bucket=4 \
--including-tables 'product|user|address|order|custom'使用savepoint, 我们可以通过从作业的先前快照中恢复并从而重用作业的现有状态来实现这一点。恢复的作业将首先对新添加的表进行快照,然后自动从之前的位置继续读取变更日志。
2. Kafka
因为Kafka本身不产生CDC数据,因此Kafka CDC的数据来源实际是CDC数据同步工具产生的,针对这些CDC工具不同的数据格式,Paimon都做了支持,Paimon版本1.2列出支持的格式如下: 
2.1 添加Kafka连接器
cp flink-sql-connector-kafka-3.4.0-1.20.jar /opt/module/flink-1.20.2/lib2.2 同步表
- 语法说明
将Kafka的一个主题中的一张表同步到一张Paimon表中:
<FLINK_HOME>/bin/flink run \
/path/to/paimon-flink-action-1.2.jar \
kafka-sync-table
--warehouse <warehouse-path> \
--database <database-name> \
--table <table-name> \
[--partition-keys <partition-keys>] \
[--primary-keys <primary-keys>] \
[--computed-column <'column-name=expr-name(args[, ...])'> [--computed-column ...]] \
[--kafka-conf <kafka-source-conf> [--kafka-conf <kafka-source-conf> ...]] \
[--catalog-conf <paimon-catalog-conf> [--catalog-conf <paimon-catalog-conf> ...]] \
[--table-conf <paimon-table-sink-conf> [--table-conf <paimon-table-sink-conf> ...]]参数说明:
| 配置 | 描述 |
|---|---|
| --warehouse | Paimon仓库路径。 |
| --database | Paimon Catalog中的数据库名称。 |
| --table | Paimon表名称。 |
| --partition-keys | Paimon 表的分区键。 如果有多个分区键,请用逗号连接,例如“dt,hh,mm”。 |
| --primary-keys | Paimon 表的主键。 如果有多个主键,请用逗号连接,例如“buyer_id,seller_id”。 |
| --computed-column | 计算列的定义。 参数字段来自Kafka主题的表字段名称。 |
| --kafka-conf | Flink Kafka 源的配置。每个配置都应以“key=value”的格式指定。 properties.bootstrap.servers、topic、properties.group.id 和 value.format 是必需配置,其他配置是可选的。 |
| --catalog-conf | Paimon Catalog的配置。 每个配置都应以“key=value”的格式指定。 |
| --table-conf | Paimon表sink的配置。 每个配置都应以“key=value”的格式指定。 |
2.3 案例实操
- 准备数据
#准备数据(canal-json格式),为了方便,省去canal解析生产数据过程,直接将canal格式的数据插入topic里
[jack@Node01 kafka-3.9.1]$ ./bin/kafka-console-producer.sh --broker-list 192.168.7.201:9092 --topic paimon_canal_1
>{"data":[{"id":"6","login_name":"t7dk2h","nick_name":"冰冰11","passwd":null,"name":"淳于冰","phone_num":"13178654378","email":"t7dk2h@263.net","head_img":null,"user_level":"1","birthday":"1997-12-08","gender":null,"create_time":"2022-06-08 00:00:00","operate_time":null,"status":null}],"database":"gmall","es":1689150607000,"id":1,"isDdl":false,"mysqlType":{"id":"bigint","login_name":"varchar(200)","nick_name":"varchar(200)","passwd":"varchar(200)","name":"varchar(200)","phone_num":"varchar(200)","email":"varchar(200)","head_img":"varchar(200)","user_level":"varchar(200)","birthday":"date","gender":"varchar(1)","create_time":"datetime","operate_time":"datetime","status":"varchar(200)"},"old":[{"nick_name":"冰冰"}],"pkNames":["id"],"sql":"","sqlType":{"id":-5,"login_name":12,"nick_name":12,"passwd":12,"name":12,"phone_num":12,"email":12,"head_img":12,"user_level":12,"birthday":91,"gender":12,"create_time":93,"operate_time":93,"status":12},"table":"user_info","ts":1689151566836,"type":"UPDATE"}
{"data":[{"id":"7","login_name":"vihcj30p1","nick_name":"豪心22","passwd":null,"name":"魏豪心","phone_num":"13956932645","email":"vihcj30p1@live.com","head_img":null,"user_level":"1","birthday":"1991-06-07","gender":"M","create_time":"2022-06-08 00:00:00","operate_time":null,"status":null}],"database":"gmall","es":1689151623000,"id":2,"isDdl":false,"mysqlType":{"id":"bigint","login_name":"varchar(200)","nick_name":"varchar(200)","passwd":"varchar(200)","name":"varchar(200)","phone_num":"varchar(200)","email":"varchar(200)","head_img":"varchar(200)","user_level":"varchar(200)","birthday":"date","gender":"varchar(1)","create_time":"datetime","operate_time":"datetime","status":"varchar(200)"},"old":[{"nick_name":"豪心"}],"pkNames":["id"],"sql":"","sqlType":{"id":-5,"login_name":12,"nick_name":12,"passwd":12,"name":12,"phone_num":12,"email":12,"head_img":12,"user_level":12,"birthday":91,"gender":12,"create_time":93,"operate_time":93,"status":12},"table":"user_info","ts":1689151623139,"type":"UPDATE"}
[2025-09-25 00:55:35,384] WARN [Producer clientId=console-producer] The metadata response from the cluster reported a recoverable issue with correlation id 6 : {paimon_canal=UNKNOWN_TOPIC_OR_PARTITION} (org.apache.kafka.clients.NetworkClient)
{"data":[{"id":"8","login_name":"02r2ahx","nick_name":"卿卿33","passwd":null,"name":"穆卿","phone_num":"13412413361","email":"02r2ahx@sohu.com","head_img":null,"user_level":"1","birthday":"2001-07-08","gender":"F","create_time":"2022-06-08 00:00:00","operate_time":null,"status":null}],"database":"gmall","es":1689151626000,"id":3,"isDdl":false,"mysqlType":{"id":"bigint","login_name":"varchar(200)","nick_name":"varchar(200)","passwd":"varchar(200)","name":"varchar(200)","phone_num":"varchar(200)","email":"varchar(200)","head_img":"varchar(200)","user_level":"varchar(200)","birthday":"date","gender":"varchar(1)","create_time":"datetime","operate_time":"datetime","status":"varchar(200)"},"old":[{"nick_name":"卿卿"}],"pkNames":["id"],"sql":"","sqlType":{"id":-5,"login_name":12,"nick_name":12,"passwd":12,"name":12,"phone_num":12,"email":12,"head_img":12,"user_level":12,"birthday":91,"gender":12,"create_time":93,"operate_time":93,"status":12},"table":"user_info","ts":1689151626863,"type":"UPDATE"}
{"data":[{"id":"9","login_name":"mjhrxnu","nick_name":"武新44","passwd":null,"name":"罗武新","phone_num":"13617856358","email":"mjhrxnu@yahoo.com","head_img":null,"user_level":"1","birthday":"2001-08-08","gender":null,"create_time":"2022-06-08 00:00:00","operate_time":null,"status":null}],"database":"gmall","es":1689151630000,"id":4,"isDdl":false,"mysqlType":{"id":"bigint","login_name":"varchar(200)","nick_name":"varchar(200)","passwd":"varchar(200)","name":"varchar(200)","phone_num":"varchar(200)","email":"varchar(200)","head_img":"varchar(200)","user_level":"varchar(200)","birthday":"date","gender":"varchar(1)","create_time":"datetime","operate_time":"datetime","status":"varchar(200)"},"old":[{"nick_name":"武新"}],"pkNames":["id"],"sql":"","sqlType":{"id":-5,"login_name":12,"nick_name":12,"passwd":12,"name":12,"phone_num":12,"email":12,"head_img":12,"user_level":12,"birthday":91,"gender":12,"create_time":93,"operate_time":93,"status":12},"table":"user_info","ts":1689151630781,"type":"UPDATE"}
{"data":[{"id":"10","login_name":"kwua2155","nick_name":"纨纨55","passwd":null,"name":"姜纨","phone_num":"13742843828","email":"kwua2155@163.net","head_img":null,"user_level":"3","birthday":"1997-11-08","gender":"F","create_time":"2022-06-08 00:00:00","operate_time":null,"status":null}],"database":"gmall","es":1689151633000,"id":5,"isDdl":false,"mysqlType":{"id":"bigint","login_name":"varchar(200)","nick_name":"varchar(200)","passwd":"varchar(200)","name":"varchar(200)","phone_num":"varchar(200)","email":"varchar(200)","head_img":"varchar(200)","user_level":"varchar(200)","birthday":"date","gender":"varchar(1)","create_time":"datetime","operate_time":"datetime","status":"varchar(200)"},"old":[{"nick_name":"纨纨"}],"pkNames":["id"],"sql":"","sqlType":{"id":-5,"login_name":12,"nick_name":12,"passwd":12,"name":12,"phone_num":12,"email":12,"head_img":12,"user_level":12,"birthday":91,"gender":12,"create_time":93,"operate_time":93,"status":12},"table":"user_info","ts":1689151633697,"type":"UPDATE"}- 从一个Kafka主题同步到Paimon表
/opt/module/flink-1.20.2/bin/flink run \
/opt/module/flink-1.20.2/lib/paimon-flink-action-1.2.0.jar \
kafka-sync-table \
--warehouse hdfs://node01:8020/hive/warehouse \
--database test \
--table user_info_cdc \
--primary-keys id \
--kafka-conf properties.bootstrap.servers=node01:9092 \
--kafka-conf topic=paimon_canal \
--kafka-conf properties.group.id=g1 \
--kafka-conf scan.startup.mode=earliest-offset \
--kafka-conf value.format=canal-json \
--catalog-conf metastore=hive \
--catalog-conf uri=thrift://node02:9083 \
--table-conf bucket=4 \
--table-conf changelog-producer=input \
--table-conf sink.parallelism=4- 查看自动创建的表和数据:
Flink SQL> use catalog hive_catalog;
[INFO] Execute statement succeeded.
Flink SQL> use test;
[INFO] Execute statement succeeded.
Flink SQL> show tables;
+-------------------+
| table name |
+-------------------+
| dm_source_tbl_cdc |
| user_info_cdc |
+-------------------+
2 rows in set
Flink SQL> desc user_info_cdc;
+--------------+--------------+-------+---------+--------+-----------+
| name | type | null | key | extras | watermark |
+--------------+--------------+-------+---------+--------+-----------+
| id | BIGINT | FALSE | PRI(id) | | |
| login_name | VARCHAR(200) | TRUE | | | |
| nick_name | VARCHAR(200) | TRUE | | | |
| passwd | VARCHAR(200) | TRUE | | | |
| name | VARCHAR(200) | TRUE | | | |
| phone_num | VARCHAR(200) | TRUE | | | |
| email | VARCHAR(200) | TRUE | | | |
| head_img | VARCHAR(200) | TRUE | | | |
| user_level | VARCHAR(200) | TRUE | | | |
| birthday | DATE | TRUE | | | |
| gender | VARCHAR(1) | TRUE | | | |
| create_time | TIMESTAMP(0) | TRUE | | | |
| operate_time | TIMESTAMP(0) | TRUE | | | |
| status | VARCHAR(200) | TRUE | | | |
+--------------+--------------+-------+---------+--------+-----------+
14 rows in set
Flink SQL> select * from user_info_cdc;
+----+----------------------+--------------------------------+-------------------------------+--------------------------------+--------------------------------+-------------------------------+--------------------------------+--------------------------------+--------------------------------+-----------+--------------------------------+---------------------+---------------------+--------------------------------+
| op | id | login_name | nick_name | passwd | name | phone_num | email | head_img | user_level | birthday | gender | create_time | operate_time | status |
+----+----------------------+--------------------------------+-------------------------------+--------------------------------+--------------------------------+-------------------------------+--------------------------------+--------------------------------+--------------------------------+-----------+--------------------------------+---------------------+---------------------+--------------------------------+
| +I | 6 | t7dk2h | 冰冰11 | <NULL> | 淳于冰 | 13178654378 | t7dk2h@263net | <NULL> | 1 | 1997-12-08 | <NULL> |2022-06-08 00:00:00 | <NULL> | <NULL> |
| +I | 8 | 02r2ahx | 卿卿33 | <NULL> | 穆卿 | 13412413361 | 02r2ahx@sohucom | <NULL> | 1 | 2001-07-08 | F |2022-06-08 00:00:00 | <NULL> | <NULL> |
| +I | 7 | vihcj30p1 | 豪心22 | <NULL> | 魏豪心 | 13956932645 | vihcj30p1@livecom | <NULL> | 1 | 1991-06-07 | M |2022-06-08 00:00:00 | <NULL> | <NULL> |
| +I | 9 | mjhrxnu | 武新44 | <NULL> | 罗武新 | 13617856358 | mjhrxnu@yahoocom | <NULL> | 1 | 2001-08-08 | <NULL> |2022-06-08 00:00:00 | <NULL> | <NULL> |2.4 同步数据库
- 语法说明
# 将多个主题或一个主题同步到一个 Paimon 数据库中。
<FLINK_HOME>/bin/flink run \
/path/to/paimon-flink-action-1.2.jar \
kafka-sync-database
--warehouse <warehouse-path> \
--database <database-name> \
[--schema-init-max-read <int>] \
[--ignore-incompatible <true/false>] \
[--table-prefix <paimon-table-prefix>] \
[--table-suffix <paimon-table-suffix>] \
[--including-tables <table-name|name-regular-expr>] \
[--excluding-tables <table-name|name-regular-expr>] \
[--kafka-conf <kafka-source-conf> [--kafka-conf <kafka-source-conf> ...]] \
[--catalog-conf <paimon-catalog-conf> [--catalog-conf <paimon-catalog-conf> ...]] \
[--table-conf <paimon-table-sink-conf> [--table-conf <paimon-table-sink-conf> ...]]参数说明:
| 配置 | 描述 |
|---|---|
| --warehouse | Paimon仓库路径。 |
| --database | Paimon Catalog中的数据库名称。 |
| --table-prefix | 所有需要同步的Paimon表的前缀。 例如所有同步表都以“ods_”作为前缀,则可以指定 --table-prefix ods_。 |
| --table-suffix | 所有需要同步的Paimon表的后缀。 用法与 --table-prefix相同。 |
| --including-tables | 用于指定要同步哪些源表。 您必须使用` |
| --excluding-tables | 用于指定哪些源表不同步。 用法与“--include-tables”相同。 如果同时指定了 --except-tables,则 --except-tables的优先级高于--include-tables。 |
| --kafka-conf | Flink Kafka源的配置。每个配置都应以key=value的格式指定。 properties.bootstrap.servers、topic、properties.group.id 和 value.format 是必需配置,其他配置是可选的。 |
| --catalog-conf | Paimon Catalog的配置。 每个配置都应以“key=value”的格式指定。 |
| --table-conf | Paimon表sink的配置。 每个配置都应以 key=value的格式指定。 |
只有具有主键的表才会被同步。对于每个要同步的Kafka主题的表,如果对应的Paimon表不存在,该操作将自动创建该表。它的schema将从所有指定的Kafka topic的表中派生出来,它从topic中获取最早的非DDL数据解析schema。如果 Paimon表已存在,则其schema将与所有指定 Kafka 主题表的schema进行比较。
2.5 案例实操
- 准备数据
#准备数据(canal-json格式),为了方便,省去canal解析生产数据过程,直接将canal格式的user_info和spu_info表数据插入topic里
[jack@Node01 kafka-3.9.1]$ ./bin/kafka-console-producer.sh --broker-list 192.168.7.201:9092 --topic paimon_canal_2
#插入数据如下(注意不要有空行):
{"data":[{"id":"6","login_name":"t7dk2h","nick_name":"冰冰11","passwd":null,"name":"淳于冰","phone_num":"13178654378","email":"t7dk2h@263.net","head_img":null,"user_level":"1","birthday":"1997-12-08","gender":null,"create_time":"2022-06-08 00:00:00","operate_time":null,"status":null}],"database":"gmall","es":1689150607000,"id":1,"isDdl":false,"mysqlType":{"id":"bigint","login_name":"varchar(200)","nick_name":"varchar(200)","passwd":"varchar(200)","name":"varchar(200)","phone_num":"varchar(200)","email":"varchar(200)","head_img":"varchar(200)","user_level":"varchar(200)","birthday":"date","gender":"varchar(1)","create_time":"datetime","operate_time":"datetime","status":"varchar(200)"},"old":[{"nick_name":"冰冰"}],"pkNames":["id"],"sql":"","sqlType":{"id":-5,"login_name":12,"nick_name":12,"passwd":12,"name":12,"phone_num":12,"email":12,"head_img":12,"user_level":12,"birthday":91,"gender":12,"create_time":93,"operate_time":93,"status":12},"table":"user_info","ts":1689151566836,"type":"UPDATE"}
{"data":[{"id":"7","login_name":"vihcj30p1","nick_name":"豪心22","passwd":null,"name":"魏豪心","phone_num":"13956932645","email":"vihcj30p1@live.com","head_img":null,"user_level":"1","birthday":"1991-06-07","gender":"M","create_time":"2022-06-08 00:00:00","operate_time":null,"status":null}],"database":"gmall","es":1689151623000,"id":2,"isDdl":false,"mysqlType":{"id":"bigint","login_name":"varchar(200)","nick_name":"varchar(200)","passwd":"varchar(200)","name":"varchar(200)","phone_num":"varchar(200)","email":"varchar(200)","head_img":"varchar(200)","user_level":"varchar(200)","birthday":"date","gender":"varchar(1)","create_time":"datetime","operate_time":"datetime","status":"varchar(200)"},"old":[{"nick_name":"豪心"}],"pkNames":["id"],"sql":"","sqlType":{"id":-5,"login_name":12,"nick_name":12,"passwd":12,"name":12,"phone_num":12,"email":12,"head_img":12,"user_level":12,"birthday":91,"gender":12,"create_time":93,"operate_time":93,"status":12},"table":"user_info","ts":1689151623139,"type":"UPDATE"}
{"data":[{"id":"8","login_name":"02r2ahx","nick_name":"卿卿33","passwd":null,"name":"穆卿","phone_num":"13412413361","email":"02r2ahx@sohu.com","head_img":null,"user_level":"1","birthday":"2001-07-08","gender":"F","create_time":"2022-06-08 00:00:00","operate_time":null,"status":null}],"database":"gmall","es":1689151626000,"id":3,"isDdl":false,"mysqlType":{"id":"bigint","login_name":"varchar(200)","nick_name":"varchar(200)","passwd":"varchar(200)","name":"varchar(200)","phone_num":"varchar(200)","email":"varchar(200)","head_img":"varchar(200)","user_level":"varchar(200)","birthday":"date","gender":"varchar(1)","create_time":"datetime","operate_time":"datetime","status":"varchar(200)"},"old":[{"nick_name":"卿卿"}],"pkNames":["id"],"sql":"","sqlType":{"id":-5,"login_name":12,"nick_name":12,"passwd":12,"name":12,"phone_num":12,"email":12,"head_img":12,"user_level":12,"birthday":91,"gender":12,"create_time":93,"operate_time":93,"status":12},"table":"user_info","ts":1689151626863,"type":"UPDATE"}
{"data":[{"id":"9","login_name":"mjhrxnu","nick_name":"武新44","passwd":null,"name":"罗武新","phone_num":"13617856358","email":"mjhrxnu@yahoo.com","head_img":null,"user_level":"1","birthday":"2001-08-08","gender":null,"create_time":"2022-06-08 00:00:00","operate_time":null,"status":null}],"database":"gmall","es":1689151630000,"id":4,"isDdl":false,"mysqlType":{"id":"bigint","login_name":"varchar(200)","nick_name":"varchar(200)","passwd":"varchar(200)","name":"varchar(200)","phone_num":"varchar(200)","email":"varchar(200)","head_img":"varchar(200)","user_level":"varchar(200)","birthday":"date","gender":"varchar(1)","create_time":"datetime","operate_time":"datetime","status":"varchar(200)"},"old":[{"nick_name":"武新"}],"pkNames":["id"],"sql":"","sqlType":{"id":-5,"login_name":12,"nick_name":12,"passwd":12,"name":12,"phone_num":12,"email":12,"head_img":12,"user_level":12,"birthday":91,"gender":12,"create_time":93,"operate_time":93,"status":12},"table":"user_info","ts":1689151630781,"type":"UPDATE"}
{"data":[{"id":"10","login_name":"kwua2155","nick_name":"纨纨55","passwd":null,"name":"姜纨","phone_num":"13742843828","email":"kwua2155@163.net","head_img":null,"user_level":"3","birthday":"1997-11-08","gender":"F","create_time":"2022-06-08 00:00:00","operate_time":null,"status":null}],"database":"gmall","es":1689151633000,"id":5,"isDdl":false,"mysqlType":{"id":"bigint","login_name":"varchar(200)","nick_name":"varchar(200)","passwd":"varchar(200)","name":"varchar(200)","phone_num":"varchar(200)","email":"varchar(200)","head_img":"varchar(200)","user_level":"varchar(200)","birthday":"date","gender":"varchar(1)","create_time":"datetime","operate_time":"datetime","status":"varchar(200)"},"old":[{"nick_name":"纨纨"}],"pkNames":["id"],"sql":"","sqlType":{"id":-5,"login_name":12,"nick_name":12,"passwd":12,"name":12,"phone_num":12,"email":12,"head_img":12,"user_level":12,"birthday":91,"gender":12,"create_time":93,"operate_time":93,"status":12},"table":"user_info","ts":1689151633697,"type":"UPDATE"}
{"data":[{"id":"12","spu_name":"华为智慧屏 4K全面屏智能电视机1","description":"华为智慧屏 4K全面屏智能电视机","category3_id":"86","tm_id":"3","create_time":"2021-12-14 00:00:00","operate_time":null}],"database":"gmall","es":1689151648000,"id":6,"isDdl":false,"mysqlType":{"id":"bigint","spu_name":"varchar(200)","description":"varchar(1000)","category3_id":"bigint","tm_id":"bigint","create_time":"datetime","operate_time":"datetime"},"old":[{"spu_name":"华为智慧屏 4K全面屏智能电视机"}],"pkNames":["id"],"sql":"","sqlType":{"id":-5,"spu_name":12,"description":12,"category3_id":-5,"tm_id":-5,"create_time":93,"operate_time":93},"table":"spu_info","ts":1689151648872,"type":"UPDATE"}
{"data":[{"id":"3","spu_name":"Apple iPhone 13","description":"Apple iPhone 13","category3_id":"61","tm_id":"2","create_time":"2021-12-14 00:00:00","operate_time":null}],"database":"gmall","es":1689151661000,"id":7,"isDdl":false,"mysqlType":{"id":"bigint","spu_name":"varchar(200)","description":"varchar(1000)","category3_id":"bigint","tm_id":"bigint","create_time":"datetime","operate_time":"datetime"},"old":[{"spu_name":"Apple iPhone 12","description":"Apple iPhone 12"}],"pkNames":["id"],"sql":"","sqlType":{"id":-5,"spu_name":12,"description":12,"category3_id":-5,"tm_id":-5,"create_time":93,"operate_time":93},"table":"spu_info","ts":1689151661828,"type":"UPDATE"}
{"data":[{"id":"4","spu_name":"HUAWEI P50","description":"HUAWEI P50","category3_id":"61","tm_id":"3","create_time":"2021-12-14 00:00:00","operate_time":null}],"database":"gmall","es":1689151669000,"id":8,"isDdl":false,"mysqlType":{"id":"bigint","spu_name":"varchar(200)","description":"varchar(1000)","category3_id":"bigint","tm_id":"bigint","create_time":"datetime","operate_time":"datetime"},"old":[{"spu_name":"HUAWEI P40","description":"HUAWEI P40"}],"pkNames":["id"],"sql":"","sqlType":{"id":-5,"spu_name":12,"description":12,"category3_id":-5,"tm_id":-5,"create_time":93,"operate_time":93},"table":"spu_info","ts":1689151669966,"type":"UPDATE"}
{"data":[{"id":"1","spu_name":"小米12sultra","description":"小米12","category3_id":"61","tm_id":"1","create_time":"2021-12-14 00:00:00","operate_time":null}],"database":"gmall","es":1689151700000,"id":9,"isDdl":false,"mysqlType":{"id":"bigint","spu_name":"varchar(200)","description":"varchar(1000)","category3_id":"bigint","tm_id":"bigint","create_time":"datetime","operate_time":"datetime"},"old":[{"description":"小米10"}],"pkNames":["id"],"sql":"","sqlType":{"id":-5,"spu_name":12,"description":12,"category3_id":-5,"tm_id":-5,"create_time":93,"operate_time":93},"table":"spu_info","ts":1689151700998,"type":"UPDATE"}- 再准备一个只包含spu_info单表数据写入到之前的Topic:paimon_canal_1中
[jack@Node01 kafka-3.9.1]$ ./bin/kafka-console-producer.sh --broker-list 192.168.7.201:9092 --topic paimon_canal_1
{"data":[{"id":"12","spu_name":"华为智慧屏 4K全面屏智能电视机1","description":"华为智慧屏 4K全面屏智能电视机","category3_id":"86","tm_id":"3","create_time":"2021-12-14 00:00:00","operate_time":null}],"database":"gmall","es":1689151648000,"id":6,"isDdl":false,"mysqlType":{"id":"bigint","spu_name":"varchar(200)","description":"varchar(1000)","category3_id":"bigint","tm_id":"bigint","create_time":"datetime","operate_time":"datetime"},"old":[{"spu_name":"华为智慧屏 4K全面屏智能电视机"}],"pkNames":["id"],"sql":"","sqlType":{"id":-5,"spu_name":12,"description":12,"category3_id":-5,"tm_id":-5,"create_time":93,"operate_time":93},"table":"spu_info","ts":1689151648872,"type":"UPDATE"}
{"data":[{"id":"3","spu_name":"Apple iPhone 13","description":"Apple iPhone 13","category3_id":"61","tm_id":"2","create_time":"2021-12-14 00:00:00","operate_time":null}],"database":"gmall","es":1689151661000,"id":7,"isDdl":false,"mysqlType":{"id":"bigint","spu_name":"varchar(200)","description":"varchar(1000)","category3_id":"bigint","tm_id":"bigint","create_time":"datetime","operate_time":"datetime"},"old":[{"spu_name":"Apple iPhone 12","description":"Apple iPhone 12"}],"pkNames":["id"],"sql":"","sqlType":{"id":-5,"spu_name":12,"description":12,"category3_id":-5,"tm_id":-5,"create_time":93,"operate_time":93},"table":"spu_info","ts":1689151661828,"type":"UPDATE"}
{"data":[{"id":"4","spu_name":"HUAWEI P50","description":"HUAWEI P50","category3_id":"61","tm_id":"3","create_time":"2021-12-14 00:00:00","operate_time":null}],"database":"gmall","es":1689151669000,"id":8,"isDdl":false,"mysqlType":{"id":"bigint","spu_name":"varchar(200)","description":"varchar(1000)","category3_id":"bigint","tm_id":"bigint","create_time":"datetime","operate_time":"datetime"},"old":[{"spu_name":"HUAWEI P40","description":"HUAWEI P40"}],"pkNames":["id"],"sql":"","sqlType":{"id":-5,"spu_name":12,"description":12,"category3_id":-5,"tm_id":-5,"create_time":93,"operate_time":93},"table":"spu_info","ts":1689151669966,"type":"UPDATE"}
{"data":[{"id":"1","spu_name":"小米12sultra","description":"小米12","category3_id":"61","tm_id":"1","create_time":"2021-12-14 00:00:00","operate_time":null}],"database":"gmall","es":1689151700000,"id":9,"isDdl":false,"mysqlType":{"id":"bigint","spu_name":"varchar(200)","description":"varchar(1000)","category3_id":"bigint","tm_id":"bigint","create_time":"datetime","operate_time":"datetime"},"old":[{"description":"小米10"}],"pkNames":["id"],"sql":"","sqlType":{"id":-5,"spu_name":12,"description":12,"category3_id":-5,"tm_id":-5,"create_time":93,"operate_time":93},"table":"spu_info","ts":1689151700998,"type":"UPDATE"}- 从一个Kafka主题(包含多表数据)同步到Paimon数据库
/opt/module/flink-1.20.2/bin/flink run \
/opt/module/flink-1.20.2/lib/paimon-flink-action-1.2.0.jar \
kafka-sync-database \
--warehouse hdfs://node01:8020/hive/warehouse \
--database test \
--table-prefix "t1_" \
--table-suffix "_cdc" \
--kafka-conf properties.bootstrap.servers=node01:9092 \
--kafka-conf topic=paimon_canal_2 \
--kafka-conf properties.group.id=jack \
--kafka-conf scan.startup.mode=earliest-offset \
--kafka-conf value.format=canal-json \
--catalog-conf metastore=hive \
--catalog-conf uri=thrift://node02:9083 \
--table-conf bucket=4 \
--table-conf changelog-producer=input \
--table-conf sink.parallelism=4可以登录Flink任务管控页面: 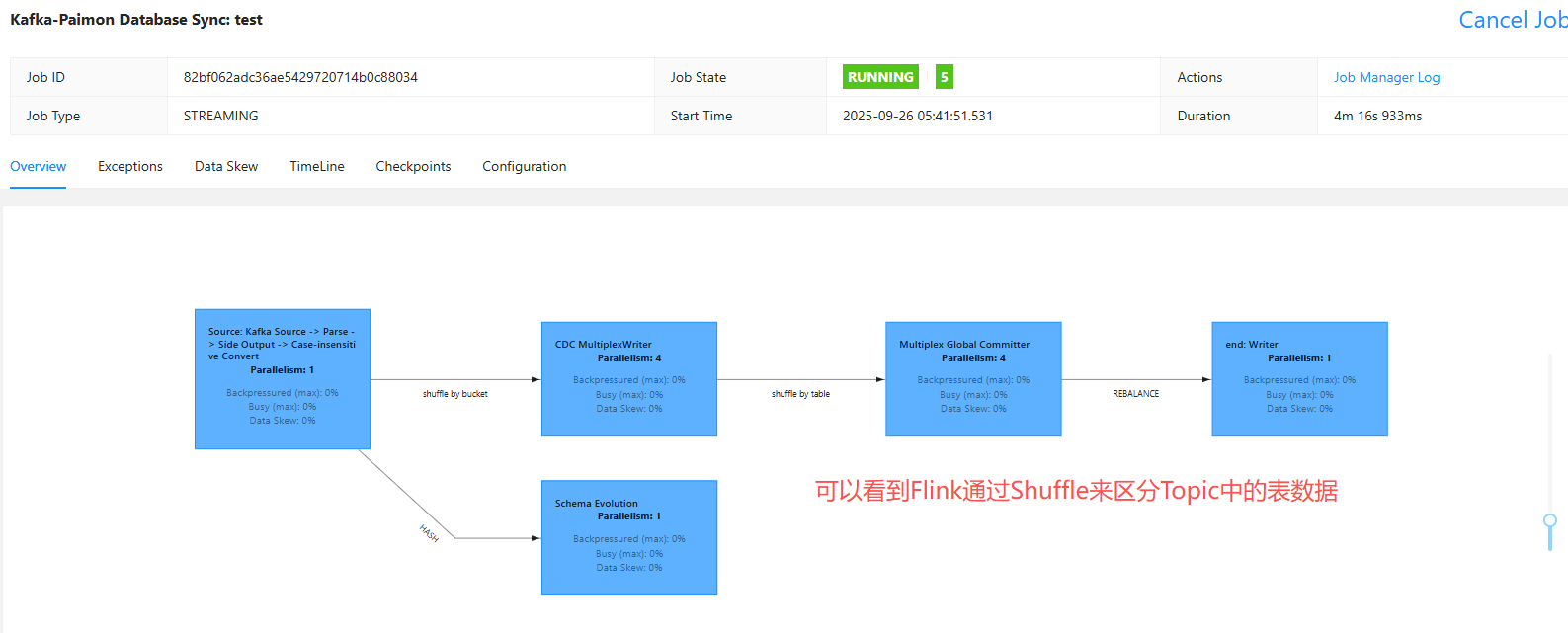
Flink SQL> select * from t1_spu_info_cdc;
+----+----------------------+--------------------------------+--------------------------------+----------------------+----------------------+---------------------+---------------------+
| op | id | spu_name | description | category3_id | tm_id | create_time | operate_time |
+----+----------------------+--------------------------------+--------------------------------+----------------------+----------------------+---------------------+---------------------+
| +I | 3 | Apple iPhone 13 | Apple iPhone 13 | 61 | 2 | 2021-12-14 00:00:00 | <NULL> |
| +I | 12 | 华为智慧屏 4K全面屏智能电视机1 | 华为智慧屏 4K全面屏智能电视机 | 86 | 3 | 2021-12-14 00:00:00 | <NULL> |
| +I | 4 | HUAWEI P50 | HUAWEI P50 | 61 | 3 | 2021-12-14 00:00:00 | <NULL> |- 从多个Kafka主题同步到Paimon数据库
## 多个主题使用分号;隔开
/opt/module/flink-1.20.2/bin/flink run \
/opt/module/flink-1.20.2/lib/paimon-flink-action-1.2.0.jar \
kafka-sync-database \
--warehouse hdfs://node01:8020/paimon/hive \
--database test \
--table-prefix "t2_" \
--table-suffix "_cdc" \
--kafka-conf properties.bootstrap.servers=node01:9092 \
--kafka-conf topic=paimon_canal_1\;paimon_canal_2 \
--kafka-conf properties.group.id=jack \
--kafka-conf scan.startup.mode=earliest-offset \
--kafka-conf value.format=canal-json \
--catalog-conf metastore=hive \
--catalog-conf uri=thrift://node02:9083 \
--table-conf bucket=4 \
--table-conf changelog-producer=input \
--table-conf sink.parallelism=4Paimon会自动正确的合并和拆分里面的CDC数据,发现t2相关的表已经创建:
Flink SQL> show tables;
+-------------------+
| table name |
+-------------------+
| dm_source_tbl_cdc |
| t1_spu_info_cdc |
| t1_user_info_cdc |
| t2_spu_info_cdc |
| t2_user_info_cdc |
| user_info_cdc |
+-------------------+
6 rows in set
Flink SQL> select * from t2_spu_info_cdc;
+----+----------------------+--------------------------------+--------------------------------+----------------------+----------------------+---------------------+---------------------+
| op | id | spu_name | description | category3_id | tm_id | create_time | operate_time |
+----+----------------------+--------------------------------+--------------------------------+----------------------+----------------------+---------------------+---------------------+
| +I | 3 | Apple iPhone 13 | Apple iPhone 13 | 61 | 2 | 2021-12-14 00:00:00 | <NULL> |
| +I | 12 | 华为智慧屏 4K全面屏智能电视机1 | 华为智慧屏 4K全面屏智能电视机 | 86 | 3 | 2021-12-14 00:00:00 | <NULL> |
| +I | 4 | HUAWEI P50 | HUAWEI P50 | 61 | 3 | 2021-12-14 00:00:00 | <NULL> |3. 支持schema变更
cdc集成支持有限的schema变更。目前,Paimon不支持表名变更、删除字段,而当前支持的schema变更有:
- 添加字段
- 有限制的更改列类型:
- 字符类型更改为范围更大的字符串类型
- 非字符串类型更改为字符串类型
- 数值类型更改为范围更大的数值类型
- 二进制类型更改为更大的二进制类型(比如binary, varbinary, blob)
- 浮点型更改为更大的浮点类型
3.1 案例实操
- 将Mysql中的表dm_source_tbl集成到Paimon中:
bin/flink run \
/opt/module/flink-1.20.2/lib/paimon-flink-action-1.2.0.jar \
mysql-sync-table \
--warehouse hdfs://node01:8020/hive/warehouse/ \
--database test \
--table dm_source_tbl_cdc \
--primary-keys id \
--mysql-conf hostname=192.168.7.203 \
--mysql-conf username=root \
--mysql-conf password=123456 \
--mysql-conf database-name=dm \
--mysql-conf table-name='dm_source_tbl' \
--mysql-conf jdbc.properties.useSSL=false \
--mysql-conf jdbc.properties.useUnicode=true \
--mysql-conf jdbc.properties.characterEncoding=utf8 \
--catalog-conf metastore=hive \
--catalog-conf uri=thrift://node02:9083 \
--table-conf bucket=4 \
--table-conf changelog-producer=input \
--table-conf sink.parallelism=4执行后查询Paimon中dm_source_tbl_cdc的表结构:
Flink SQL> desc dm_source_tbl_cdc;
+-------------+--------------+-------+---------+--------+-----------+---------+
| name | type | null | key | extras | watermark | comment |
+-------------+--------------+-------+---------+--------+-----------+---------+
| id | BIGINT | FALSE | PRI(id) | | | 主键 |
| tbl_name | VARCHAR(50) | FALSE | | | | 表名 |
| tbl_comment | VARCHAR(500) | TRUE | | | | 注释 |
| tbl_remark | VARCHAR(300) | TRUE | | | | 备注 |
+-------------+--------------+-------+---------+--------+-----------+---------+
4 rows in set修改Mysql中的表dm_source_tbl,添加字段aaa: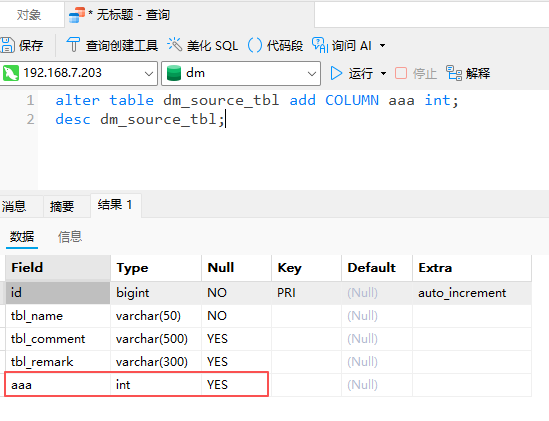 添加后再次查看Paimon中的dm_source_tbl_cdc表结构:
添加后再次查看Paimon中的dm_source_tbl_cdc表结构:
Flink SQL> desc dm_source_tbl_cdc;
+-------------+--------------+-------+---------+--------+-----------+---------+
| name | type | null | key | extras | watermark | comment |
+-------------+--------------+-------+---------+--------+-----------+---------+
| id | BIGINT | FALSE | PRI(id) | | | 主键 |
| tbl_name | VARCHAR(50) | FALSE | | | | 表名 |
| tbl_comment | VARCHAR(500) | TRUE | | | | 注释 |
| tbl_remark | VARCHAR(300) | TRUE | | | | 备注 |
| aaa | INT | TRUE | | | | |
+-------------+--------------+-------+---------+--------+-----------+---------+
5 rows in set但是需要注意的是如果正在执行flinksql是不会感知到新加的字段的,还是需要重启flinksql任务才能生效。