Raft算法
1. 诞生背景
1.1 共识算法分类
从解决的问题类型来看,共识算法分成两种,分别是拜占庭容错算法(Byzantine Fault Tolerance, BFT)与故障容错算法(Crash Fault Tolerance, CFT)。 拜占庭容错算法主要在解决如果有节点作恶的情况下,如何同步集群的状态,常见的拜占庭容错算法有PBFT;
故障容错算法主要都在处理节点故障或是遇到 网络问题 时,如何让整个集群的状态维持一致,常见的故障容错算法有ZAB 、 Raft等等。
提示
虽然拜占庭问题 (Byzantine Generals’ Problem)跟拜占庭容错算法PBFT被提出的时间都相当早,但可以说是到了区块链出现,才找到大规模的应用场景,而大部分企业内部应用的,还是属于故障容错算法。
1.2 Raft算法历史
Raft是2013年Diego Ongaro在Stanford博士论文中提出的。随后在etcd、 InfluxDB、2014年的Consul 、 IPFS以及 2015年的CockroachDB等等被广泛采用。
2. 重要概念
2.1 角色
在一个由Raft协议组织的集群中有三类角色(状态):
- 领导者(Leader)
- 候选人(Candidate)
- 跟随者(Follower)
一个Raft集群中只能存在一个领导者。
2.2 任期(Term)
任期用于Leader, 选出Leader后就开始了这届Leader的任期,一个任期内至多只会有一个领导者,只要领导者在,才能对外提供服务。以下图为例,每个任期一开始都是领导者选举(深蓝色区间),后面是集群可以对外服务的时间(浅蓝色区间),每一个任期只有在领导者故障后,集群才会发起下一次的选举,所以每次任期的时间长度不固定,也有可能发生领导者选举失败的任期(如term3),代表该任期没有领导者,所以直接进行下一轮的领导者选举。 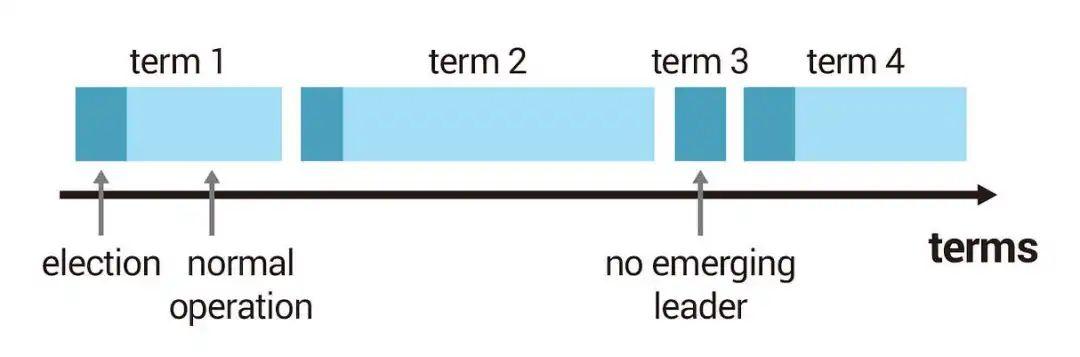
2.3 日志(Log)
日志由索引(Index)、任期(Term)及指令(Command)组成,索引一样是个严格递增的数字,任期在这里代表在哪个任期记录的日志,指令代表要做什么操作。以下图为例,红色框框圈起来的代表「日志索引4发生在任期2,指令是把x设定成2」。 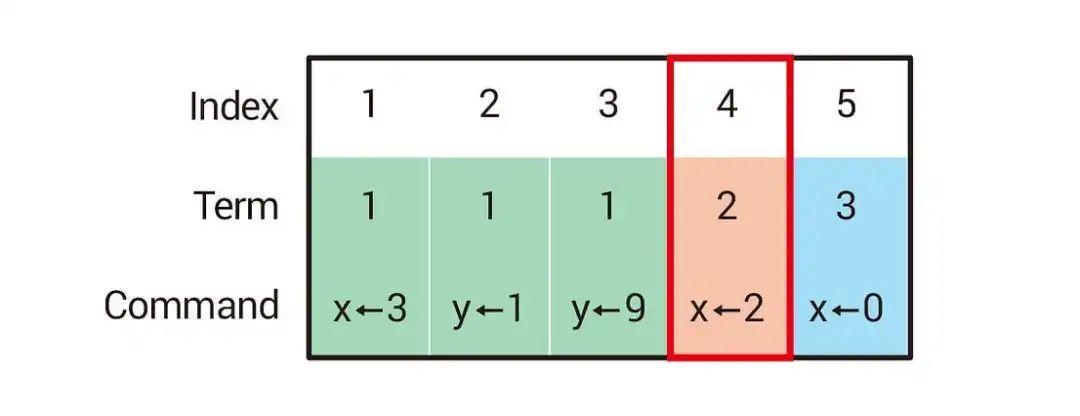
2.4 数据状态机(State Machine)
每个写入请求的最终步骤都是把结果保存到状态机里面,同时,读取请求也需要从这个状态机中提取数据以便响应; 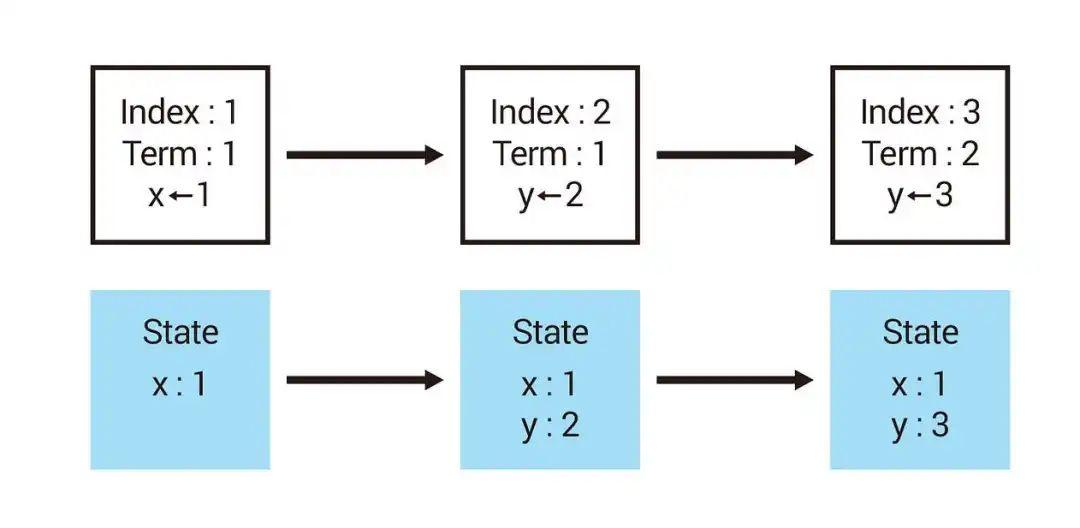 架构设计中出现状态机,主要考虑两阶段提交,写进日志是第一阶段,改变数据状态机是第二阶段,提高数据写入的可靠性。
架构设计中出现状态机,主要考虑两阶段提交,写进日志是第一阶段,改变数据状态机是第二阶段,提高数据写入的可靠性。
3. 领导者选举(Leader Election)
3.1 投票原则
任期高的不投给任期低,日志索引高的不投给日志索引低的节点,这点是为了确保 只有日志最完整的节点可以成为领导者。
若候选人满足上一点,节点会 优先投给最早发送投票请求的候选人。
每个节点在一个任期内,只能投一张票。
系统在初始状态下,所有node都是follower;
follower在没有监听到leader的时候,会变为candidate;
cadidate会向其它node发送投票请求,如果得票数过半就变为leader(candidate可以给自己投票);
选出Leader后,Leader通过定期向所有Follower发送心跳信息(Heart Beat)维持其统治;