DQL语句
DQL英文全称是Data Query Language(数据查询语言),数据查询语言,用来查询数据库中表的记录。
1. Select语法
SELECT
[ALL | DISTINCT | DISTINCTROW ]
[HIGH_PRIORITY]
[STRAIGHT_JOIN]
[SQL_SMALL_RESULT] [SQL_BIG_RESULT] [SQL_BUFFER_RESULT]
[SQL_NO_CACHE] [SQL_CALC_FOUND_ROWS]
select_expr [, select_expr] ...
[into_option]
[FROM table_references
[PARTITION partition_list]]
[WHERE where_condition]
[GROUP BY {col_name | expr | position}, ... [WITH ROLLUP]]
[HAVING where_condition]
[WINDOW window_name AS (window_spec)
[, window_name AS (window_spec)] ...]
[ORDER BY {col_name | expr | position}
[ASC | DESC], ... [WITH ROLLUP]]
[LIMIT {[offset,] row_count | row_count OFFSET offset}]
[into_option]
[FOR {UPDATE | SHARE}
[OF tbl_name [, tbl_name] ...]
[NOWAIT | SKIP LOCKED]
| LOCK IN SHARE MODE]
[into_option]其中into_option表示:
into_option: {
INTO OUTFILE 'file_name'
[CHARACTER SET charset_name]
[{FIELDS | COLUMNS}
[TERMINATED BY 'string']
[[OPTIONALLY] ENCLOSED BY 'char']
[ESCAPED BY 'char']
]
[LINES
[STARTING BY 'string']
[TERMINATED BY 'string']
]
| INTO DUMPFILE 'file_name'
| INTO var_name [, var_name] ...
}2. 基本查询
在基本查询的DQL语句中,不带任何的查询条件。
2.1 查询多个字段
mysql> select * from sku_attr_value limit 10;
+----+---------+----------+--------+---------------+--------------+---------------------+--------------+
| id | attr_id | value_id | sku_id | attr_name | value_name | create_time | operate_time |
+----+---------+----------+--------+---------------+--------------+---------------------+--------------+
| 1 | 106 | 176 | 1 | 手机一级1 | 安卓手机 | 2021-12-14 00:00:00 | NULL |
| 2 | 107 | 177 | 1 | 二级手机2 | 小米 | 2021-12-14 00:00:00 | NULL |
| 3 | 23 | 83 | 1 | 运行内存 | 8G | 2021-12-14 00:00:00 | NULL |
| 4 | 24 | 82 | 1 | 机身内存 | 128G | 2021-12-14 00:00:00 | NULL |
| 5 | 106 | 176 | 2 | 手机一级 | 安卓手机 | 2021-12-14 00:00:00 | NULL |
| 6 | 107 | 177 | 2 | 二级手机 | 小米 | 2021-12-14 00:00:00 | NULL |
| 7 | 23 | 83 | 2 | 运行内存 | 8G | 2021-12-14 00:00:00 | NULL |
| 8 | 24 | 166 | 2 | 机身内存 | 256G | 2021-12-14 00:00:00 | NULL |
| 9 | 106 | 176 | 3 | 手机一级 | 安卓手机 | 2021-12-14 00:00:00 | NULL |
| 10 | 107 | 177 | 3 | 二级手机 | 小米 | 2021-12-14 00:00:00 | NULL |
+----+---------+----------+--------+---------------+--------------+---------------------+--------------+
10 rows in set (0.00 sec)警告
*号代表查询所有字段,在实际开发中尽量少用(不直观、影响效率)。
2.2 字段设置别名
SELECT 字段1 [ AS ] 别名1 , 字段2 [ AS ] 别名2 ... FROM 表名;2.3 去除重复记录
SELECT DISTINCT 字段列表 FROM 表名;3. 条件查询
3.1 比较运算符
| 比较运算符 | 功能 |
|---|---|
| > | 大于 |
| >= | 大于等于 |
| < | 小于 |
| <= | 小于等于 |
| = | 等于 |
| <> 或 != | 不等于 |
| BETWEEN ... AND ... | 在某个范围之内(含最小、最大值) |
| IN(...) | 在in之后的列表中的值,多选一 |
| LIKE 占位符 | 模糊匹配 (_匹配单个字符, %匹配任意个字符) |
| IS NULL | 是NULL |
3.2 逻辑运算符
常用的逻辑运算符如下:
| 逻辑运算符 | 功能 |
|---|---|
| and或&& | 并且 (多个条件同时成立) |
| or或|| | 或者 (多个条件任意一个成立) |
| not或! | 非 , 不是 |
-- 查询年龄在15岁(包含) 到 20岁(包含)之间的员工信息
select * from emp where age >= 15 && age <= 20;
select * from emp where age >= 15 and age <= 20;
select * from emp where age between 15 and 20;查询身份证号最后一位是X的员工信息:
select * from emp where idcard like '%X';
select * from emp where idcard like '_________________X';4. 排序查询
排序方式:
- ASC : 升序(默认值);
- DESC: 降序。
如果是升序, 可以不指定排序方式ASC;
如果是多字段排序,当第一个字段值相同时,才会根据第二个字段进行排序;
## gmall_v4.user_info有3737933条记录
mysql> SELECT * FROM gmall_v4.user_info order by user_level desc limit 100 ;发现查询比较慢,如果不能利用索引,可以调整排序的内存大小来优化:
## 查询当前排序的状态,Sort_merge_passes表示磁盘排完序到内存中合并的次数是1203
mysql> show status like 'sort%';
+-------------------+-------+
| Variable_name | Value |
+-------------------+-------+
| Sort_merge_passes | 1203 |
| Sort_range | 0 |
| Sort_rows | 100 |
| Sort_scan | 1 |
+-------------------+-------+
4 rows in set (0.00 sec)
## 默认的排序内存大小是256K, 它支持会话级别参数设置
mysql> show variables like 'sort_buffer_size';
+------------------+--------+
| Variable_name | Value |
+------------------+--------+
| sort_buffer_size | 262144 |
+------------------+--------+
1 row in set (0.01 sec)
## 调整为256M
mysql> set sort_buffer_size=256*1024*1024;
## 清空状态记录
mysql> flush status;
mysql> SELECT * FROM gmall_v4.user_info order by user_level desc limit 100;
## 查询状态,发现排序merge的次数为0,说明直接内存中排完了序
mysql> show status like 'sort%';
+-------------------+-------+
| Variable_name | Value |
+-------------------+-------+
| Sort_merge_passes | 0 |
| Sort_range | 0 |
| Sort_rows | 100 |
| Sort_scan | 1 |
+-------------------+-------+
4 rows in set (0.00 sec)另外也可以通过show global status like 'sort%'了解配置的sort_buffer_size是否合理。
5. 分组查询
5.1 使用聚合函数
mysql> SELECT date_format(create_time, '%Y%m') , count(*)
FROM user_info
GROUP BY date_format(create_time, '%Y%m') ;
## 查询当前的临时表内存大小
mysql> show variables like '%tmp_table_size%';
+----------------+----------+
| Variable_name | Value |
+----------------+----------+
| tmp_table_size | 16777216 |
+----------------+----------+
1 row in set (0.00 sec)如果查询的表的时候用到临时表特别大的话,可以考虑调整tmp_table_size变量。设置的多少可以参考下面sql:
mysql> show global status like '%tmp%';
+-------------------------+-------+
| Variable_name | Value |
+-------------------------+-------+
| Created_tmp_disk_tables | 5 |
| Created_tmp_files | 0 |
| Created_tmp_tables | 116 |
+-------------------------+-------+
3 rows in set (0.04 sec)最大的话是不能超过innodb_buffer_pool_size的(默认128M),它表示整个数据库使用的内存总大小。
5.2 查询数据行数
其中count(1)、count(2)、count(100)、...到count(*)都是一样的,表示查询总行数,如果count(列名)表示查询该列非Null值的行数: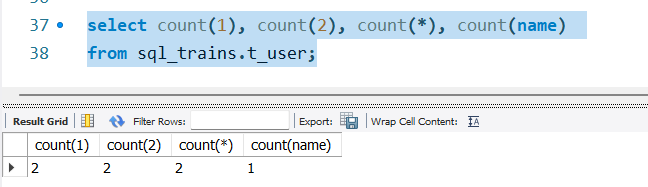 其实底层就是:
其实底层就是:
mysql> select 1 from sql_trains.t_user;
+---+
| 1 |
+---+
| 1 |
| 1 |
+---+
2 rows in set (0.00 sec)可以当前结果集中列名就是1,所以count(1)就是指明统计当前列为1的总行数。
5.3 分组查询前3
在mysql8.0之后支持窗口函数。
select rn, title from (
SELECT row_number() over (partition by release_year, rating order by last_update desc) rn,
title
FROM sakila.film
) a where rn<=35.4 使用having过滤
过滤所用的字段需要在select中出现,不论是字段还是表达式:
mysql> select sum(replacement_cost), release_year from sakila.film
-> group by release_year having release_year<2024;
+-----------------------+--------------+
| sum(replacement_cost) | release_year |
+-----------------------+--------------+
| 19984.00 | 2006 |
+-----------------------+--------------+
1 row in set (0.01 sec)为何会严格要求having后的字段必须出现在select中呢,因为having的过滤条件是基于select查询后的分组的结构集进行处理的,而select后的字段是和group保持一致的。在mysql5.6中允许having不限制字段,但查询出来的值是毫无意义的,这一列的值不是分组后的第一行的值,而是随机值。在mysql5.7之后都是不允许直接在select或者having中使用没有在group出现的字段,mysql中通过使用sql_mode来进行控制group行为:
mysql> show variables like '%sql_mode%';
+---------------+-----------------------------------------------------------------------------------------------------------------------+
| Variable_name | Value |
+---------------+-----------------------------------------------------------------------------------------------------------------------+
| sql_mode | ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION |
+---------------+-----------------------------------------------------------------------------------------------------------------------+
1 row in set, 1 warning (0.01 sec)可以看到在mysql8.4中使用的是严格模式。
where与having区别
执行时机不同:where是分组之前进行过滤,不满足where条件,不参与分组;而having是分组之后对结果进行过滤。
判断条件不同:where不能对聚合函数进行判断,而having可以。
5.3 分组全部显示
select
address_id,
group_concat(first_name order by first_name separator ',')
from customer
group by address_id使用group_concat支持自定义字段排序。
6. 分页查询
使用limit关键字查询结果:
select * from employees
order by birth_date, emp_no limit 30;但是对于分页靠后查询会很慢:
select * from employees
order by birth_date, emp_no limit 4000000, 30;
-- 优化办法
alter table employees add index idx_birth_data(birth_date, emp_no);
select * from employees
-- ('1905-01-03', 2174487)表示3999999处的数据,利用索引比较
where (birth_date, emp_no)>('1905-01-03', 2174487)
order by birth_date, emp_no limit 30;上述解决办法的缺点就是不支持页面跳转。可以预估页面一般显示几页,然后将数据比如前1000条返回给前端,前端内存分页。
提示
- 起始索引从0开始,起始索引 = (查询页码 - 1)* 每页显示记录数。
- 分页查询是数据库的方言,不同的数据库有不同的实现,MySQL中是LIMIT。
- 如果查询的是第一页数据,起始索引可以省略,直接简写为 limit 10。
7. 显示行号
在mysql8.0之前:
-- 关联子查询,性能较低
SELECT emp_no,
(SELECT
COUNT(1) FROM
employees t2 WHERE t2.emp_no <=tl.emp_no) As row_num
FROM employees t1 ORDER BY emp_no LIMIT 10;
-- 或者使用变量记录
set @rownum = 0;
select
@rownum := @rownum + 1 as rn1,
a.actor_id, first_name + '-' + last_name
from actor a;
-- 或者一条sql:
select
@rownum := @rownum + 1 as rn1,
a.actor_id, first_name + '-' + last_name
from actor a, (select @rownum := 0) b;在mysql8.0之后:
select
row_number() over (order by a.actor_id) rn,
a.actor_id, first_name + '-' + last_name
from actor a;8. Prepare SQL的使用
8.1 优势
- 每次执行语句时,解析开销更小。
- 防止SOL注入攻击。
- 动态搜索条件。
8.2 实操
- 防范sql注入
-- 通过sql的方式,还可以通过java代码实现
set @sql := 'select * from sql_trains.t_user where name=?';
set @param := 'jack';
prepare stmt from @sql;
execute stmt using @param;
deallocate prepare stmt;常见的sql注入:
select * from sql_trains.t_user where name='jack' or 1=1;- 动态查询
在where后面加上1=1方便拼装动态sql:
set @s := 'SELECT * FROM employees WHERE 1=1';
set @s := CONCAT(@s,' AND gender ="m"');
set @s := CONCAT(@s, ' AND birth_date >="1960-01-01"');
set @s := CONCAT(@s, ' ORDER BY emp_no LIMIT ?,?');
SET @page_no =0;
SET @page_count = 10;
PREPARE stmt FROM @s;
EXECUTE stmt USING @page_no, @page_count;
DEALLOCATE PREPARE stmt;9. 计算行的平均大小
使用show status只会得到一个预估的大小值,那么如何得到精确值呢?  首先查看sakila.country的字段类型:
首先查看sakila.country的字段类型: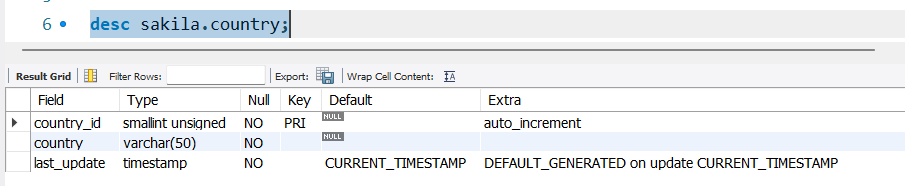 比如smallint占用2个字节,country字段为可变字符,使用
比如smallint占用2个字节,country字段为可变字符,使用length()函数计算(需要注意length()函数只支持字符串类型)
## 通过抽样的方法
mysql> select avg(row_length) from (
select 2+length(country)+4 row_length from sakila.country limit 100000
) a;
+-----------------+
| avg(row_length) |
+-----------------+
| 14.9541 |
+-----------------+
1 row in set (0.00 sec)10. SQL执行顺序

10.1 验证
我们可以给select后面的字段起别名,然后在where中使用这个别名,然后看看是否可以执行成功。
select e.name ename , e.age eage from emp e where eage > 15 order by age asc;执行上述SQL报错了: 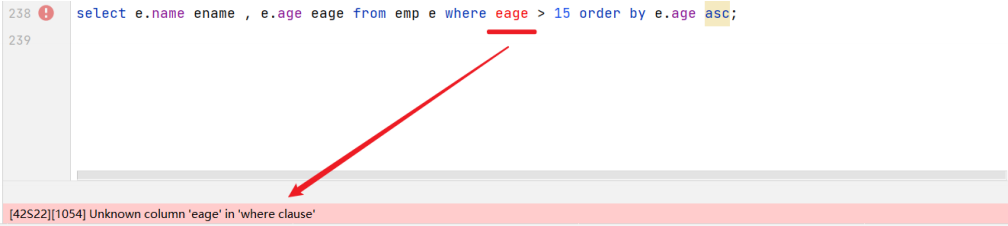 由此我们可以得出结论: from先执行,然后执行where,再执行select。
由此我们可以得出结论: from先执行,然后执行where,再执行select。