ConcurrentHashMap
1. ConcurrentHashMap的实现原理
1.1 JDK7之前版本
JDK7之前(包含JDK1.7),ConcurrentHashMap主要是通过分段锁(Segment Lock,ReentrantLock)来保证线程安全的。整个ConcurrentHashMap由一个个Segment组成, Segment类是线程安全的(Segment类继承ReentrantLock,具有加锁功能),通过继承ReentrantLock,使用ReentrantLock的lock()方法来实现加锁。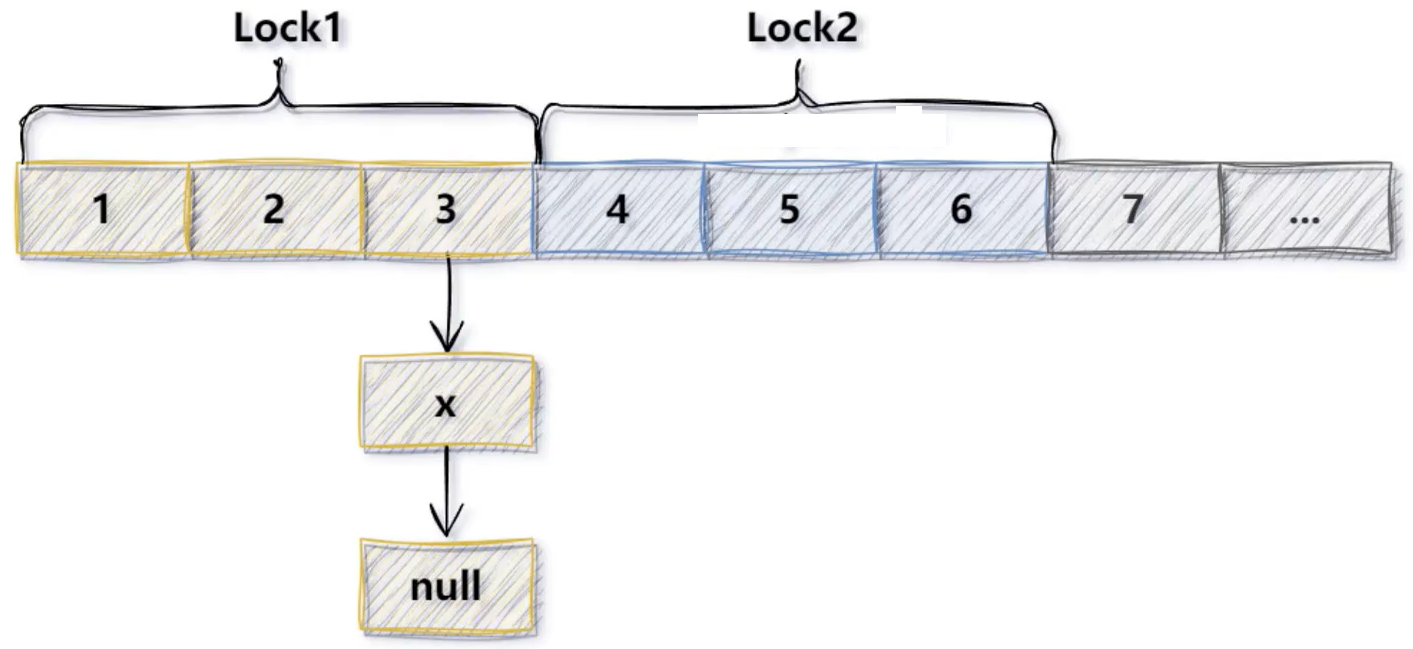
1.2 JDK8之后版本
在JDK8及以上的版本中,ConcurrentHashMap的底层数据结构依然采用"数组+链表+红黑树",但是在实现线程安全性方面,抛弃了JDK7版本的Segment分段锁的概念,使用了粒度更小的锁,采用了synchronized+CAS算法来保证线程安全。在数组头节点加锁来保证线程安全。在ConcurrentHashMap中,大量使用Unsafe.compareAndSwapXXX的方法,这类方法是利用一个CAS算法实现无锁化的修改值操作,可以大大减少使用加锁造成的性能消耗。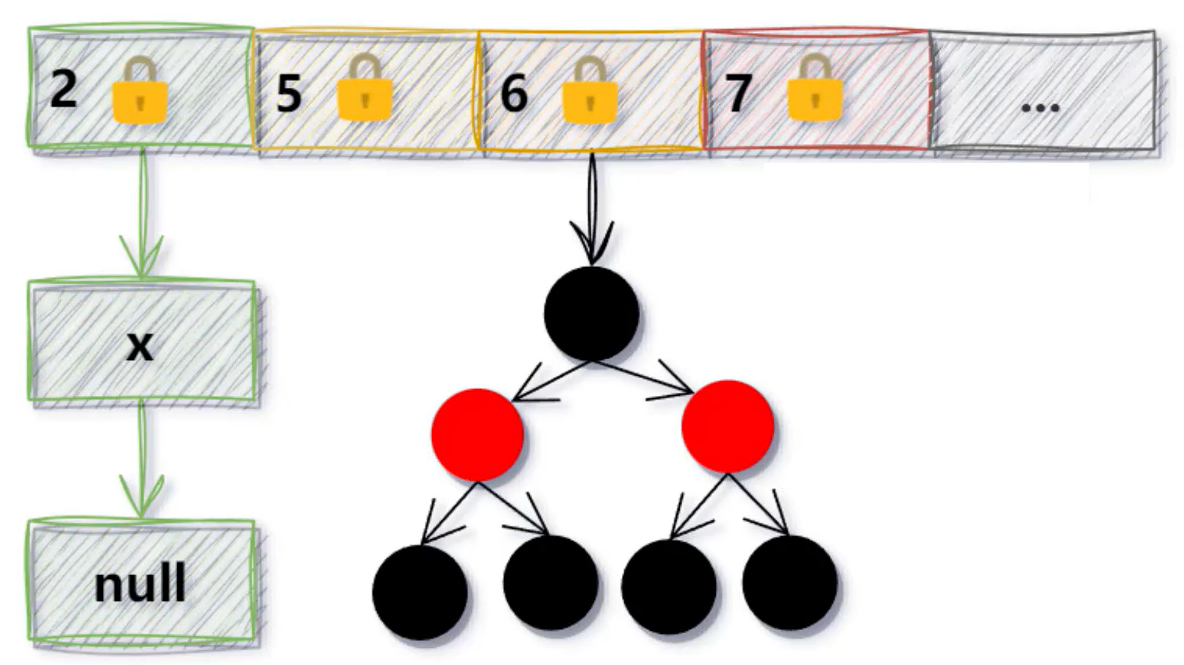
2. 扩容方法transfer()
ConcurrentHashMap为了减少扩容带来的时间影响,在扩容过程中没有进行加锁,并且支持多线程进行扩容操作。在扩容过程中主要使用sizeCtl和transferIndex这两个属性来协调多线程之间的并发操作,并且在扩容过程中大部分数据可以做到访问不阻塞,整个扩容操作分为以下几个步骤:
- 根据CPU核数和数组长度,计算每个线程应该处理的桶数量,如果CPU为单核,则使用一个线程处理所有桶
- 根据当前数组长度n,新建一个两倍长度的数组nextTable(该这个步骤是单线程执行的)
- 将原来table中的元素复制到nextTable中,这里允许多线程进行操作,具体操作步骤如下:
- 初始化ForwardingNode对象,充当占位节点,hash值为-1,该占位对象存在时表示集合正在扩容状态。
- 通过for循环从右往左依次迁移当前线程所负责数组:
- 每当一条线程扩容结束就会更新一次sizeCtl的值,进行减1操作,当最后一条线程扩容结束后,需要重新检查一遍数组,防止有遗漏未成功迁移的桶。扩容结束后,将nextTable设置为null,表示扩容已结束,将table指向新数组,sizeCtl设置为扩容阈值。
3. ConcurrentHashMap读操作不需要加锁
- 在HashEntry类中,key,hash和next域都被声明为final的,value域被volatile所修饰,因此HashEntry对象几乎是不可变的,通过HashEntry对象的不变性来降低读操作对加锁的需求。
- 用volatile变量协调读写线程间的内存可见性;
- 若读时发生指令重排序现象(也就是读到value域的值为null的时候),则加锁重读;
4. 如何加锁
- CAS的具体使用细节
当某个桶(结点)为空时,使用CAS操作往桶(结点)中插入新值。当桶数组(table)还没有初始化时,会使用CAS操作来保证只有一个线程能够成功地初始化这个数组 - synchronized的具体使用细节。
当桶(结点)不为空,存在元素时,即桶(结点)为链表或者红黑树时,就会给桶加synchronized锁,保证同时只有一个线程来操作桶。这些操作包括添加、修改或者删除桶中的元素。
5. key不能为null原因
在并发环境中,若允许null键,当调用map.get(key)返回null时,无法区分是键不存在还是值本身为null。在单线程中可以通过containsKey(key)进一步判断,但在多线程环境下,两次操作间可能存在竞态条件(如其他线程删除了该键),导致结果不可靠。