与Flink DataStream集成
1. 环境准备
1.1 创建maven工程flink-iceberg-demo,配置pom文件
xml
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<flink.version>1.17.2</flink.version>
<scala.binary.version>2.12</scala.binary.version>
<slf4j.version>1.7.36</slf4j.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
<scope>provided</scope> <!--不会打包到依赖中,只参与编译,不参与运行 -->
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-files</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<!--idea运行时也有webui-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>${slf4j.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${slf4j.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-to-slf4j</artifactId>
<version>2.14.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.6</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.iceberg</groupId>
<artifactId>iceberg-flink-runtime-1.19</artifactId>
<version>1.6.1</version>
</dependency>
</dependencies>1.2 配置日志
resources目录下新建log4j.properties。
ini
log4j.rootLogger=error,stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.target=System.out
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n2. 读取数据
2.1 常规Source写法
- Batch方式
java
public static void main(String[] args) throws Exception {
System.setProperty("HADOOP_USER_NAME", "jack");
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment(new Configuration());
env.setParallelism(1);
// 获取TableLoader
String path = "hdfs://hadoop102:8020/warehouse/flink-iceberg/default_database/ice_sample3";
// 只能加载iceberg中hadoop类别的表,hive类别的不能通过fromHadoopTable加载
TableLoader tableLoader = TableLoader
.fromHadoopTable(path);
// 通过FlinkSource加载表
DataStream<RowData> rowDataDS = FlinkSource
.forRowData()
.env(env)
.tableLoader(tableLoader)
// batch方式-false, streaming方式-true
.streaming(false)
.build();
rowDataDS.map(rowData-> Tuple2.of(rowData.getInt(0), rowData.getString(1).toString()))
.returns(Types.TUPLE(Types.INT, Types.STRING))
.print();
env.execute();
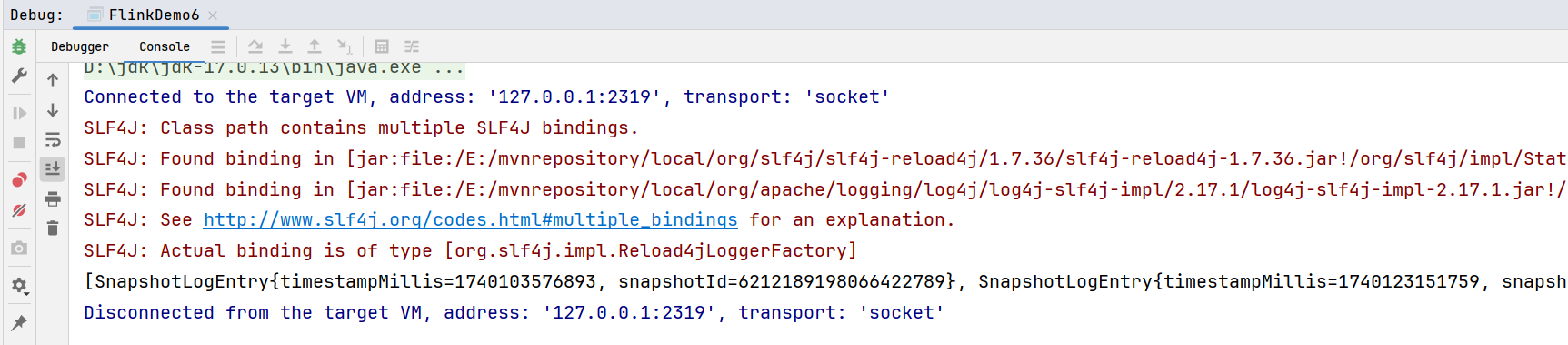
}运行结果: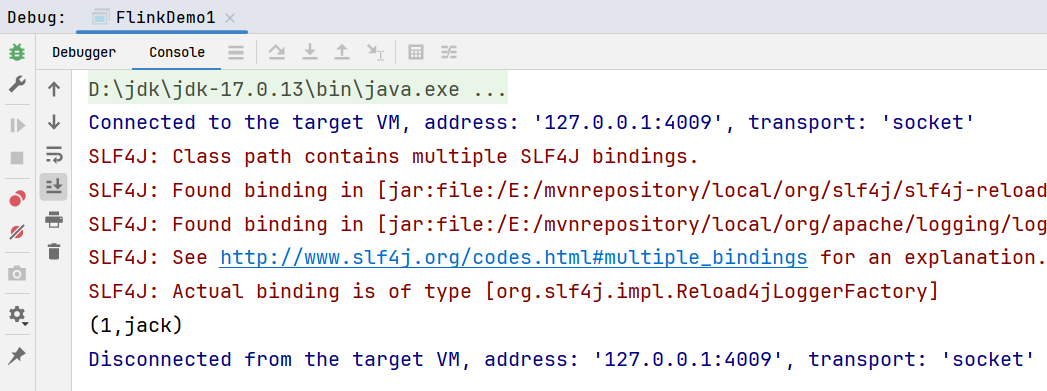 读取hive类别的iceberg表麻烦一些:
读取hive类别的iceberg表麻烦一些:
java
public static void main(String[] args) throws Exception {
System.setProperty("HADOOP_USER_NAME", "jack");
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(new Configuration());
env.setParallelism(1);
// 获取TableLoader
String hiveMetastoreUri = "thrift://hadoop103:9083";
HashMap<String, String> properties = new HashMap<>();
properties.put("uri", hiveMetastoreUri);
properties.put("warehouse", "hdfs://hadoop102:8020/flink/warehouse/");
org.apache.hadoop.conf.Configuration hadoopConf = new org.apache.hadoop.conf.Configuration();
// 获得hive的CataLoader
CatalogLoader hiveCatalogLoader = CatalogLoader.hive("hive_catalog", hadoopConf, properties);
// 库名 + 表名
TableIdentifier tableIdentifier = TableIdentifier.of("flink_db", "t_t1");
TableLoader tableLoader = TableLoader.fromCatalog(hiveCatalogLoader, tableIdentifier);
tableLoader.open();
// 通过FlinkSource加载表
DataStream<RowData> rowDataDS = FlinkSource
.forRowData()
.env(env)
.tableLoader(tableLoader)
// batch方式-false, streaming方式-true
.streaming(false)
.build();
rowDataDS.print();
env.execute();
}执行结果: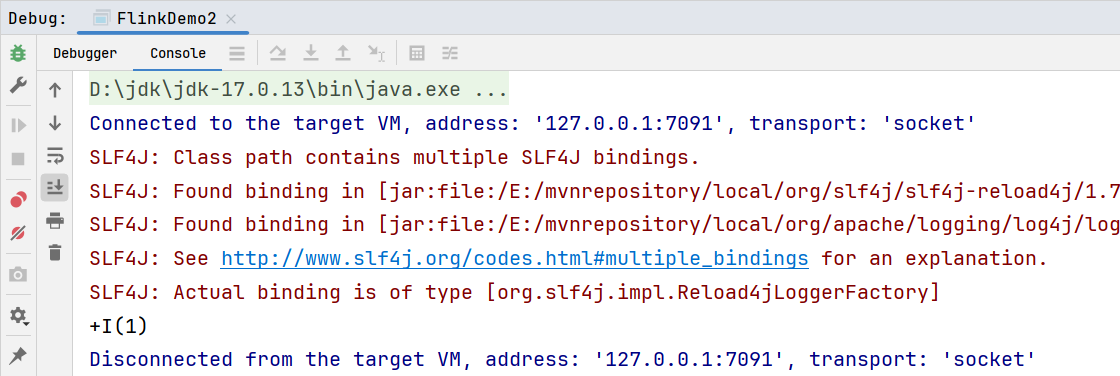 2. Streaming方式
2. Streaming方式
java
public static void main(String[] args) throws Exception {
System.setProperty("HADOOP_USER_NAME", "jack");
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment(new Configuration());
env.setParallelism(1);
// 获取TableLoader
String path = "hdfs://hadoop102:8020/warehouse/flink-iceberg/default_database/ice_sample3";
// 只能加载iceberg中hadoop类别的表,hive类别的不能通过fromHadoopTable加载
TableLoader tableLoader = TableLoader
.fromHadoopTable(path);
// 通过FlinkSource加载表
DataStream<RowData> rowDataDS = FlinkSource
.forRowData()
.env(env)
.tableLoader(tableLoader)
// batch方式-false, streaming方式-true
.streaming(true)
.build();
rowDataDS.map(rowData-> Tuple2.of(rowData.getInt(0), rowData.getString(1).toString()))
.returns(Types.TUPLE(Types.INT, Types.STRING))
.print();
env.execute();
}2.2 FLIP-27 Source写法
- Batch方式
java
public static void main(String[] args) throws Exception {
System.setProperty("HADOOP_USER_NAME", "jack");
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment(new Configuration());
env.setParallelism(1);
// 获取TableLoader
String path = "hdfs://hadoop102:8020/warehouse/flink-iceberg/default_database/ice_sample3";
TableLoader tableLoader = TableLoader.fromHadoopTable(path);
// flink1.12后版本支持IcebergSource写法
IcebergSource<RowData> icebergSource = IcebergSource
.forRowData()
.tableLoader(tableLoader)
.assignerFactory(new SimpleSplitAssignerFactory())
.build();
DataStreamSource<RowData> icebergDS = env.fromSource(icebergSource,
WatermarkStrategy.noWatermarks(),
"iceberg source",
TypeInformation.of(RowData.class));
icebergDS.map(rowData -> Tuple2.of(rowData.getInt(0), rowData.getString(1).toString()))
.returns(Types.TUPLE(Types.INT, Types.STRING))
.print();
env.execute();
}执行的时候报错包访问受限,可以设置JVM参数:
ini
--add-opens java.base/java.lang.invoke=ALL-UNNAMED --add-opens java.base/java.util=ALL-UNNAMED --add-opens java.base/java.util.concurrent.atomic=ALL-UNNAMED执行结果: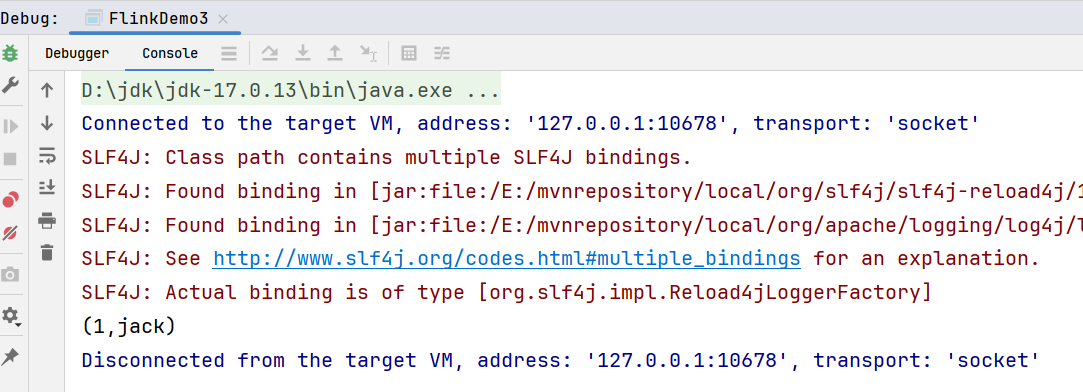 2. Streaming方式
2. Streaming方式
java
public static void main(String[] args) throws Exception {
System.setProperty("HADOOP_USER_NAME", "jack");
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment(new Configuration());
env.setParallelism(1);
// 获取TableLoader
String path = "hdfs://hadoop102:8020/warehouse/flink-iceberg/default_database/ice_sample3";
TableLoader tableLoader = TableLoader.fromHadoopTable(path);
// flink1.12后版本支持IcebergSource写法
IcebergSource<RowData> icebergSource = IcebergSource
.forRowData()
.tableLoader(tableLoader)
.assignerFactory(new SimpleSplitAssignerFactory())
// 默认是false
.streaming(true)
.streamingStartingStrategy(StreamingStartingStrategy.INCREMENTAL_FROM_LATEST_SNAPSHOT)
.monitorInterval(Duration.ofSeconds(60))
.build();
DataStreamSource<RowData> icebergDS = env.fromSource(icebergSource,
WatermarkStrategy.noWatermarks(),
"iceberg source",
TypeInformation.of(RowData.class));
icebergDS.map(rowData -> Tuple2.of(rowData.getInt(0), rowData.getString(1).toString()))
.returns(Types.TUPLE(Types.INT, Types.STRING))
.print();
env.execute();
}3. 写入数据
目前支持DataStream<RowData>和DataStream<Row>格式的数据流写入Iceberg表。
3.1 写入方式支持append、overwrite、upsert
java
public static void main(String[] args) throws Exception {
System.setProperty("HADOOP_USER_NAME", "jack");
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment(new Configuration());
env.setParallelism(1);
// 获取TableLoader
String path = "hdfs://hadoop102:8020/warehouse/flink-iceberg/default_database/ice_sample3";
TableLoader tableLoader = TableLoader.fromHadoopTable(path);
SingleOutputStreamOperator<RowData> input = env.fromElements("")
.map((MapFunction<String, RowData>) s -> {
GenericRowData genericRowData = new GenericRowData(2);
genericRowData.setField(0, 2);
genericRowData.setField(1, new BinaryStringData("Anna"));
return genericRowData;
});
FlinkSink.forRowData(input)
.tableLoader(tableLoader)
.append(); // append方式
//.overwrite(true); // overwrite方式
//.upsert(true); // upsert方式
env.execute("执行插入数据");
}查询数据插入情况: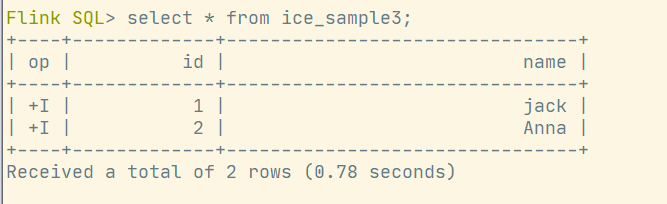
4. 合并小文件
Iceberg现在不支持在flink sql中检查表,需要使用Iceberg提供的Java API来读取元数据来获得表信息。将小文件重写为大文件:
scala
public static void main(String[] args) throws Exception {
System.setProperty("HADOOP_USER_NAME", "jack");
String path = "hdfs://hadoop102:8020/warehouse/flink-iceberg";
// 1.获取 Table对象
// 1.1 创建 catalog对象
org.apache.hadoop.conf.Configuration hadoopConf = new org.apache.hadoop.conf.Configuration();
HadoopCatalog hadoopCatalog = new HadoopCatalog(hadoopConf, path);
// 1.2 通过 catalog加载 Table对象
Table table = hadoopCatalog.loadTable(TableIdentifier.of("default_database", "ice_sample3"));
// 有Table对象,就可以获取元数据、进行维护表的操作
System.out.println(table.history());
// System.out.println(table.expireSnapshots().expireOlderThan());
// 2.通过 Actions 来操作 合并
Actions.forTable(table)
.rewriteDataFiles()
.targetSizeInBytes(1024L)
.execute();
}可以看到代码只调用iceberg相关的api,没有使用flink。在得到Table对象后,就可以获取元数据、进行维护表的操作。运行结果: