Spark 运行环境
Spark✨作为一个数据处理框架和计算引擎,被设计在所有常见的集群环境中运行, 在国内工作中主流的环境为 Yarn,
1. Local 模式
local本地模式主要用来进行练习演示的
1.1 下载Spark包上传Linux
- 访问Spark官网:https://spark.apache.org/downloads.html ,下载Spark压缩包
- 将spark-3.4.2-bin-hadoop3.tgz、jdk-8u391-linux-x64.tar.gz文件上传到Linux并解压缩,放置在指定位置,路径中 不要包含中文或空格
[jack@hadoop101 software]$ pwd
/opt/software
[jack@hadoop101 software]$ tar -xvf spark-3.4.2-bin-hadoop3.tgz -C ../module/
[jack@hadoop101 software]$ mv ../module/spark-3.4.2-hadoop3 spark-3.4.2
[jack@hadoop101 software]$ tar -xvf jdk-8u391-linux-x64.tar.gz -C ../module/1.2 配置Java环境
在/etc/profile.d创建spark_env.sh
[jack@hadoop102 profile.d]$ sudo vi spark_env.sh
## 填写以下内容暴露环境变量
[jack@hadoop102 profile.d]$ cat spark_env.sh
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_391
export PATH=$PATH:$JAVA_HOME/bin
[jack@hadoop101 profile.d]$ source /etc/profile.d/spark_env.sh1.3 启动Local环境
## 切换到Spark解压缩目录,执行以下命令:
[jack@hadoop101 spark-3.4.2]$ ./bin/spark-shell
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
24/03/01 11:09:41 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Spark context Web UI available at http://hadoop101:4040
Spark context available as 'sc' (master = local[*], app id = local-1711249783804).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.4.2
/_/
Using Scala version 2.12.17 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_391)
Type in expressions to have them evaluated.
Type :help for more information.
scala>启动成功后,可以输入网址访问Web监控页面: http://hadoop101:4040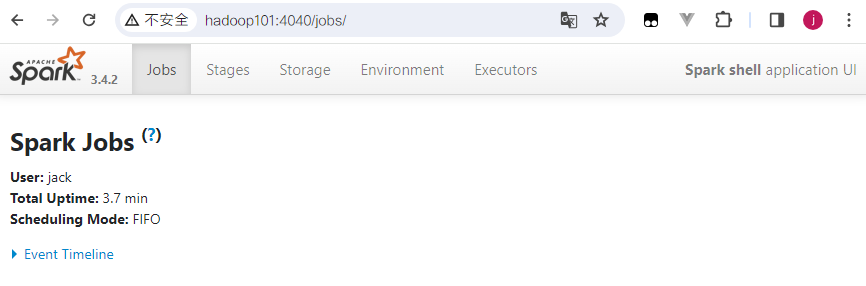
1.4 测试Local环境
Spark文件夹下的data目录中,添加1.txt文件:
scala> sc.textFile("data/1.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
res0: Array[(String, Int)] = Array((Spark,4), (Hello,7), (Scala,3))1.5 退出Local模式
按键Ctrl+C或输入Scala指令:qiut
scala> :quit
[jack@hadoop101 spark-3.4.2]$1.6 提交应用
不用进入Spark命令行交互模式,直接输入
[jack@hadoop101 spark-3.4.2]$ ./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[2] \
./examples/jars/spark-examples_2.12-3.4.2.jar \
10参数说明:
- --class 表示要执行程序的主类,此处可以更换为咱们自己写的应用程序
- --master local[2] 部署模式,默认为本地模式,数字表示分配的虚拟CPU核数量
- spark-examples_2.12-3.4.2.jars 是运行的应用类所在的jar包,实际使用时,可以设定为自己打的jar包
- 数字10 表示程序的入口参数,用于设定当前应用的任务数量
运行结果:
24/03/01 12:18:26 INFO SparkContext: Running Spark version 3.4.2
24/03/01 12:18:27 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
24/03/01 12:18:27 INFO ResourceUtils: ==============================================================
24/03/01 12:18:27 INFO ResourceUtils: No custom resources configured for spark.driver.
24/03/01 12:18:27 INFO ResourceUtils: ==============================================================
24/03/01 12:18:27 INFO SparkContext: Submitted application: Spark Pi
24/03/01 12:18:27 INFO ResourceProfile: Default ResourceProfile created, executor resources: Map(cores -> name: cores, amount: 1, script: , vendor: , memory -> name: memory, amount: 1024, script: , vendor: , offHeap -> name: offHeap, amount: 0, script: , vendor: ), task resources: Map(cpus -> name: cpus, amount: 1.0)
24/03/01 12:18:27 INFO ResourceProfile: Limiting resource is cpu
24/03/01 12:18:27 INFO ResourceProfileManager: Added ResourceProfile id: 0
24/03/01 12:18:27 INFO SecurityManager: Changing view acls to: jack
24/03/01 12:18:27 INFO SecurityManager: Changing modify acls to: jack
24/03/01 12:18:27 INFO SecurityManager: Changing view acls groups to:
24/03/01 12:18:27 INFO SecurityManager: Changing modify acls groups to:
24/03/01 12:18:27 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: jack; groups with view permissions: EMPTY; users with modify permissions: jack; groups with modify permissions: EMPTY
24/03/01 12:18:28 INFO Utils: Successfully started service 'sparkDriver' on port 41613.
....
24/03/01 12:18:33 INFO BlockManagerMaster: BlockManagerMaster stopped
24/03/01 12:18:33 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
24/03/01 12:18:33 INFO SparkContext: Successfully stopped SparkContext
24/03/01 12:18:33 INFO ShutdownHookManager: Shutdown hook called
24/03/01 12:18:33 INFO ShutdownHookManager: Deleting directory /tmp/spark-1cb47dde-464c-4950-b637-d8022599c301
24/03/01 12:18:33 INFO ShutdownHookManager: Deleting directory /tmp/spark-2625b1b0-ab05-4dae-b104-09e51d3332792. Standalone模式
Spark自身节点运行的集群模式也就是独立部署(Standalone)模式。Spark的Standalone模式使用的是经典的master-slave模式。 集群规划:
| 组件 | Linux1 | Linux2 | Linux3 |
|---|---|---|---|
| Spark | Worker Master | Worker | Worker |
2.1 解压缩文件
将spark-3.4.2-bin-hadoop3.tgz文件上传到Linux并解压缩在指定位置
[jack@hadoop101 software]$ tar -zxvf spark-3.4.2-bin-hadoop3.2.tgz -C /opt/module
[jack@hadoop101 software]$ cd /opt/module
[jack@hadoop101 software]$ mv spark-3.4.2-bin-hadoop3.2 spark-standalone2.2 修改配置文件
- 进入spark-standalone的conf目录下,修改slaves.template文件名为slaves,spark-env.sh.template文件名修改为 spark-env.sh
mv slaves.template slaves
mv spark-env.sh.template spark-env.sh- 修改slaves文件,添加work节点
linux1
linux2
linux3- 修改spark-env.sh文件
# 添加JAVA_HOME环境变量和集群对应的master节点
export JAVA_HOME=/opt/module/jdk1.8.0_144
SPARK_MASTER_HOST=linux1
SPARK_MASTER_PORT=7077提示
7077端口是Spark节点之间内部通信的端口
- 分发spark-standalone目录到linux2,linux3
xsync spark-standalone2.3 启动集群
- 执行脚本命令
[jack@linux1 spark-standalone]./sbin/start-all.sh 2. 查看Master资源监控Web UI界面: http://linux1:8080
2. 查看Master资源监控Web UI界面: http://linux1:8080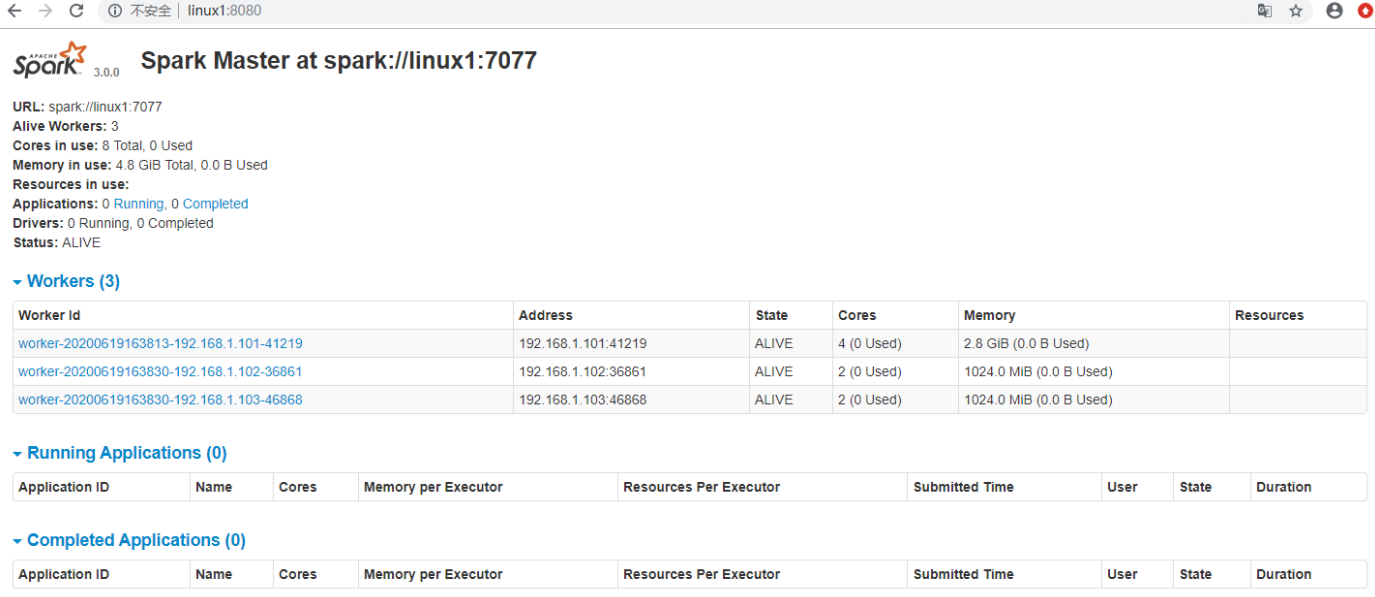
2.4 提交应用
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://linux1:7077\
./examples/jars/spark-examples_2.12-3.4.2.jar \
10参数说明:
- --class 表示要执行程序的主类,此处可以更换为咱们自己写的应用程序
- --master spark://linux1:7077 独立部署模式,连接到Spark集群
- spark-examples_2.12-3.4.2.jar是运行的应用类所在的jar包,实际使用时,可以设定为自己打的jar包
- 数字10表示程序的入口参数,用于设定当前应用的任务数量
运行结果: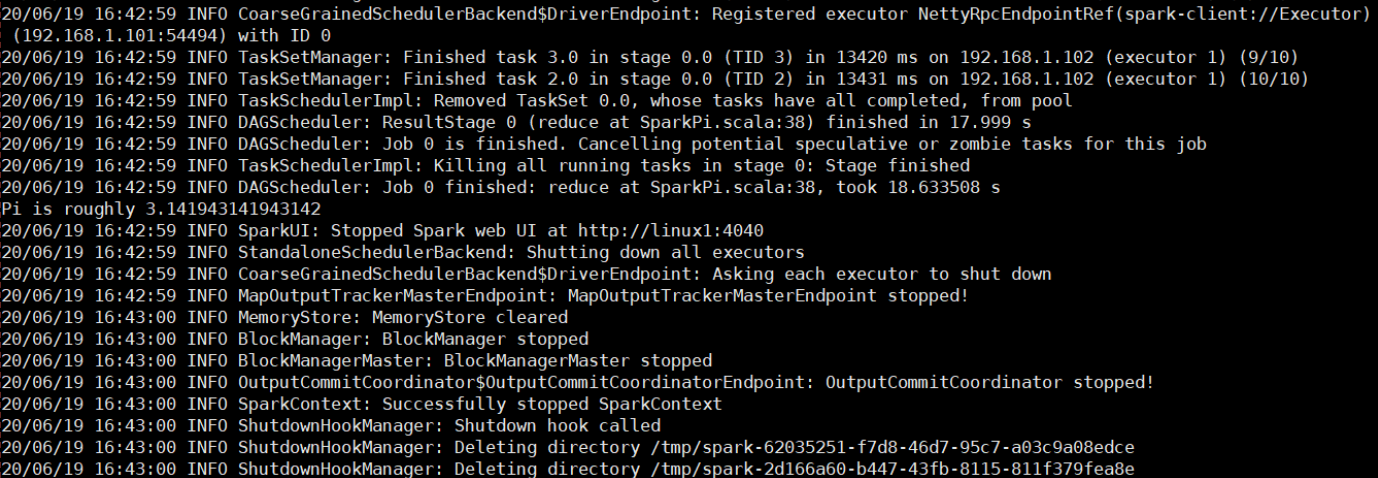 执行任务时,默认采用服务器集群节点的总核数,每个节点内存1024M。
执行任务时,默认采用服务器集群节点的总核数,每个节点内存1024M。 
2.5 提交参数说明
在提交应用中,提交参数格式如下:
./bin/spark-submit \
--class <main-class> \
--master <master-url> \
... # other options
<application-jar> \
[application-arguments]| 参数 | 解释 | 可选值 |
|---|---|---|
| --class | Spark程序中包含主函数的类 | |
| --master | Spark程序运行的模式(环境) | 模式:local[*]、spark://linux1:7077、Yarn |
| --executor-memory 1G | 指定每个executor可用内存为1G | 符合集群内存配置即可,具体情况具体分析。 |
| --total-executor-cores 2 | 指定所有executor使用的cpu核数 | 符合集群内存配置即可,具体情况具体分析。 |
| --executor-cores | 为2个指定每个executor使用的cpu核数 | 符合集群内存配置即可,具体情况具体分析。 |
| application-jar | 打包好的应用jar,包含依赖。这个URL在集群中全局可见。比如hdfs:// 共享存储系统,如果是file:// path,那么所有的节点的 | |
| application-arguments | 传给main()方法的参数 |
2.6 配置历史服务
配置历史服务可以在spark-shell停止掉后,集群监控linux1:4040页面就仍然能够看到历史任务的运行情况
- 修改spark-defaults.conf.template文件名为spark-defaults.conf
mv spark-defaults.conf.template spark-defaults.conf- 修改spark-default.conf文件,配置日志存储路径
spark.eventLog.enabled true
spark.eventLog.dir hdfs://linux1:8020/directory危险
需要提前启动hadoop集群,HDFS上的directory目录需要提前存在。
- 修改spark-env.sh文件, 添加日志配置
# 配置参数说明:WEB访问的端口号为18080, logDirectory指定历史服务器日志存储路径
# retainedApplications指定保存Application历史记录的个数,如果超过这个值,旧的应用程序信息将被删除
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://linux1:8020/directory
-Dspark.history.retainedApplications=30"- 分发配置文件
xsync conf- 重新启动集群和历史服务
./sbin/start-all.sh
./sbin/start-history-server.sh- 重新执行任务后访问http://linux1:18080
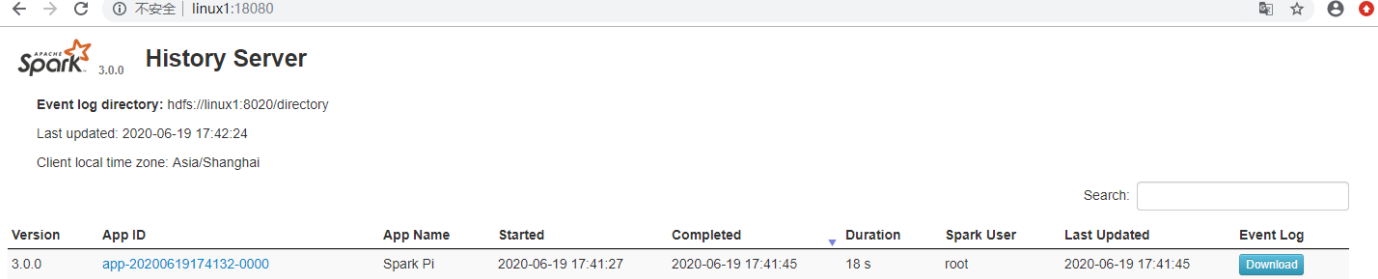
2.7 配置高可用
当前集群中的Master节点只有一个,所以会存在单点故障问题。所以为了解决单点故障问题,需要在集群中配置多个Master节点,一旦处于活动状态的Master 发生故障时,由备用Master提供服务,保证作业可以继续执行。高可用需要借助Zookeeper
集群规划:
| 组件 | Linux1 | Linux2 | Linux3 |
|---|---|---|---|
| Zookeeper | Zookeeper | Zookeeper | Zookeeper |
| Spark | Master、Worker | Master、Worker | Worker |
- 停止集群
./sbin/stop-all.sh- 启动Zookeeper
xstart zk- 修改spark-env.sh文件添加如下配置
#注释如下内容:
#SPARK_MASTER_HOST=linux1
#SPARK_MASTER_PORT=7077
#添加如下内容:
#Master监控页面默认访问端口为8080,但是可能会和Zookeeper冲突,所以改成8989,也可以自定义,访问UI监控页面时请注意
SPARK_MASTER_WEBUI_PORT=8989
export SPARK_DAEMON_JAVA_OPTS="
-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=linux1,linux2,linux3
-Dspark.deploy.zookeeper.dir=/spark"- 分发配置文件
xsync conf/- 启动集群
./sbin/start-all.sh- 访问http://linx1:8989
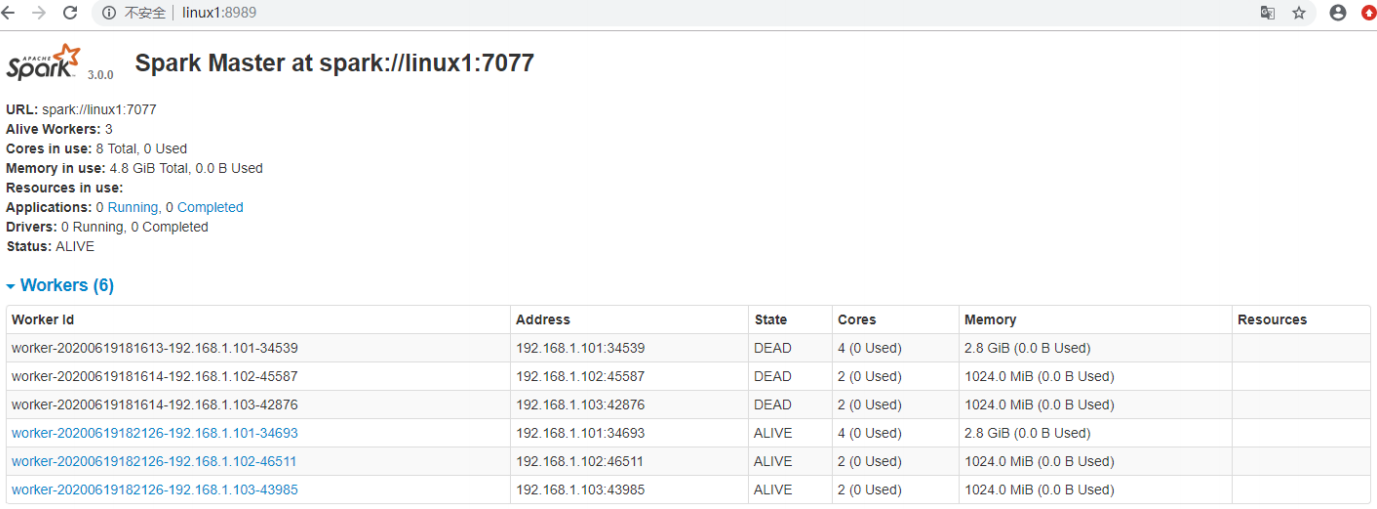
- 启动linux2的单独Master节点,可以看到linux2节点Master状态处于备用状态
[jack@linux2 spark-standalone]$ ./sbin/start-master.sh
3. Yarn模式
Spark主要是计算框架,而不是资源调度框架,所以本身提供的资源调度并不是它的强项,集成Yarn环境称为Yarn模式。
3.1 上传Spark相关jar到HDFS
Spark相关jar可以直接在Yarn中使用,可以优化Spark作业的jar包大小,避免上传耗时。
[jack@hadoop103 spark-3.4.2]$ jar cv0f spark-libs.jar -C $SPARK_HOME/jars/ .
## 然后将其上传到hdfs中,先自己创建好目录
[jack@hadoop103 spark-3.4.2]$ hdfs dfs -put spark-libs.jar /spark/jars
## 到spark-defaults.conf中添加配置
spark.yarn.archive hdfs://hadoop102:8020/spark/jars/spark-libs.jar3.2 修改配置文件
- 修改hadoop配置文件yarn-site.xml
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>- 修改conf/spark-env.sh
mv spark-env.sh.template spark-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144
YARN_CONF_DIR=/opt/module/hadoop/etc/hadoop3.3 启动HDFS以及YARN集群
[jack@hadoop102 spark-3.4.2]$ hadoop_helper start3.4 提交应用测试
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
./examples/jars/spark-examples_2.12-3.4.2.jar \
10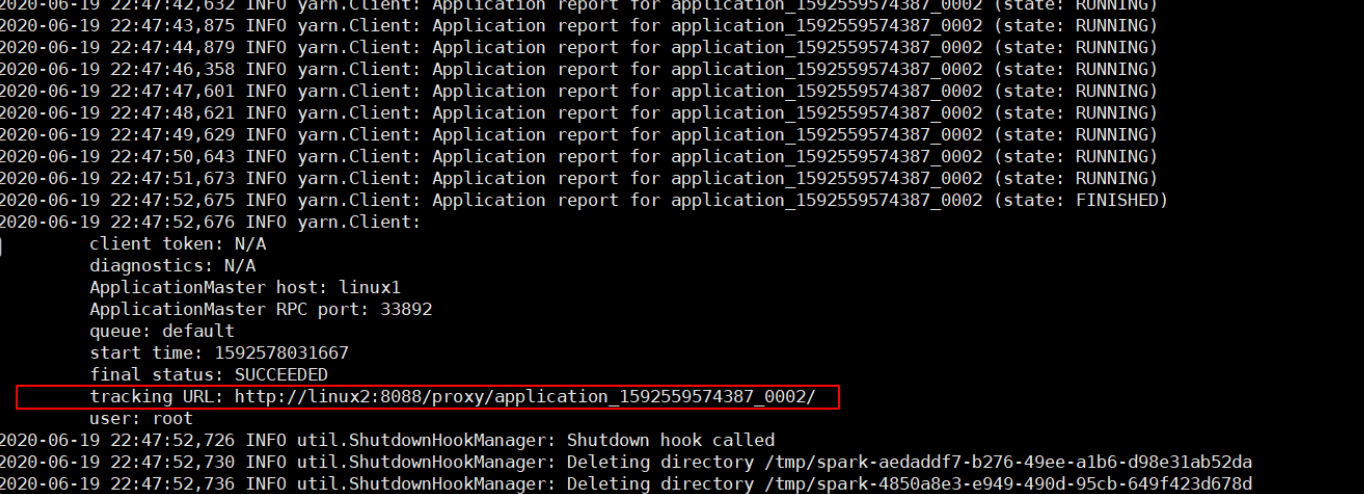 查看http://hadoop103:8088/ 页面,点击History,查看历史页面
查看http://hadoop103:8088/ 页面,点击History,查看历史页面 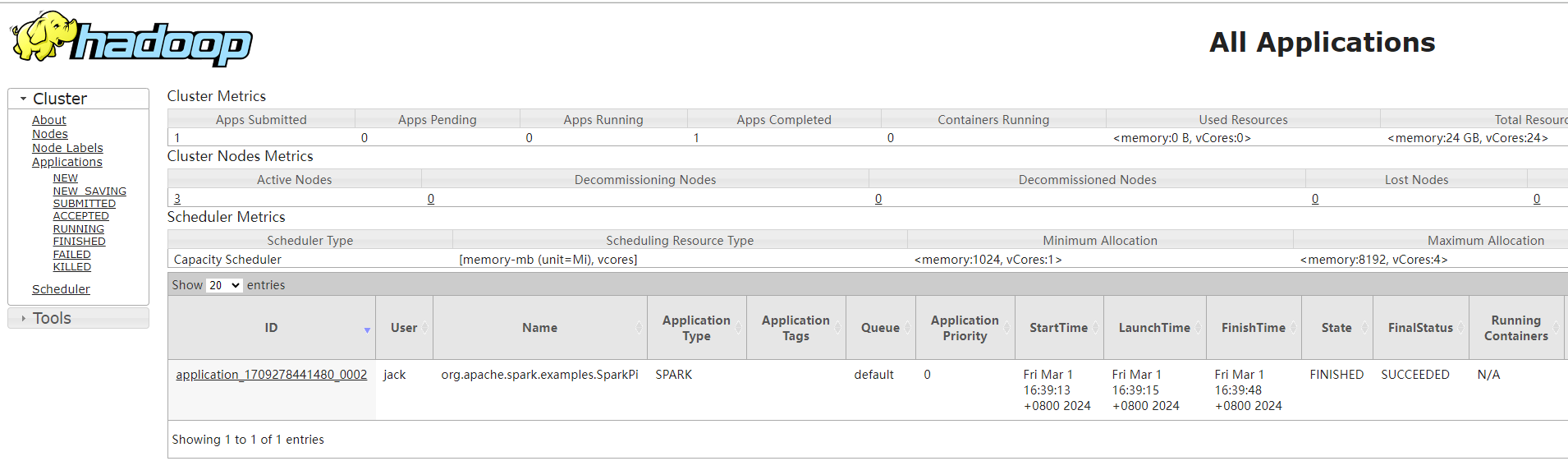
3.5 配置历史服务器
将hadoop104作为Spark的历史服务器。
- 修改spark-defaults.conf.template文件名为spark-defaults.conf
mv spark-defaults.conf.template spark-defaults.conf
## 创建存放spark的日志记录文件夹
[jack@hadoop102 spark-3.4.2]$ hadoop fs -mkdir /spark_logs- 修改spark-defaults.conf文件,配置日志存储路径
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop102:8020/spark_logs
spark.yarn.historyServer.address=hadoop104:18080
spark.history.ui.port=18080- 修改spark-env.sh文件, 添加日志配置
# 配置参数说明:WEB访问的端口号为18080, logDirectory指定历史服务器日志存储路径
# retainedApplications指定保存Application历史记录的个数,如果超过这个值,旧的应用程序信息将被删除
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://hadoop102:8020/spark_logs
-Dspark.history.retainedApplications=30"- 启动历史服务
./sbin/start-history-server.sh- 重新提交应用
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
./examples/jars/spark-examples_2.12-3.4.2.jar \
10控制台日志发现出现了PI的运行结果: 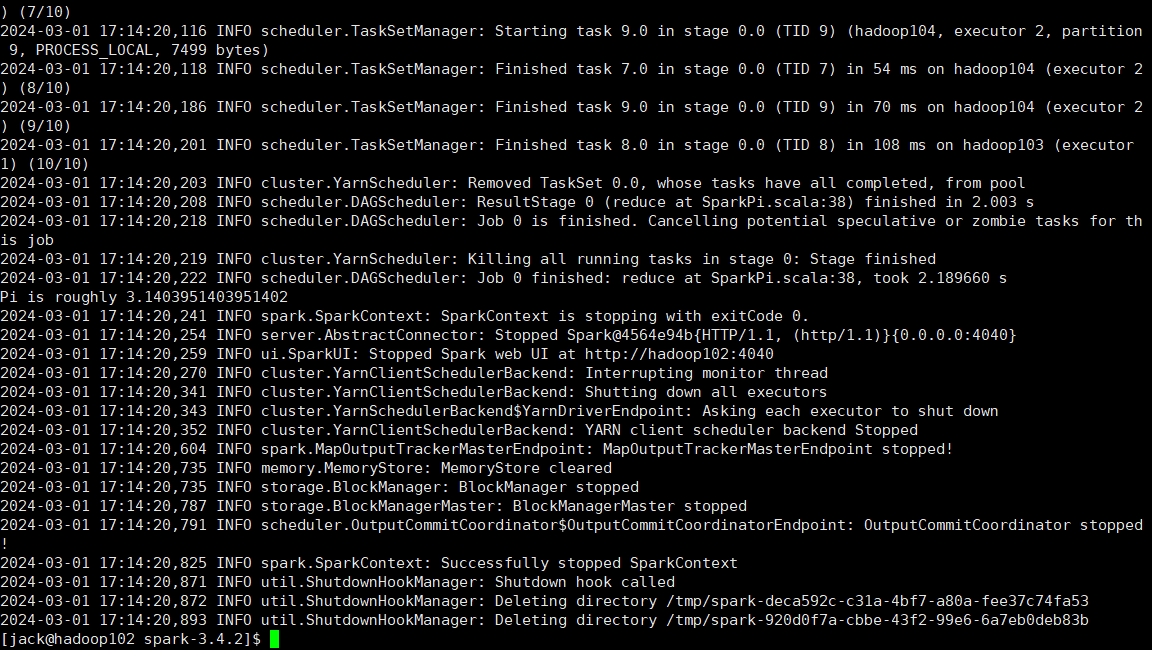 6. 查看Spark历史服务器:http://hadoop104:18080/
6. 查看Spark历史服务器:http://hadoop104:18080/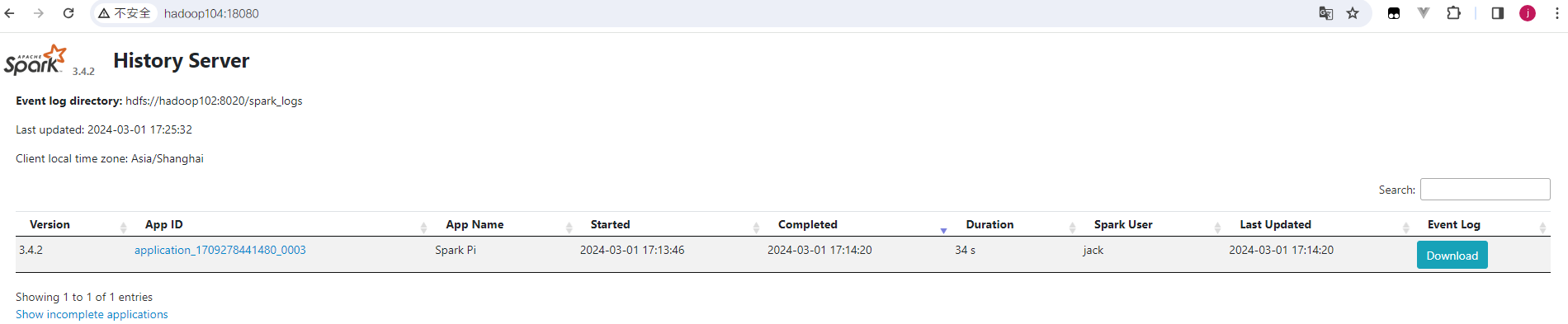
4. Windows模式
自己学习Spark时,每次都需要启动虚拟机,启动集群,这是一个比较繁琐的过程,并且会占大量的系统资源,导致系统执行变慢,不仅仅影响学习效果,也影响学习进度,Spark非常暖心地提供了可以在windows系统下启动本地集群的方式,这样,在不使用虚拟机的情况下,也能学习Spark的基本使用😁,一般情况下都会采用Windows系统的集群来学习Spark。
4.1 解压缩文件
将文件spark-3.4.2-bin-hadoop3.tgz解压缩到无中文无空格的路径中
4.2 启动本地环境
- 执行bin目录中的spark-shell.cmd文件,启动Spark本地环境
D:\spark-3.4.2-bin-hadoop3\bin>spark-shell.cmd
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://JieBaBa-PC:4040
Spark context available as 'sc' (master = local[*], app id = local-1709286365602).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.4.2
/_/
Using Scala version 2.12.17 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_271)
Type in expressions to have them evaluated.
Type :help for more information.
scala>- data目录中添加1.txt文件, 在命令行中输入脚本代码
scala> sc.textFile("../data/1.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
res0: Array[(String, Int)] = Array((Hello,7), (Scala,3), (Spark,4))4.4 命令行提交应用
在DOS命令行窗口中执行提交指令
D:\spark-3.4.2-bin-hadoop3\bin>spark-submit --class org.apache.spark.examples.SparkPi --master local[2] ../examples/jars/spark-examples_2.12-3.4.2.jar 10
24/03/01 17:58:20 INFO SparkContext: Running Spark version 3.4.2
24/03/01 17:58:20 INFO ResourceUtils: ==============================================================
24/03/01 17:58:20 INFO ResourceUtils: No custom resources configured for spark.driver.
24/03/01 17:58:20 INFO ResourceUtils: ==============================================================
24/03/01 17:58:20 INFO SparkContext: Submitted application: Spark Pi
24/03/01 17:58:20 INFO ResourceProfile: Default ResourceProfile created, executor resources: Map(cores -> name: cores, amount: 1, script: , vendor: , memory -> name: memory, amount: 1024, script: , vendor: , offHeap -> name: offHeap, amount: 0, script: , vendor: ), task resources: Map(cpus -> name: cpus, amount: 1.0)
24/03/01 17:58:20 INFO ResourceProfile: Limiting resource is cpu
24/03/01 17:58:20 INFO ResourceProfileManager: Added ResourceProfile id: 0
24/03/01 17:58:20 INFO SecurityManager: Changing view acls to: mi
24/03/01 17:58:20 INFO SecurityManager: Changing modify acls to: mi
24/03/01 17:58:20 INFO SecurityManager: Changing view acls groups to:
24/03/01 17:58:20 INFO SecurityManager: Changing modify acls groups to:
24/03/01 17:58:20 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: mi; groups with view permissions: EMPTY; users with modify permissions: mi; groups with modify permissions: EMPTY
.......
24/03/01 17:58:23 INFO TaskSchedulerImpl: Killing all running tasks in stage 0: Stage finished
24/03/01 17:58:23 INFO DAGScheduler: Job 0 finished: reduce at SparkPi.scala:38, took 0.770262 s
Pi is roughly 3.1421031421031422
24/03/01 17:58:23 INFO SparkContext: SparkContext is stopping with exitCode 0.
24/03/01 17:58:23 INFO SparkUI: Stopped Spark web UI at http://JieBaBa-PC:4040
24/03/01 17:58:23 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
24/03/01 17:58:23 INFO MemoryStore: MemoryStore cleared
24/03/01 17:58:23 INFO BlockManager: BlockManager stopped
24/03/01 17:58:23 INFO BlockManagerMaster: BlockManagerMaster stopped
24/03/01 17:58:23 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
24/03/01 17:58:23 INFO SparkContext: Successfully stopped SparkContext
24/03/01 17:58:23 INFO ShutdownHookManager: Shutdown hook called
24/03/01 17:58:23 INFO ShutdownHookManager: Deleting directory C:\Users\mi\AppData\Local\Temp\spark-3c82f7d6-fa27-4460-b73a-36b77d26e0a9
24/03/01 17:58:23 INFO ShutdownHookManager: Deleting directory C:\Users\mi\AppData\Local\Temp\spark-8abdea5f-727b-4ea0-ba7a-86ef715110105. 部署模式对比
| 模式 | Spark安装机器数 | 需启动的进程 | 所属者 | 应用场景 |
|---|---|---|---|---|
| Local | 1 | 无 | Spark | 测试 |
| Standalone | 3 | Master及Worker | Spark | 单独部署 |
| Yarn | 1 | Yarn及HDFS | Hadoop | 混合部署 |