RDD入门
1. 什么是RDD
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据处理模型。代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合。
- 弹性
- 存储的弹性:内存与磁盘的自动切换;
- 容错的弹性:数据丢失可以自动恢复;
- 计算的弹性:计算出错重试机制;
- 分片的弹性:可根据需要重新分片。
- 分布式:数据存储在大数据集群不同节点上
- 数据集:RDD封装了计算逻辑,并不保存数据
- 数据抽象:RDD是一个抽象类,需要子类具体实现
- 不可变:RDD封装了计算逻辑,是不可以改变的,想要改变,只能产生新的RDD,在新的RDD里面封装计算逻辑
- 可分区、并行计算
2. RDD核心特性
Spark源代码中RDD.scala有段注释说明了RDD具有五大特性:
Internally, each RDD is characterized by five main properties:
- A list of partitions (RDD由一系列partitions组成)
- A function for computing each split (算子是作用于partition上的)
- A list of dependencies on other RDDs (RDD之间有依赖关系)
- Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned) (分区器是作用于K,V格式的RDD上)
- Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file)- 分区列表
RDD数据结构中存在分区列表,用于执行任务时并行计算,是实现分布式计算的重要属性。
/**
* Implemented by subclasses to return the set of partitions in this RDD. This method will only
* be called once, so it is safe to implement a time-consuming computation in it.
*
* The partitions in this array must satisfy the following property:
* `rdd.partitions.zipWithIndex.forall { case (partition, index) => partition.index == index }`
*/
protected def getPartitions: Array[Partition]- 分区计算函数
Spark在计算时,是使用分区函数对每一个分区进行计算
/**
* :: DeveloperApi ::
* Implemented by subclasses to compute a given partition.
*/
@DeveloperApi
def compute(split: Partition, context: TaskContext): Iterator[T]- RDD之间的依赖关系
RDD是计算模型的封装,当需求中需要将多个计算模型进行组合时,就需要将多个RDD建立依赖关系
/**
* Implemented by subclasses to return how this RDD depends on parent RDDs. This method will only
* be called once, so it is safe to implement a time-consuming computation in it.
*/
protected def getDependencies: Seq[Dependency[_]] = deps- 分区器(可选)
当数据为KV类型数据时,可以通过设定分区器自定义数据的分区
/** Optionally overridden by subclasses to specify how they are partitioned. */
@transient val partitioner: Option[Partitioner] = None- 首选位置(可选)
计算数据时,可以根据计算节点的状态选择不同的节点位置达到性能最优进行计算
/**
* Optionally overridden by subclasses to specify placement preferences.
*/
protected def getPreferredLocations(split: Partition): Seq[String] = Nil2. Spark执行流程
从计算的角度来讲,数据处理过程中需要计算资源(内存&CPU)和计算模型(逻辑)。执行时,需要将计算资源和计算模型进行协调和整合。
Spark框架在执行时,先申请资源,然后将应用程序的数据处理逻辑分解成一个一个的计算任务。然后将任务发到已经分配资源的计算节点上, 按照指定的计算模型进行数据计算。最后得到计算结果。在Yarn环境中流程如下:
- 启动Yarn集群环境
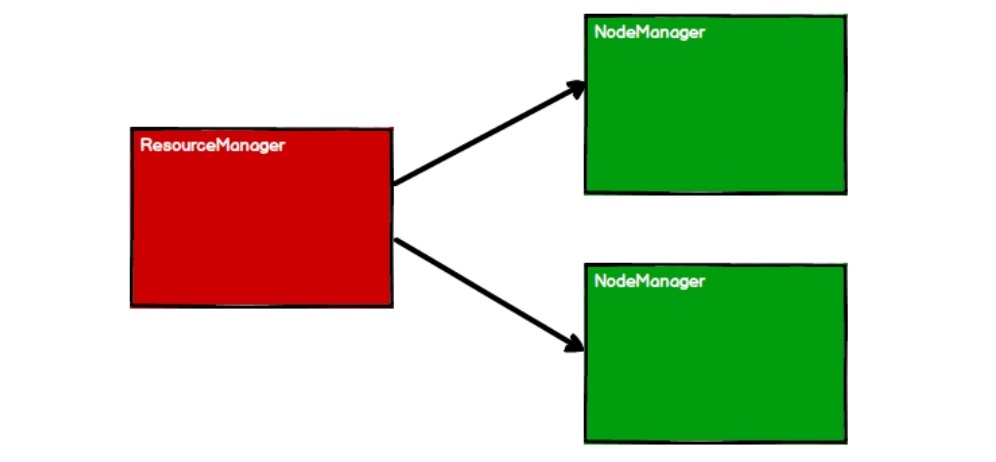
- Spark通过申请资源创建调度节点和计算节点
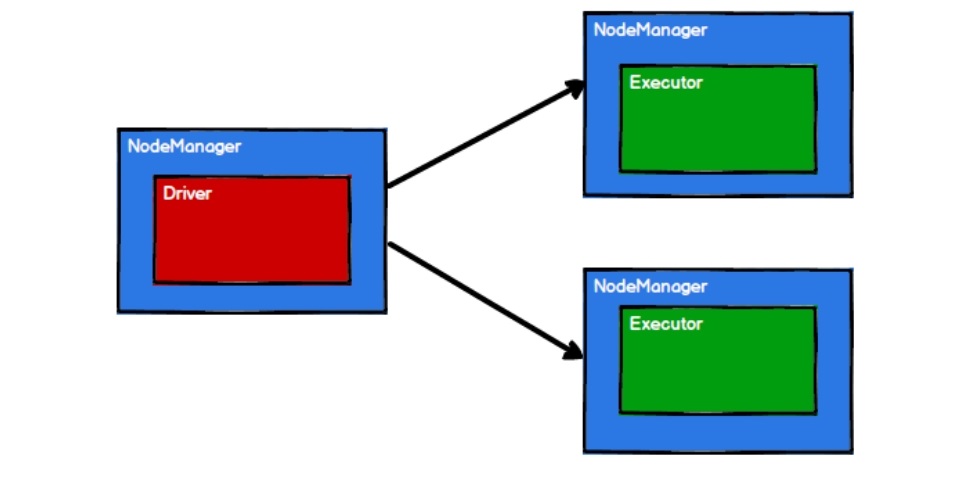
- Spark框架根据需求将计算逻辑根据分区划分成不同的任务
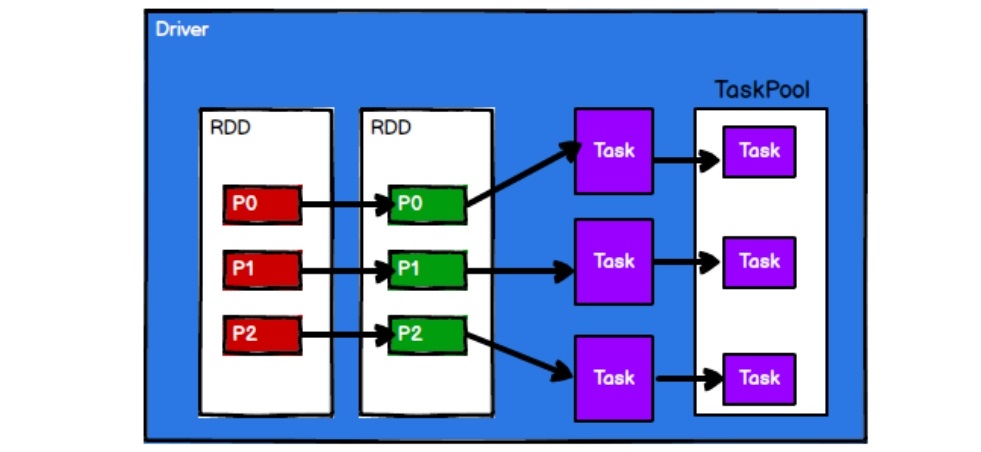
- 调度节点将任务根据计算节点状态发送到对应的计算节点进行计算
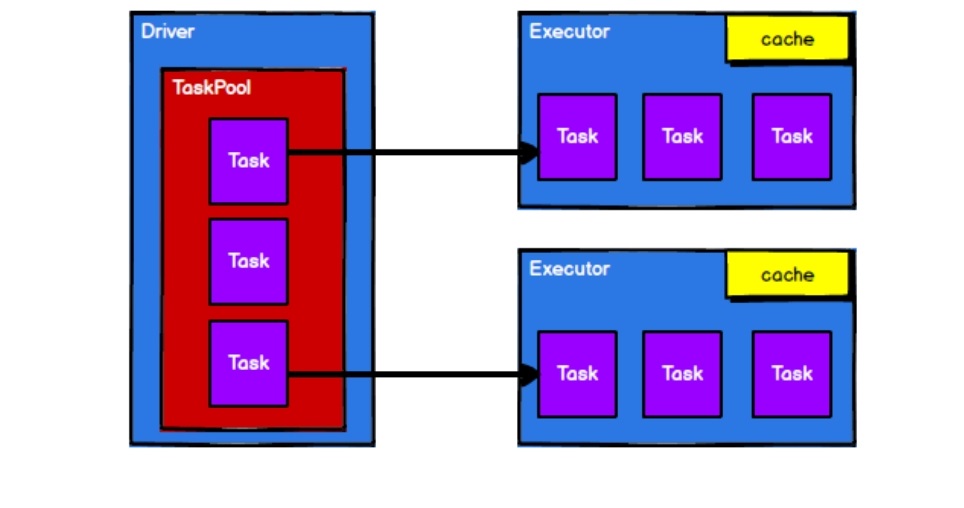 从以上流程可以看出RDD在整个流程中主要用于将计算逻辑进行封装,并生成Task发送给Executor节点执行计算的。
从以上流程可以看出RDD在整个流程中主要用于将计算逻辑进行封装,并生成Task发送给Executor节点执行计算的。
3. RDD基础编程
3.1 RDD创建
在Spark中创建RDD的创建方式可以分为四种:
- 从集合(内存)中创建RDD
从集合中创建RDD,Spark主要提供了两个方法:parallelize()和makeRDD()
object Rdd_InMem {
def main(args: Array[String]): Unit = {
// 1. 环境准备
// local表示本地模式,默认使用单核CPU,[*]表示使用所有核
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD_Demo")
val sc = new SparkContext(sparkConf)
// 2. 创建RDD
val seq: Seq[Int] = Seq[Int](1, 2, 3, 4, 5, 6)
// 在内存中创建RDD, 将内存中的集合数据作为数据源
// 方式1: parallelize 并行, 比如CPU为双核,并行度就为2
// val rdd1: RDD[Int] = sc.parallelize(seq)
// 方式2:方法名字更加直观, 底层实际调用parallelize方法
val rdd1: RDD[Int] = sc.makeRDD(seq)
// 执行collect,Spark才会真正执行
rdd1.collect().foreach(println)
// 3. 关闭环境
sc.stop()
}
}- 从外部存储(文件)创建RDD
由外部存储系统的数据集创建RDD包括:本地的文件系统,所有Hadoop支持的数据集,比如HDFS、HBase等。主要使用textFile()、wholeTextFiles()读取数据:
textFile(): 支持文件、目录读取,还支持通配符,比如datas/1*.txt, 还支持HDFS路径。wholeTextFiles(): 读取目录数据,读取的结果为元组,第一个元素表示文件路径,第二个元素表示文件内容。
使用textFile()读取目录数据,不能够知道数据读取来自具体那一份文件,因为textFile()是以行为单位读取数据,读取的数据是字符串,这时需要wholeTextFiles()。
object Rdd_InFile {
def main(args: Array[String]): Unit = {
// 1. 环境准备
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD_Demo2")
val sc = new SparkContext(sparkConf)
// 2. 创建RDD
// 从文件中创建RDD, 将文件中的数据作为处理的数据源,
// val rdd1: RDD[String] = sc.textFile("datas")
val rdd1: RDD[(String, String)] = sc.wholeTextFiles("datas")
rdd1.collect().foreach(println)
//3. 关闭环境
sc.stop()
}
}- 从其他RDD创建
主要是通过一个RDD运算完后,再产生新的RDD。 - 直接创建RDD(new)
使用new的方式直接构造RDD,一般由Spark框架自身使用。
3.2 RDD并行度与分区
默认情况下,Spark可以将一个作业切分多个任务后,发送给Executor节点并行计算,而能够并行计算的任务数量我们称之为并行度。这个数量可以在构建RDD时指定。
- 读取内存数据时,数据可以按照并行度的设定进行数据的分区操作。
object Rdd_part {
def main(args: Array[String]): Unit = {
//1. 环境准备
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD_Demo2")
val sc = new SparkContext(sparkConf)
// 2. 创建RDD & 分区
// makeRDD第二个参数表示分区的数量,第二个参数如果不设置,将使用默认值:defaultParallelism
// defaultParallelism来自Spark读取配置项spark.default.parallelism的值,如果没有配置将读取当前环境CPU的总核数
val rdd1: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5), 2)
// 将处理的数据保存成分区数据
rdd1.saveAsTextFile("output")
rdd1.collect().foreach(println)
//3. 关闭环境
sc.stop()
}
}运行结果,出现两个分区文件: 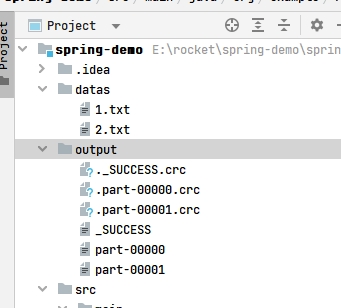 相关数据分区规则的Spark核心源码如下:
相关数据分区规则的Spark核心源码如下:
// length为数组长度, numSlices为并行度, (0,1), (2,3) ()
def positions(length: Long, numSlices: Int): Iterator[(Int, Int)] = {
(0 until numSlices).iterator.map { i =>
val start = ((i * length) / numSlices).toInt
val end = (((i + 1) * length) / numSlices).toInt
(start, end)
}
}以sc.makeRDD(List(1, 2, 3, 4, 5), 2)为例,positions函数返回分组是(0,1),(2,5),按照数组下标取数据,第一个分区是[1,2], 第二个分区为[3,4,5]。 2. 读取文件数据时,数据是按照Hadoop文件读取的规则进行切片分区。
object Rdd_InFile_part {
def main(args: Array[String]): Unit = {
// 1. 环境准备
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD_Demo3")
val sc = new SparkContext(sparkConf)
// 2. 创建RDD
// 从文件中创建RDD, 将文件中的数据作为处理的数据源,
/*
* textFile()不设定分区数就使用默认分区数。默认使用minPartitions
* minPartitions = math.min(defaultParallelism, 2), 结果不超过2的
* minPartitions 作为参数传入HadoopRDD, 底层文件读取和分区是由Hadoop完成的
* */
val rdd1: RDD[String] = sc.textFile("datas")
rdd1.collect().foreach(println)
//3. 关闭环境
sc.stop()
}
}运行结果: 切片规则和数据读取的规则具体Spark核心源码如下:
切片规则和数据读取的规则具体Spark核心源码如下:
def textFile(
path: String,
// 默认分片数 defaultMinPartitions不超过2
minPartitions: Int = defaultMinPartitions): RDD[String] = withScope {
assertNotStopped()
// 使用Hadoop中的TextInputFormat类实现分片
hadoopFile(path, classOf[TextInputFormat], classOf[LongWritable], classOf[Text],
minPartitions).map(pair => pair._2.toString).setName(path)Spark读取文件采用的是Hadoop方式读取,默认使用TextInputFormat类按行读取, 关于切片的逻辑如下:
public InputSplit[] getSplits(JobConf job, int numSplits) throws IOException {
......
long totalSize = 0;
for (FileStatus file: stats) {
if (file.isDirectory()) {
throw new IOException("Not a file: "+ file.getPath());
} else {
totalSize += file.getLen();
}
}
long goalSize = totalSize / (numSplits == 0 ? 1 : numSplits);
long minSize = Math.max(job.getLong(org.apache.hadoop.shaded.org.apache.hadoop.mapreduce.lib.input.
FileInputFormat.SPLIT_MINSIZE, 1), minSplitSize);
for (FileStatus file: files) {
Path path = file.getPath();
long length = file.getLen();
if (length != 0) {
......
if (isSplitable(fs, path)) {
long blockSize = file.getBlockSize();
long splitSize = computeSplitSize(goalSize, minSize, blockSize);
......
}
protected long computeSplitSize(long goalSize, long minSize, long blockSize) {
return Math.max(minSize, Math.min(goalSize, blockSize));
}提示
💡调用的是MapReduced中分区的功能(需要区分不是HDFS的切片,HDFS默认128M切片),而MapReduced中分区和文件大小没有关系,数据读取时以偏移量为单位,偏移量从0开始,按照偏移量分片时,如果两个分片偏移量都在同一行,第一个分片按行读取会直接读完这一行,第二个分片会直接从下一行读取,第二个分片不会按照偏移量在同一行不会被重复读取的。
文件的总的偏移量可以查看实际字节数: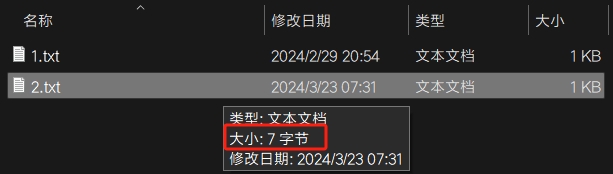 分区数量计算:
分区数量计算:
总大小totalSize = 7
每个分区大小goalSize = 7/2≈3byte
分区数=7/3=2···1
按照余数/分区大小的结果超过分区大小的0.1倍需要增加分区的原则,1/3>0.1, 需要分区数为2+1=3个分区