状态管理之状态介绍
1. Flink中的状态
在Flink中,算子任务可以分为无状态和有状态两种情况。无状态的算子任务只需要观察每个独立事件,根据当前输入的数据直接转换输出结果。我们之前讲到的基本转换算子,如map、filter、flatMap,计算时不依赖其他数据,就都属于无状态的算子。  而有状态的算子任务,则除当前数据之外,还需要一些其他数据来得到计算结果。这里的"其他数据",就是所谓的状态(state)。我们之前讲到的算子中,聚合算子、窗口算子都属于有状态的算子。有状态算子的一般处理流程,具体步骤如下:
而有状态的算子任务,则除当前数据之外,还需要一些其他数据来得到计算结果。这里的"其他数据",就是所谓的状态(state)。我们之前讲到的算子中,聚合算子、窗口算子都属于有状态的算子。有状态算子的一般处理流程,具体步骤如下:
(1)算子任务接收到上游发来的数据;
(2)获取当前状态;
(3)根据业务逻辑进行计算,更新状态;
(4)得到计算结果,输出发送到下游任务。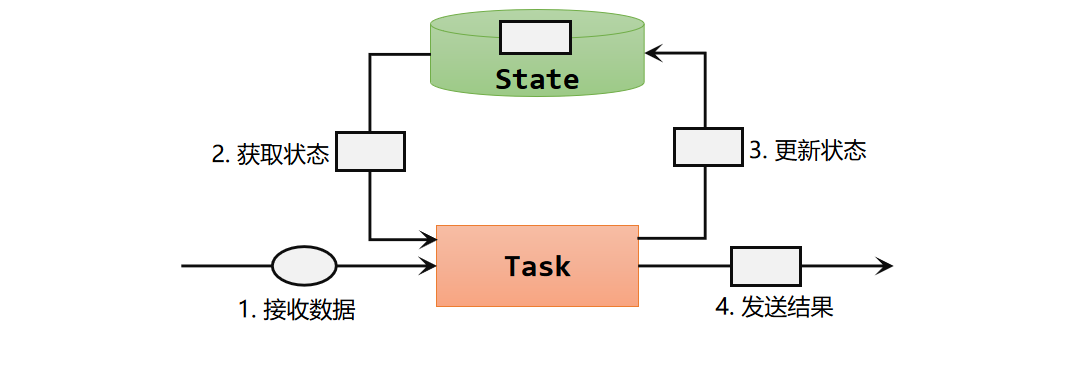
2. 状态的分类
2.1 托管状态(Managed State)和原始状态(Raw State)
Flink的状态有两种:托管状态(Managed State)和原始状态(Raw State)。托管状态就是由Flink统一管理的,状态的存储访问、故障恢复和重组等一系列问题都由Flink实现,我们只要调接口就可以;而原始状态则需要自定义实现功能,相当于就是在Flink状态管理之外开辟了一块内存,需要我们自己管理,自己实现状态的序列化和故障恢复。我们使用最多还是Flink托管状态(ps:托管状态就已经满足我们99%的使用场景)。
2.2 算子状态(Operator State)和按键分区状态(Keyed State)
我们又可以将托管状态分为两类:算子状态和按键分区状态。
- 算子状态
状态作用范围限定为当前的算子任务实例,也就是只对当前并行子任务实例有效。这就意味着对于一个并行子任务,占据了一个"分区",它所处理的所有数据都会访问到相同的状态,状态对于同一任务而言是共享的。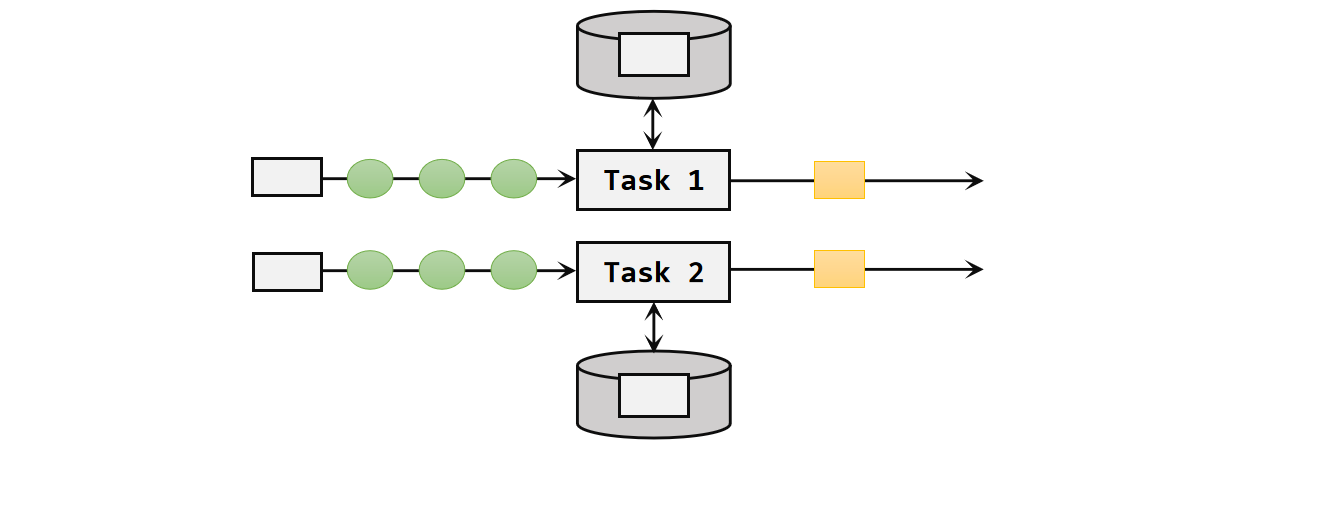 算子状态可以用在所有算子上,使用的时候其实就跟一个本地变量没什么区别——因为本地变量的作用域也是当前任务实例。在使用时,我们还需进一步实现CheckpointedFunction接口,而新版本Flink重新设计Source架构,需要继承SourceReaderBase抽象类。
算子状态可以用在所有算子上,使用的时候其实就跟一个本地变量没什么区别——因为本地变量的作用域也是当前任务实例。在使用时,我们还需进一步实现CheckpointedFunction接口,而新版本Flink重新设计Source架构,需要继承SourceReaderBase抽象类。 - 按键分区状态
ᅟᅠᅟᅠ按键分区状态和输入流中定义的键(key)有关,所以只能定义在按键分区流(KeyedStream)中,也就keyBy之后才可以使用。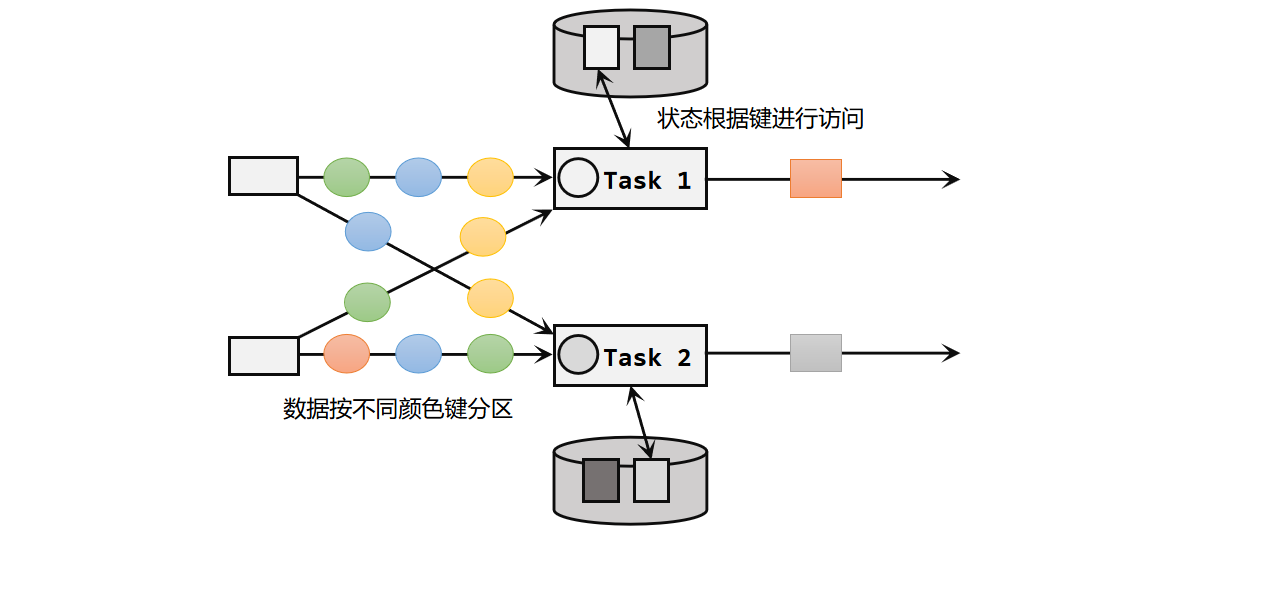 ᅟᅠᅟᅠ按键分区状态应用非常广泛。之前讲到的聚合算子必须在keyBy之后才能使用,就是因为聚合的结果是以Keyed State的形式保存的。另外也可以通过富函数类(Rich Function)来自定义Keyed State,因而即使是map、filter这样无状态的基本转换算子,我们也可以通过富函数类给它们"追加"Keyed State。比如RichMapFunction、RichFilterFunction。
ᅟᅠᅟᅠ按键分区状态应用非常广泛。之前讲到的聚合算子必须在keyBy之后才能使用,就是因为聚合的结果是以Keyed State的形式保存的。另外也可以通过富函数类(Rich Function)来自定义Keyed State,因而即使是map、filter这样无状态的基本转换算子,我们也可以通过富函数类给它们"追加"Keyed State。比如RichMapFunction、RichFilterFunction。
ᅟᅠᅟᅠ无论是Keyed State还是Operator State,它们都是在本地实例上维护的,也就是说每个并行子任务维护着对应的状态,算子的子任务之间状态是不共享的。
提示
在富函数中,我们可以调用getRuntimeContext()获取当前的运行时上下文(RuntimeContext),进而获取到访问状态的句柄;这种富函数中自定义的状态也是Keyed State。从这个角度讲,Flink中所有的算子都可以是有状态的。