环境搭建
 Table API和SQL是最上层的API,Flink是批流统一的处理框架,无论是批处理(DataSet API)还是流处理(DataStream API),在上层应用中都可以直接使用Table API或者SQL来实现;SQL API是基于SQL标准的Apache Calcite框架实现的,可通过纯SQL来开发和运行一个Flink任务。
Table API和SQL是最上层的API,Flink是批流统一的处理框架,无论是批处理(DataSet API)还是流处理(DataStream API),在上层应用中都可以直接使用Table API或者SQL来实现;SQL API是基于SQL标准的Apache Calcite框架实现的,可通过纯SQL来开发和运行一个Flink任务。
1. sql-client准备
使用Flink提供的sql-client直接进行Flink SQL语法操作
1.1 基于yarn-session模式
sh
[jack@hadoop102 ~]$ cd /opt/module/flink-1.17.2/
[jack@hadoop102 flink-1.17.2]$ ./bin/yarn-session.sh -d访问hadoop集群的resourcemanager的ui界面: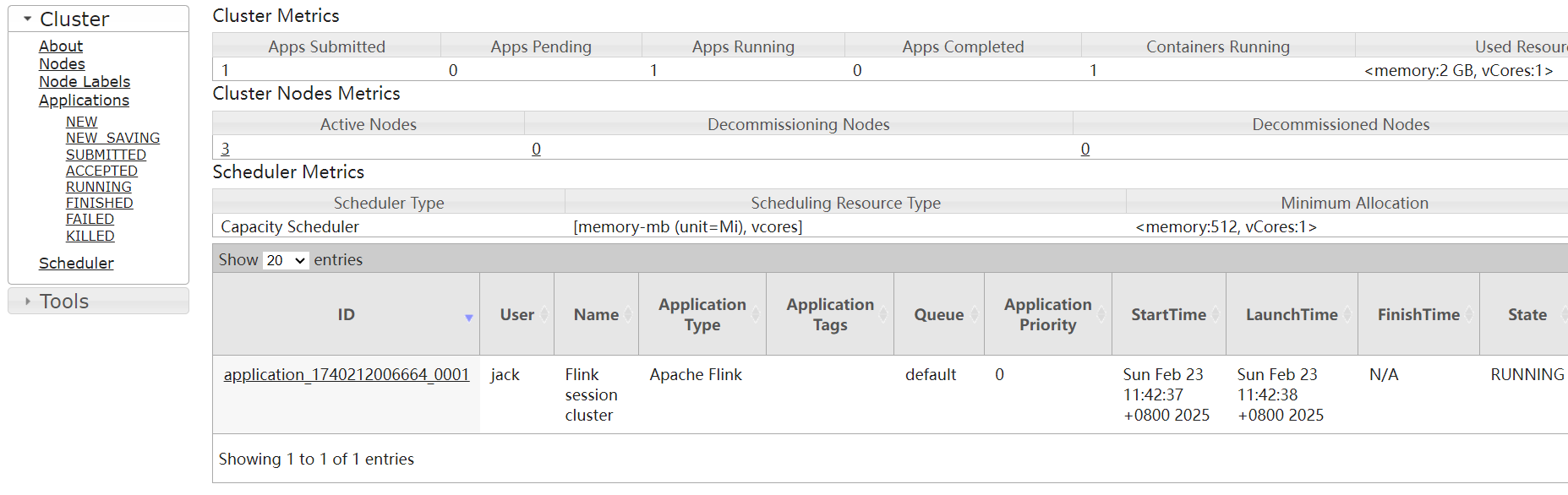 可以看到当前Flink提交了一个flink应用在上面运行。
可以看到当前Flink提交了一个flink应用在上面运行。
sh
## 启动Flink的sql-client
[jack@hadoop102 flink-1.17.2]$ bin/sql-client.sh embedded -s yarn-session1.2 常用配置
- 结果显示模式
sql
-- 默认table,还可以设置为tableau、changelog
SET sql-client.execution.result-mode=tableau;- 执行环境
sql
-- 默认streaming,也可以设置batch
SET execution.runtime-mode=streaming;- 默认并行度
sql
SET parallelism.default=1;- 设置状态TTL
sql
SET table.exec.state.ttl=1000;- 通过sql文件初始化
sh
vim conf/sql-client-init.sql
## 添加如下内容
SET sql-client.execution.result-mode=tableau;
CREATE DATABASE mydatabase;启动时,指定sql文件
sh
bin/sql-client.sh embedded -s yarn-session -i conf/sql-client-init.sql2. 使用savepoint
2.1 查看job列表
sql
SHOW JOBS;
2.2 停止作业,触发savepoint
sql
SET state.checkpoints.dir='hdfs://hadoop102:8020/chk';
SET state.savepoints.dir='hdfs://hadoop102:8020/sp';
STOP JOB '66502c063c3f3b8678a9c96018aa038b' WITH SAVEPOINT;运行结果: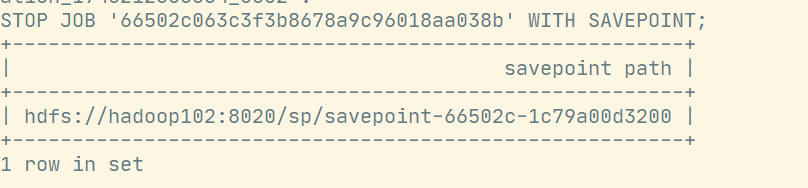
2.3 从savepoint恢复
sql
-- 设置从savepoint恢复的路径
set execution.savepoint.path=' hdfs://hadoop102:8020/sp/savepoint-66502c-1c79a00d3200';
-- 之后直接提交sql,就会从savepoint恢复
insert into t4 select * from source;
--允许跳过无法还原的保存点状态
set 'execution.savepoint.ignore-unclaimed-state' = 'true';2.4 恢复后重置路径
指定execution.savepoint.path后,将影响后面执行的所有DML语句,可以使用RESET命令重置这个配置选项。
sql
RESET execution.savepoint.path;