查询
1. 数据准备
1.1 创建数据生成器源表
CREATE TABLE source (
id INT,
ts BIGINT,
vc INT
) WITH (
'connector' = 'datagen',
-- 每秒生成1条
'rows-per-second'='1',
-- random表示随机数,[1,10)范围
'fields.id.kind'='random',
'fields.id.min'='1',
'fields.id.max'='10',
'fields.ts.kind'='sequence',
-- sequence表示序列从1自增
'fields.ts.start'='1',
'fields.ts.end'='1000000',
'fields.vc.kind'='random',
'fields.vc.min'='1',
'fields.vc.max'='100'
);
CREATE TABLE sink (
id INT,
ts BIGINT,
vc INT
) WITH (
'connector' = 'print'
);提示
connector=datagen时,kind属性可以省略,所以source表可以写成如下:
CREATE TABLE source (
id INT,
ts BIGINT,
vc INT
) WITH (
'connector' = 'datagen',
'rows-per-second'='1',
-- max,min就告诉flink使用random策略
'fields.id.min'='1',
'fields.id.max'='10',
-- start,end就告诉flink使用sequence策略
'fields.ts.start'='1',
'fields.ts.end'='1000000',
'fields.vc.min'='1',
'fields.vc.max'='100'
);1.2 查询源表
select * from source;
1.2 插入sink表并查询
INSERT INTO sink select * from source;
select * from sink;2. With子句
WITH提供了一种编写辅助语句的方法,以便在较大的查询中使用。这些语句通常被称为公共表表达式(Common Table Expression, CTE),可以认为它们定义了仅为一个查询而存在的临时视图。
2.1 语法
WITH <with_item_definition> [ , ... ]
SELECT ... FROM ...;
<with_item_defintion>:
with_item_name (column_name[, ...n]) AS ( <select_query> )比如查询:
-- with后面不要加分号;
WITH source_with_total AS (
SELECT id, vc+10 AS total
FROM source
)
SELECT id, SUM(total)
FROM source_with_total
GROUP BY id;3. SELECT&WHERE子句
3.1 语法
SELECT select_list FROM table_expression [ WHERE boolean_expression ]4. SELECT DISTINCT子句
-- 用作根据 key 进行数据去重
select count(*) cnt, sum(ts) sum_ts from source;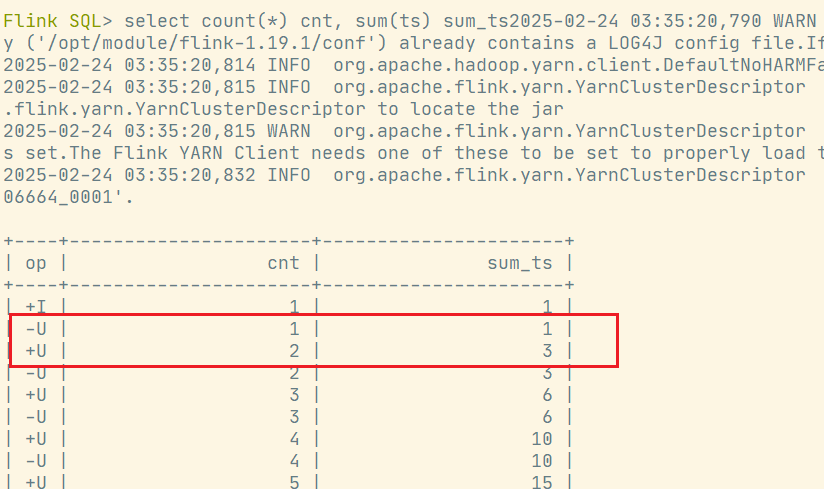 对于流查询,计算查询结果所需的状态可能无限增长。状态大小取决于不同行数。可以设置适当的状态生存时间(TTL)的查询配置,以防止状态过大。但是,这可能会影响查询结果的正确性。如某个key的数据过期从状态中删除了,那么下次再来这么一个 key,由于在状态中找不到,就又会输出一遍。
对于流查询,计算查询结果所需的状态可能无限增长。状态大小取决于不同行数。可以设置适当的状态生存时间(TTL)的查询配置,以防止状态过大。但是,这可能会影响查询结果的正确性。如某个key的数据过期从状态中删除了,那么下次再来这么一个 key,由于在状态中找不到,就又会输出一遍。
5. 分组聚合
SQL中一般所说的聚合我们都很熟悉,主要是通过内置的一些聚合函数来实现的,比如SUM()、MAX()、MIN()、AVG()以及COUNT()。它们的特点是对多条输入数据进行计算,得到一个唯一的值,属于"多对一"的转换。 我们可以通过GROUP BY子句来指定分组的键(key),从而对数据按照某个字段做一个分组统计。
SELECT vc, COUNT(*) as cnt FROM source GROUP BY vc;这种聚合方式,就叫作"分组聚合"(group aggregation)。想要将结果表转换成流或输出到外部系统,必须采用撤回流(retract stream)或更新插入流(upsert stream)的编码方式;如果在代码中直接转换成DataStream打印输出,需要调用toChangelogStream()。
5.1 多维分析
Group聚合也支持Grouping sets 、Rollup 、Cube,如下案例是Grouping sets:
SELECT
supplier_id
, rating
, product_id
, COUNT(*)
FROM (
VALUES
('supplier1', 'product1', 4),
('supplier1', 'product2', 3),
('supplier2', 'product3', 3),
('supplier2', 'product4', 4)
)
-- 供应商id、产品id、评级
AS Products(supplier_id, product_id, rating)
GROUP BY GROUPING SETS(
(supplier_id, product_id, rating),
(supplier_id, product_id),
(supplier_id, rating),
(supplier_id),
(product_id, rating),
(product_id),
(rating),
()
);运行结果: 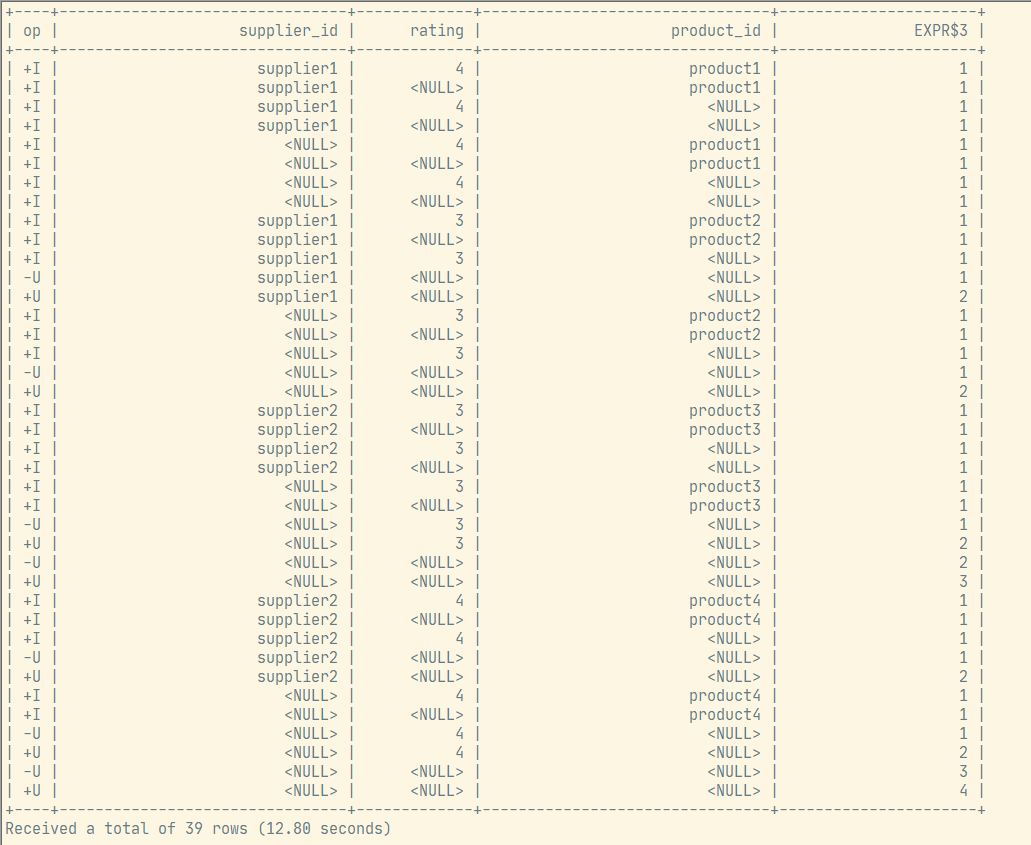
6. 分组窗口聚合
从1.13版本开始,分组窗口聚合已经标记为过时,鼓励使用更强大、更有效的窗口TVF聚合,在这里简单做个介绍。SQL中只支持基于时间的窗口,不支持基于元素个数的窗口。
| 分组窗口函数 | 描述 |
|---|---|
| TUMBLE(time_attr, interval) | 滚动窗口(时间字段,窗口长度) |
| HOP(time_attr, interval, interval) | 滑动窗口(时间字段,滑动步长,窗口长度) |
| SESSION(time_attr, interval) | 会话窗口(时间字段,会话的间隔) |
| TUMBLE_START(time_attr, interval) | 窗口的起始时间 |
| TUMBLE_END(time_attr, interval) | 窗口的结束时间 |
6.1 准备数据
CREATE TABLE ws (
id INT,
vc INT,
pt AS PROCTIME(), --处理时间
et AS cast(CURRENT_TIMESTAMP as timestamp(3)), --事件时间
WATERMARK FOR et AS et - INTERVAL '5' SECOND --watermark
) WITH (
'connector' = 'datagen',
'rows-per-second' = '10',
'fields.id.min' = '1',
'fields.id.max' = '3',
'fields.vc.min' = '1',
'fields.vc.max' = '100'
);查看建表情况:
Flink SQL> desc ws;
+------+-----------------------------+-------+-----+--------------------------------------------+----------------------------+
| name | type | null | key | extras | watermark |
+------+-----------------------------+-------+-----+--------------------------------------------+----------------------------+
| id | INT | TRUE | | | |
| vc | INT | TRUE | | | |
| pt | TIMESTAMP_LTZ(3) *PROCTIME* | FALSE | | AS PROCTIME() | |
| et | TIMESTAMP(3) *ROWTIME* | FALSE | | AS CAST(CURRENT_TIMESTAMP AS TIMESTAMP(3)) | `et` - INTERVAL '5' SECOND |
+------+-----------------------------+-------+-----+--------------------------------------------+----------------------------+
4 rows in set6.2 滚动窗口示例
select
id,
sum(vc) sumVc,
TUMBLE_START(et, INTERVAL '5' SECOND) wstart,
TUMBLE_END(et, INTERVAL '5' SECOND) wsend
from ws
group by id, TUMBLE(et, INTERVAL '5' SECOND);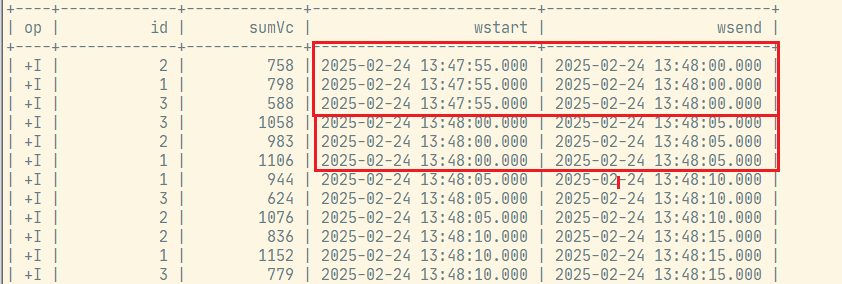
6.3 滑动窗口
select
id,
hop_start(et, interval '3' second, interval '5' second) wsstart,
hop_end(et, interval '3' second, interval '5' second) wsend,
sum(vc) sumVc
from ws
group by id, hop(et, interval '3' second, interval '5' second);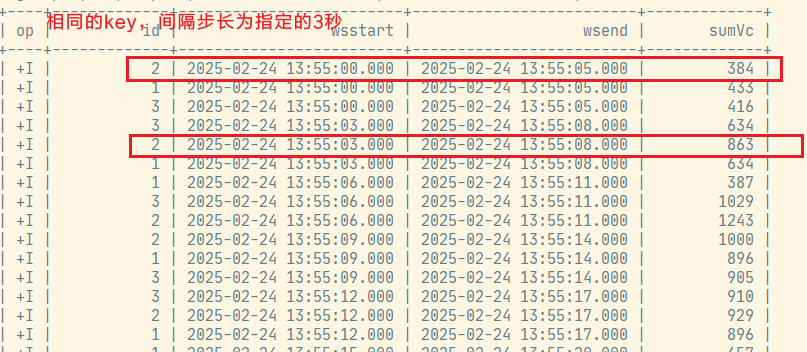
6.4 会话窗口
select
id ,
session_start(et, interval '5' second) wsstart,
session_end(et, interval '5' second) wsend,
sum(vc) sumVc
from ws
group by id, session(et, interval '5' second); 结果出不来,是因为session设置的5s后过期,但是数据产生是每秒产生,所有不会过期session。
结果出不来,是因为session设置的5s后过期,但是数据产生是每秒产生,所有不会过期session。
7. 窗口表值函数(TVF)聚合
对比GroupWindow,TVF窗口更有效和强大。包括:
- 提供更多的性能优化手段
- 支持GroupingSets语法
- 可以在window聚合中使用TopN
- 提供累积窗口
对于窗口表值函数,窗口本身返回的是就是一个表,所以窗口会出现在FROM后面,GROUP BY后面的则是窗口新增的字段window_start和window_end。
-- 固定写法,不再是from+表名
FROM TABLE(
窗口类型(TABLE 表名, DESCRIPTOR(时间字段),INTERVAL时间…)
)
GROUP BY [window_start,][window_end,] --可选7.1 滚动窗口
select
id ,
sum(vc) sumVc,
window_start,
window_end
from table(
tumble(table ws, descriptor(et), interval '5' second)
)
group by id, window_start, window_end;执行结果,可见5s滚动: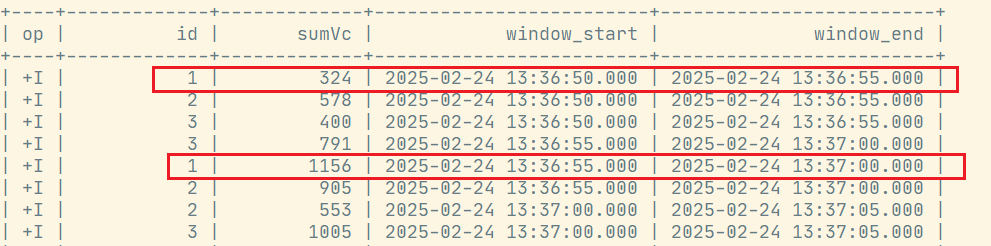
7.2 滑动窗口
要求: 窗口长度=滑动步长的整数倍(底层会优化成多个小滚动窗口)
select
id,
sum(vc) sumVc,
window_start,
window_end
from table (
hop(table ws, descriptor(et), interval '3' second, interval '6' second)
)
group by id, window_start, window_end;执行结果: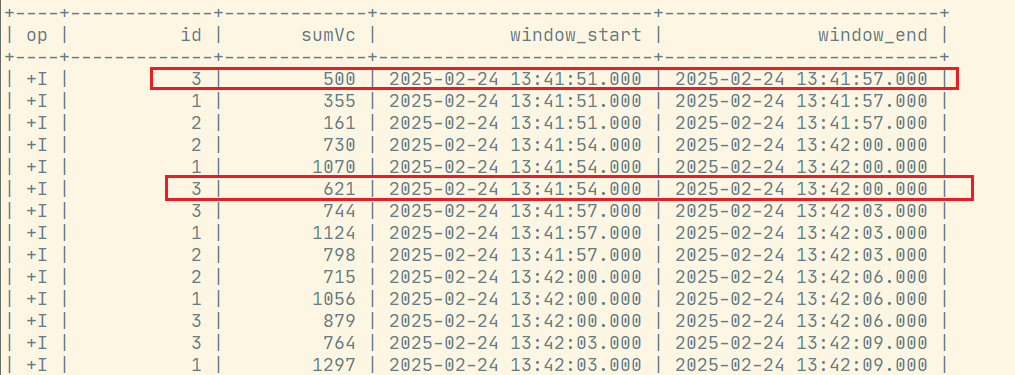
7.3 会话窗口
select
id,
sum(vc) sumVc,
window_start,
window_end
from table (
session(table ws, descriptor(et), interval '6' second)
)
group by id, window_start, window_end;执行结果: 结果出不来,是因为session设置的6s后过期,但是数据产生是每秒产生,所有不会过期session。
结果出不来,是因为session设置的6s后过期,但是数据产生是每秒产生,所有不会过期session。
7.4 累积窗口
累积窗口会在一定的统计周期内进行累积计算。累积窗口中有两个核心的参数:最大窗口长度(max window size)和累积步长(step)。累积窗口可以认为是首先开一个最大窗口大小的滚动窗口,然后根据用户设置的触发的时间间隔将这个滚动窗口拆分为多个窗口,这些窗口具有相同的窗口起点和不同的窗口终点。 注意: 窗口最大长度 = 累积步长的整数倍
select
id,
sum(vc) sumVc,
window_start,
window_end
from table (
cumulate(table ws, descriptor(et),interval '3' second, interval '6' second)
)
group by id, window_start, window_end;执行结果: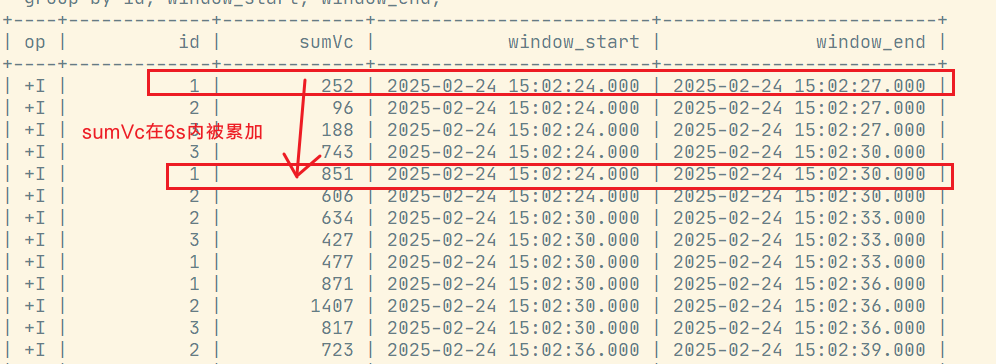
7.5 grouping sets多维分析
SELECT
window_start,
window_end,
id ,
SUM(vc) sumVC
FROM TABLE(
TUMBLE(TABLE ws, DESCRIPTOR(et), INTERVAL '5' SECONDS))
GROUP BY window_start, window_end,
rollup( (id) )
-- cube( (id) )
-- grouping sets( (id),() )
;8. Over聚合
OVER聚合为一系列有序行的每个输入行计算一个聚合值。与GROUP BY聚合相比,OVER聚合不会将每个组的结果行数减少为一行。相反,OVER聚合为每个输入行生成一个聚合值。
8.1 语法
SELECT
agg_func(agg_col) OVER (
[PARTITION BY col1[, col2, ...]]
ORDER BY time_col
range_definition),
...
FROM ...ORDER BY:必须是时间戳列(事件时间、处理时间),只能升序。PARTITION BY:标识了聚合窗口的聚合粒度。range_definition:这个标识聚合窗口的聚合数据范围,在Flink中有两种指定数据范围的方式。第一种为按照行数聚合,第二种为按照时间区间聚合。
8.2 按照时间区间聚合
统计每个传感器前10秒到现在收到的水位数据条数:
SELECT
id,
et,
vc,
count(vc) OVER (
PARTITION BY id
ORDER BY et
RANGE BETWEEN INTERVAL '10' SECOND PRECEDING AND CURRENT ROW
) AS cnt
FROM ws也可以用WINDOW子句来在SELECT外部单独定义一个OVER窗口,可以多次使用:
SELECT
id,
et,
vc,
count(vc) OVER w AS cnt,
sum(vc) OVER w AS sumVC
FROM ws
WINDOW w AS (
PARTITION BY id
ORDER BY et
RANGE BETWEEN INTERVAL '10' SECOND PRECEDING AND CURRENT ROW
);运行结果: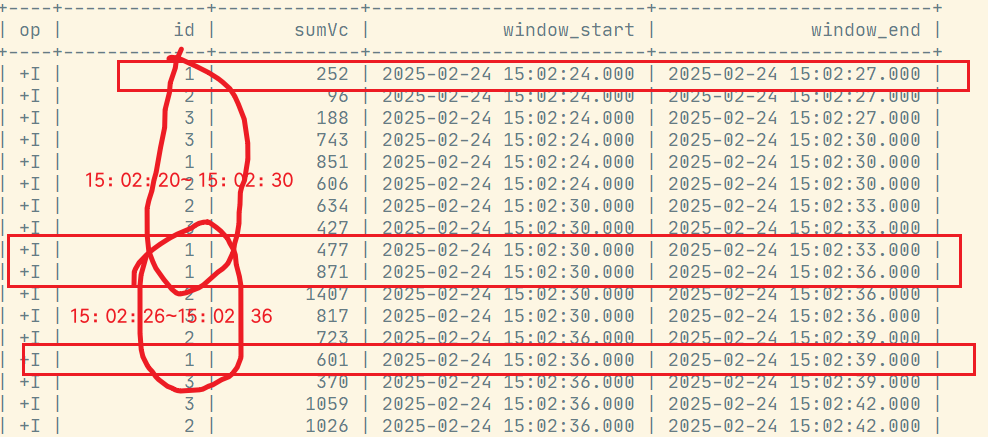
8.3 按照行数聚合
统计每个传感器前5条到现在数据的平均水位
SELECT
id,
et,
vc,
avg(vc) OVER (
PARTITION BY id
ORDER BY et
ROWS BETWEEN 5 PRECEDING AND CURRENT ROW
) AS avgVC
FROM ws;
---也可以用WINDOW子句来在SELECT外部单独定义一个OVER窗口:
SELECT
id,
et,
vc,
avg(vc) OVER w AS avgVC,
count(vc) OVER w AS cnt
FROM ws
WINDOW w AS (
PARTITION BY id
ORDER BY et
ROWS BETWEEN 5 PRECEDING AND CURRENT ROW
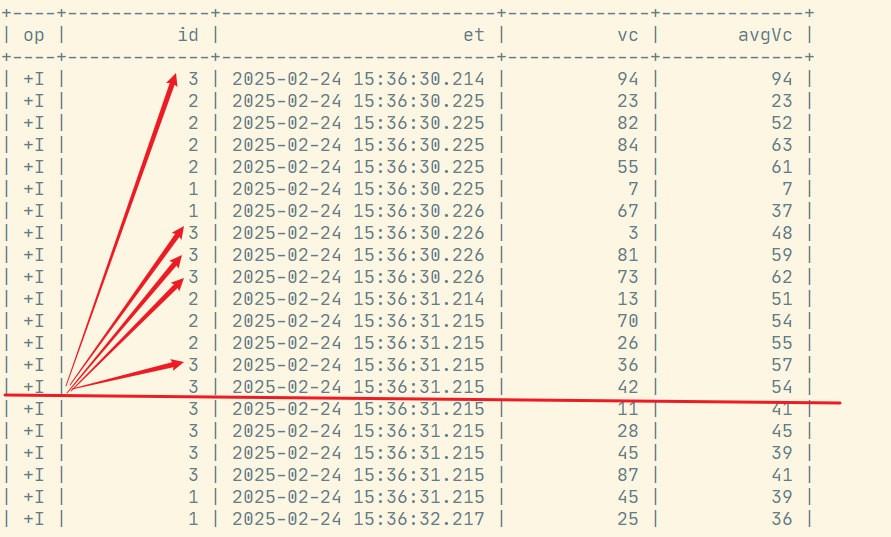
)
9. 特殊语法——TOP-N
目前在Flink SQL中没有能够直接调用的TOP-N函数,而是提供了稍微复杂些的变通实现方法,是固定写法,特殊支持的over用法。
9.1 语法
SELECT [column_list]
FROM (
SELECT [column_list],
ROW_NUMBER() OVER ([PARTITION BY col1[, col2...]]
ORDER BY col1 [asc|desc][, col2 [asc|desc]...]) AS rownum
FROM table_name)
WHERE rownum <= N [AND conditions]- ROW_NUMBER() :标识TopN排序子句
- PARTITION BY col1[, col2...] :标识分区字段,代表按照这个 col 字段作为分区粒度对数据进行排序取 topN,比如下述案例中的partition by key ,就是根据需求中的搜索关键词(key)做为分区
- ORDER BY col1 [asc|desc][, col2 [asc|desc]...] :标识 TopN 的排序规则,是按照哪些字段、顺序或逆序进行排序,可以不是时间字段,也可以降序(TopN特殊支持)
- WHERE rownum <= N:这个子句是一定需要的,只有加上了这个子句,Flink 才能将其识别为一个TopN 的查询,其中N代表TopN的条目数
- [AND conditions]:其他的限制条件也可以加上
9.2 应用TopN
取每个传感器最高的3个水位值:
select
id,
et,
vc,
rownum
from
(
select
id,
et,
vc,
row_number() over(
partition by id
order by vc desc
) as rownum
from ws
)
where rownum<=3;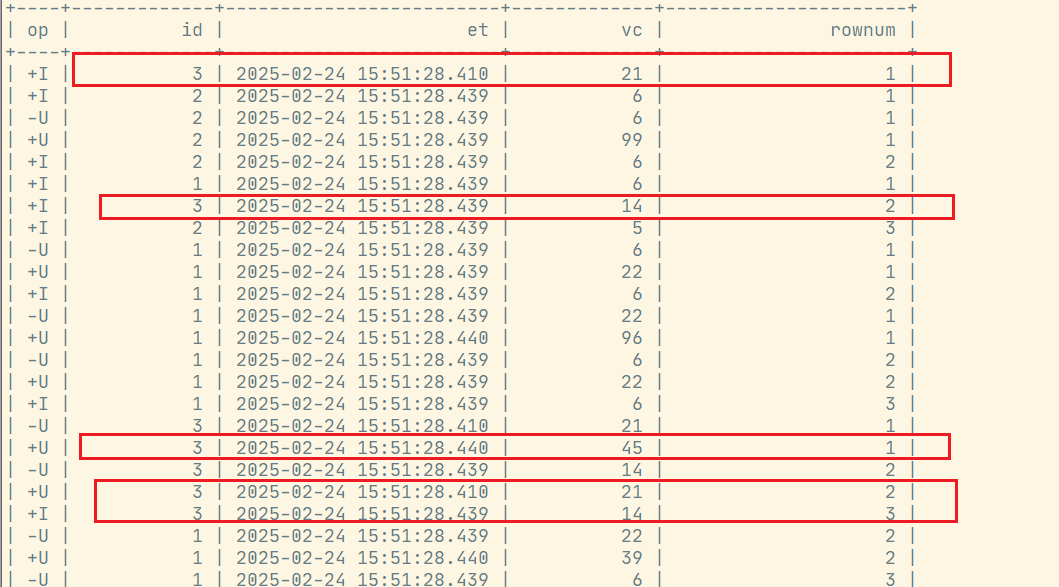
10. 特殊语法——Deduplication去重
去重,也即上文介绍到的TopN 中row_number = 1的场景,但是这里有一点不一样在于其排序字段一定是时间属性列,可以降序,不能是其他非时间属性的普通列。在row_number = 1并且排序字段是普通列时,planner会翻译成TopN算子;如果排序字段是时间属性列,那么planner会翻译成Deduplication。可以从webui看出是翻译成哪种算子。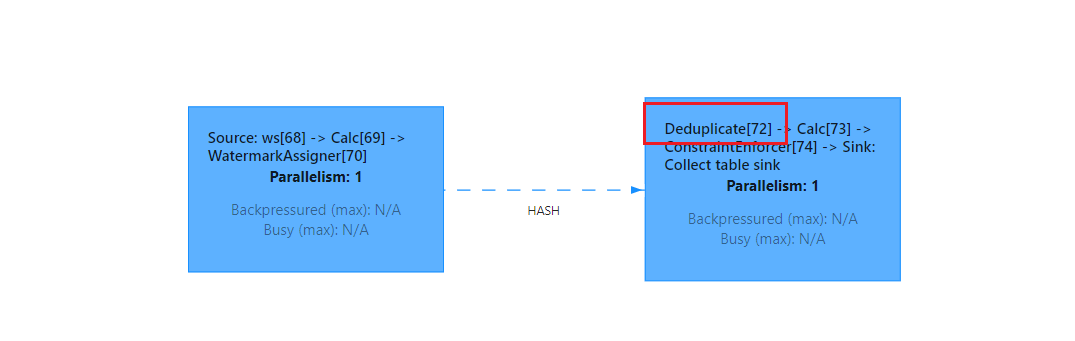
10.1 语法
SELECT [column_list]
FROM (
SELECT [column_list],
ROW_NUMBER() OVER ([PARTITION BY col1[, col2...]]
ORDER BY time_attr [asc|desc]) AS rownum
FROM table_name)
WHERE rownum = 110.2 应用Deduplication去重
select
id, et, vc, rownum
from (
select
id,
et,
vc,
row_number() over(partition by id order by pt desc) as rownum
from ws
) where rownum=1;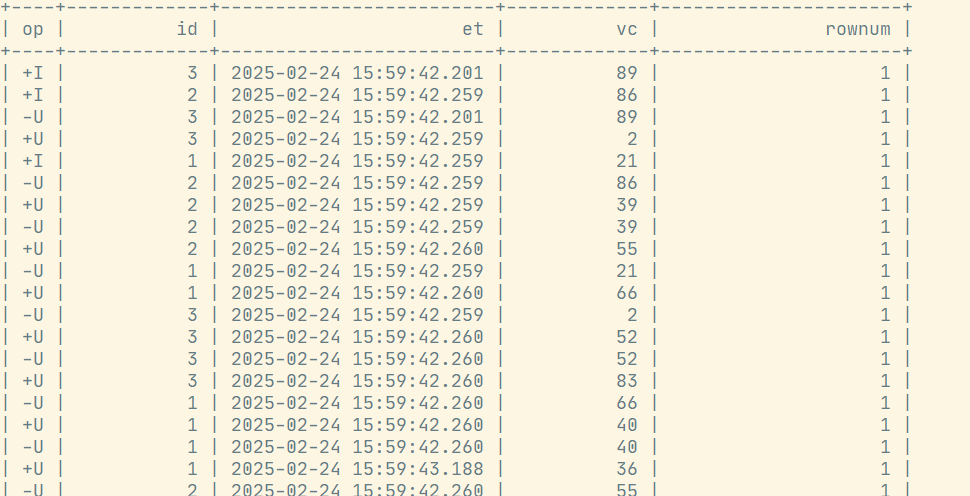 排序方式推荐使用asc, 使用desc会对性能有影响,如上图会出现大量的-U,+U操作。
排序方式推荐使用asc, 使用desc会对性能有影响,如上图会出现大量的-U,+U操作。
11. 联结(Join)查询
在Flink SQL中,同样支持各种灵活的联结(Join)查询。Flink SQL中的联结查询大体上也可以分为两类:SQL原生的联结查询方式,和流处理中特有的联结查询。
11.1 常规联结查询
与标准SQL一致,Flink SQL的常规联结也可以分为内联结(INNER JOIN)和外联结(OUTER JOIN),区别在于结果中是否包含不符合联结条件的行。Regular Join包含以下几种(以L作为左流中的数据标识,R作为右流中的数据标识):
- Inner Join:流任务中,只有两条流Join到才输出,输出+[L, R]。
- Left Join:流任务中,左流数据到达之后,无论有没有Join到右流的数据,都会输出(Join到输出+[L, R] ,没Join到输出+[L, null]),如果右流之后数据到达之后,发现左流之前输出过没有Join到的数据,则会发起回撤流,先输出 -[L, null],然后输出+[L, R]。
- Right Join:有Left Join一样,左表和右表的执行逻辑完全相反。
- Full Join:流任务中,左流或者右流的数据到达之后,无论有没有Join到另外一条流的数据,都会输出(对右流来说:Join到输出+[L, R] ,没Join到输出+[null, R] ;对左流来说:Join到输出+[L, R] ,没Join到输出+[L, null])。如果一条流的数据到达之后,发现之前另一条流之前输出过没有Join到的数据,则会发起回撤流(左流数据到达为例:回撤-[null, R],输出+[L, R] ,右流数据到达为例:回撤-[L, null] ,输出+[L, R]。
提示
- 实时Regular Join可以不是等值 join 。等值 join和非等值 join区别在于, 等值join数据shuffle策略是 Hash,会按照Join on中的等值条件作为id发往对应的下游; 非等值join数据shuffle策略是Global,所有数据发往一个并发,按照非等值条件进行关联。
- 流的上游是无限的数据,所以要做到关联的话,Flink会将两条流的所有数据都存储在State中,所以Flink任务的 State会无限增大,因此你需要为State配置合适的TTL,以防止State过大。
CREATE TABLE ws1 (
id INT,
vc INT,
pt AS PROCTIME(), --处理时间
et AS cast(CURRENT_TIMESTAMP as timestamp(3)), --事件时间
WATERMARK FOR et AS et - INTERVAL '0.001' SECOND --watermark
) WITH (
'connector' = 'datagen',
'rows-per-second' = '1',
'fields.id.min' = '3',
'fields.id.max' = '5',
'fields.vc.min' = '1',
'fields.vc.max' = '100'
);
-- 等值内联结
SELECT ws.id id, ws1.id as id1
FROM ws
INNER JOIN ws1
ON ws.id = ws1.id;
-- 等值外联结
SELECT ws.id id, ws1.id as id1
FROM ws
LEFT JOIN ws1
ON ws.id = ws1.id;
SELECT ws.id id, ws1.id as id1
FROM ws
RIGHT JOIN ws1
ON ws.id = ws1.id
SELECT ws.id id, ws1.id as id1
FROM ws
FULL OUTER JOIN ws1
ON ws.id = ws.id11.2 间隔联结查询
我们曾经学习过DataStream API中的双流Join,包括窗口联结(window join)和间隔联结(interval join)。两条流的Join就对应着SQL中两个表的Join,这是流处理中特有的联结方式。目前Flink SQL还不支持窗口联结,而间隔联结则已经实现。
间隔联结(Interval Join)返回的,同样是符合约束条件的两条中数据的笛卡尔积。只不过这里的"约束条件"除了常规的联结条件外,还多了一个时间间隔的限制。具体语法有以下要点:
- 两表的联结: 间隔联结不需要用JOIN关键字,直接在FROM后将要联结的两表列出来就可以,用逗号分隔。
- 联结条件: 联结条件用WHERE子句来定义,用一个等值表达式描述。
- 时间间隔限制: 在WHERE子句中,联结条件后用AND追加一个时间间隔的限制条件;具体定义方式有下面三种,这里分别用ltime和rtime表示左右表中的时间字段:
- ltime = rtime
- ltime >= rtime AND ltime < rtime + INTERVAL '10' MINUTE
- ltime BETWEEN rtime - INTERVAL '10' SECOND AND rtime + INTERVAL '5' SECOND
SELECT *
FROM ws,ws1
WHERE ws.id = ws1. id
AND ws.et BETWEEN ws1.et - INTERVAL '2' SECOND AND ws1.et + INTERVAL '2' SECOND;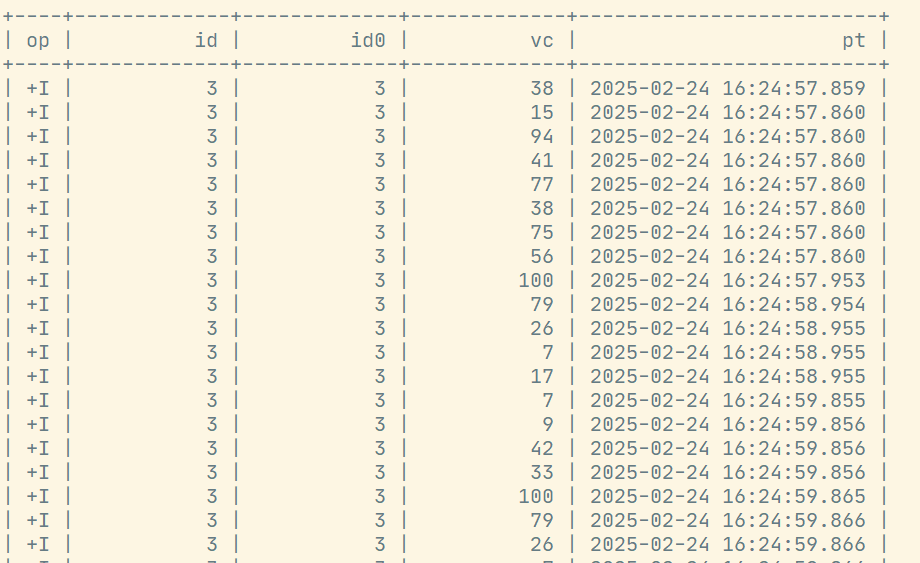 查看Flink页面:
查看Flink页面: 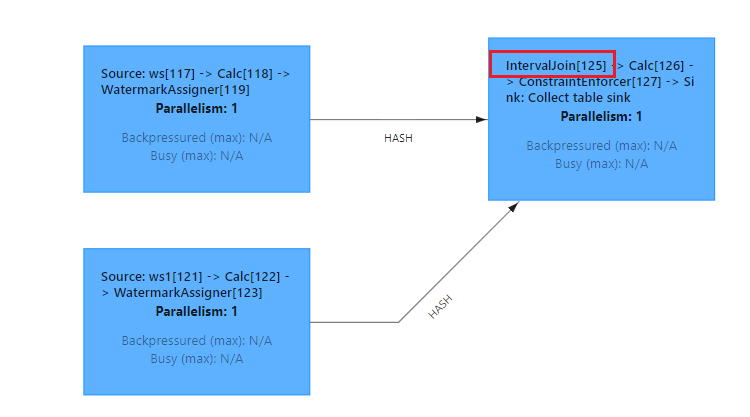
11.3 维表联结查询
Lookup Join其实就是维表Join,实时获取外部系统缓存的Join,Lookup的意思就是实时查找。 上面说的这几种Join都是流与流之间的Join,而Lookup Join是流与Redis,Mysql,HBase这种外部存储介质的 Join。仅支持处理时间字段。
比如维表在mysql,维表join的写法如下:
CREATE TABLE Customers (
id INT,
name STRING,
country STRING,
zip STRING
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://hadoop102:3306/customerdb',
'table-name' = 'customers'
);
-- order表每来一条数据,都会去mysql的customers表查找维度数据
SELECT o.order_id, o.total, c.country, c.zip
FROM Orders AS o
-- 固定写法
JOIN Customers FOR SYSTEM_TIME AS OF o.proc_time AS c
ON o.customer_id = c.id;12. Order by和limit
12.1 order by
支持 Batch\Streaming,但在实时任务中一般用的非常少。Order By子句中必须要有时间属性字段,并且必须写在最前面且为升序。
SELECT * FROM ws ORDER BY et, id desc;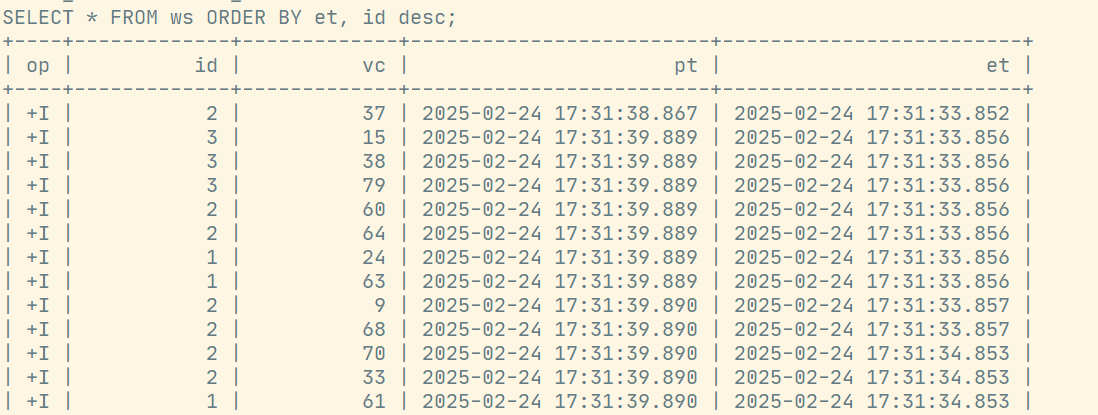

12.2 limit
SELECT * FROM ws LIMIT 3;
13. SQL Hints
在执行查询时,可以在表名后面添加SQL Hints来临时修改表属性,对当前job生效。
select * from ws1/*+ OPTIONS('rows-per-second'='10')*/;14. 集合操作
14.1 UNION和UNION ALL
UNION:将集合合并并且去重。
UNION ALL:将集合合并,不做去重。
(SELECT id FROM ws) UNION (SELECT id FROM ws1);
(SELECT id FROM ws) UNION ALL (SELECT id FROM ws1);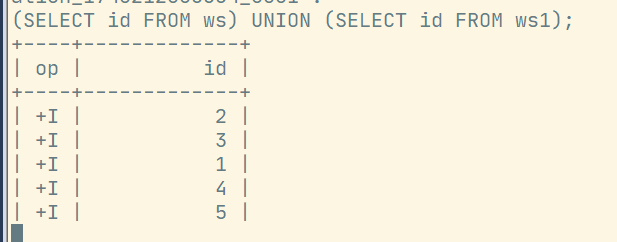
14.2 Intersect和Intersect All
Intersect:交集并且去重。
Intersect ALL:交集不做去重。
(SELECT id FROM ws) INTERSECT (SELECT id FROM ws1);
(SELECT id FROM ws) INTERSECT ALL (SELECT id FROM ws1);
14.3 Except和Except All
Except:差集并且去重。
Except ALL:差集不做去重。
(SELECT id FROM ws) EXCEPT (SELECT id FROM ws1);
(SELECT id FROM ws) EXCEPT ALL (SELECT id FROM ws1);
14.4 In子查询
In子查询的结果集只能有一列
SELECT id, vc
FROM ws
WHERE id IN (SELECT id FROM ws1);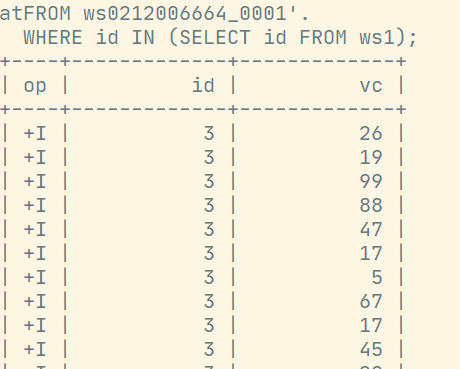
15. 系统函数
系统函数(System Functions)也叫内置函数(Built-in Functions),Flink SQL提供了大量的系统函数,几乎支持所有的标准SQL中的操作,这为我们使用SQL编写流处理程序提供了极大的方便。Flink SQL中的系统函数又主要可以分为两大类:标量函数(Scalar Functions)和聚合函数(Aggregate Functions)。
15.1 标量函数(Scalar Functions)
标量函数指的就是只对输入数据做转换操作、返回一个值的函数。
- 比较函数(Comparison Functions)
比较函数其实就是一个比较表达式,用来判断两个值之间的关系,返回一个布尔类型的值。这个比较表达式可以是用 <、>、= 等符号连接两个值,也可以是用关键字定义的某种判断。 - 逻辑函数(Logical Functions)
逻辑函数就是一个逻辑表达式,也就是用与(AND)、或(OR)、非(NOT)将布尔类型的值连接起来,也可以用判断语句(IS、IS NOT)进行真值判断;返回的还是一个布尔类型的值。 - 算术函数(Arithmetic Functions)
进行算术计算的函数,包括用算术符号连接的运算,和复杂的数学运算。 - 字符串函数(String Functions)
进行字符串处理的函数。 - 时间函数(Temporal Functions) 进行与时间相关操作的函数。
15.2 聚合函数(Aggregate Functions)
聚合函数是以表中多个行作为输入,提取字段进行聚合操作的函数,会将唯一的聚合值作为结果返回。 标准SQL中常见的聚合函数Flink SQL都是支持的,目前也在不断扩展,为流处理应用提供更强大的功能。比如COUNT(*),SUM([ALL|DISTINCT] expression) ,RANK(),ROW_NUMBER()。
16. Module操作
Module允许Flink扩展函数能力。它是可插拔的,Flink官方本身已经提供了一些Module,用户也可以编写自己的Module。目前Flink包含了以下三种Module:
- CoreModule:CoreModule是Flink内置的Module,其包含了目前Flink内置的所有UDF,Flink默认开启的 Module就是CoreModule,我们可以直接使用其中的UDF
- HiveModule:HiveModule可以将Hive内置函数作为Flink的系统函数提供给SQL\Table API用户进行使用,比如get_json_object这类Hive内置函数(Flink默认的CoreModule是没有的)
- 用户自定义 Module:用户可以实现Module接口实现自己的UDF扩展Module
使用LOAD子句去加载Flink SQL体系内置的或者用户自定义的Module,UNLOAD子句去卸载Flink SQL体系内置的或者用户自定义的Module。
16.1 语法
-- 加载
LOAD MODULE module_name [WITH ('key1' = 'val1', 'key2' = 'val2', ...)]
-- 卸载
UNLOAD MODULE module_name
-- 查看
SHOW MODULES;
SHOW FULL MODULES;Flink只会解析已经启用了的Module。那么当两个Module中出现两个同名的函数且都启用时, Flink会根据加载 Module的顺序进行解析,结果就是会使用顺序为第一个的Module的UDF,可以使用下面语法更改顺序:
USE MODULE hive,core;16.2 使用Hive Module
加载官方已经提供的的Hive Module,将Hive已有的内置函数作为Flink的内置函数。
- 上传hive connector
[jack@hadoop102 software]$ ll
总用量 1560716
-rw-rw-r--. 1 jack jack 482499797 2月 9 21:05 flink-1.17.2-bin-scala_2.12.tgz
-rw-rw-r--. 1 jack jack 51457817 2月 20 15:26 flink-sql-connector-hive-3.1.3_2.12-1.17.2.jar
-rw-rw-r--. 1 jack jack 371850382 11月 27 09:35 hbase-2.6.1-hadoop3-bin.tar.gz
cp flink-sql-connector-hive-3.1.3_2.12-1.17.2.jar /opt/module/flink-1.17.2/lib/
## 拷贝hadoop的包,解决依赖冲突问题
cp /opt/module/hadoop-3.3.6/share/hadoop/mapreduce/hadoop-mapreduce-client-core-3.3.6.jar /opt/module/flink-1.17.2/lib/- 重启flink集群和sql-client
- 加载hive module
-- hive-connector内置了hive module,提供了hive自带的系统函数
load module hive with ('hive-version'='3.1.3');
show modules;
show functions;
-- 可以调用hive的split函数
select split('a,b', ',');运行结果: