持续查询
动态表可以像静态的批处理表一样进行查询操作。由于数据在不断变化,因此基于它定义的SQL查询也不可能执行一次就得到最终结果。这样一来,我们对动态表的查询也就永远不会停止,一直在随着新数据的到来而继续执行。这样的查询就被称作"持续查询"(Continuous Query)。对动态表定义的查询操作,都是持续查询;而持续查询的结果也会是一个动态表。
由于每次数据到来都会触发查询操作,因此可以认为一次查询面对的数据集,就是当前输入动态表中收到的所有数据。这相当于是对输入动态表做了一个"快照"(snapshot),当作有限数据集进行批处理;流式数据的到来会触发连续不断的快照查询,像动画一样连贯起来,就构成了"持续查询"。 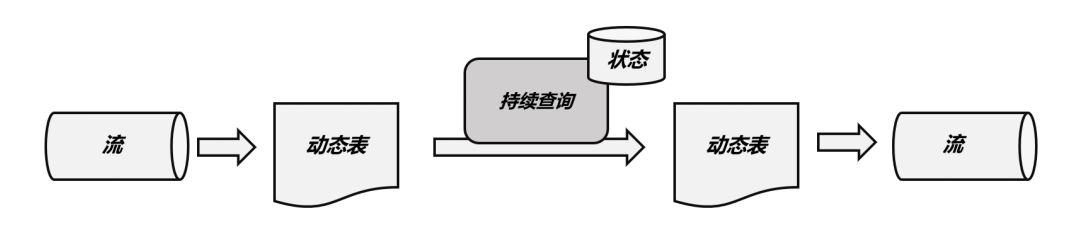 持续查询的步骤如下:
持续查询的步骤如下:
(1)流(stream)被转换为动态表(dynamic table);
(2)对动态表进行持续查询(continuous query),生成新的动态表;
(3)生成的动态表被转换成流。
这样,只要API将流和动态表的转换封装起来,我们就可以直接在数据流上执行SQL查询,用处理表的方式来做流处理了。
1. 动态表
流处理面对的数据是连续不断的,这导致了流处理中的"表"跟我们熟悉的关系型数据库中的表完全不同;而基于表执行的查询操作,也就有了新的含义。
当流中有新数据到来,初始的表中会插入一行;而基于这个表定义的SQL查询,就应该在之前的基础上更新结果。这样得到的表就会不断地动态变化,被称为"动态表"(Dynamic Tables)。
动态表是Flink在Table API和SQL中的核心概念,它为流数据处理提供了表和SQL支持。
2. 动态表和关系表对比
关系型表/SQL与流处理做一个对比,如表所示:
| 关系型表/SQL | 流处理 | |
|---|---|---|
| 处理的数据对象 | 字段元组的有界集合 | 字段元组的无限序列 |
| 查询(Query)对数据的访问 | 可以访问到完整的数据输入 | 无法访问到所有数据,必须"持续"等待流式输入 |
| 查询终止条件 | 生成固定大小的结果集后终止 | 永不停止,根据持续收到的数据不断更新查询结果 |
可以看到,其实关系型表和SQL,主要就是针对批处理设计的,这和流处理有着天生的隔阂。接下来我们就来深入探讨一下流处理中表的概念。
3. 将流转换成动态表
如果把流看作一张表,那么流中每个数据的到来,都应该看作是对表的一次插入(Insert)操作,会在表的末尾添加一行数据。因为流是连续不断的,而且之前的输出结果无法改变、只能在后面追加;所以我们其实是通过一个只有插入操作(insert-only)的更新日志(changelog)流,来构建一个表。
4. 将动态表转换为流
与关系型数据库中的表一样,动态表也可以通过插入(Insert)、更新(Update)和删除(Delete)操作,进行持续的更改。将动态表转换为流或将其写入外部系统时,就需要对这些更改操作进行编码,通过发送编码消息的方式告诉外部系统要执行的操作。在Flink中,Table API和SQL支持三种编码方式:
- 仅追加(Append-only)流: 仅通过插入(Insert)更改来修改的动态表,可以直接转换为"仅追加"流。这个流中发出的数据,其实就是动态表中新增的每一行。
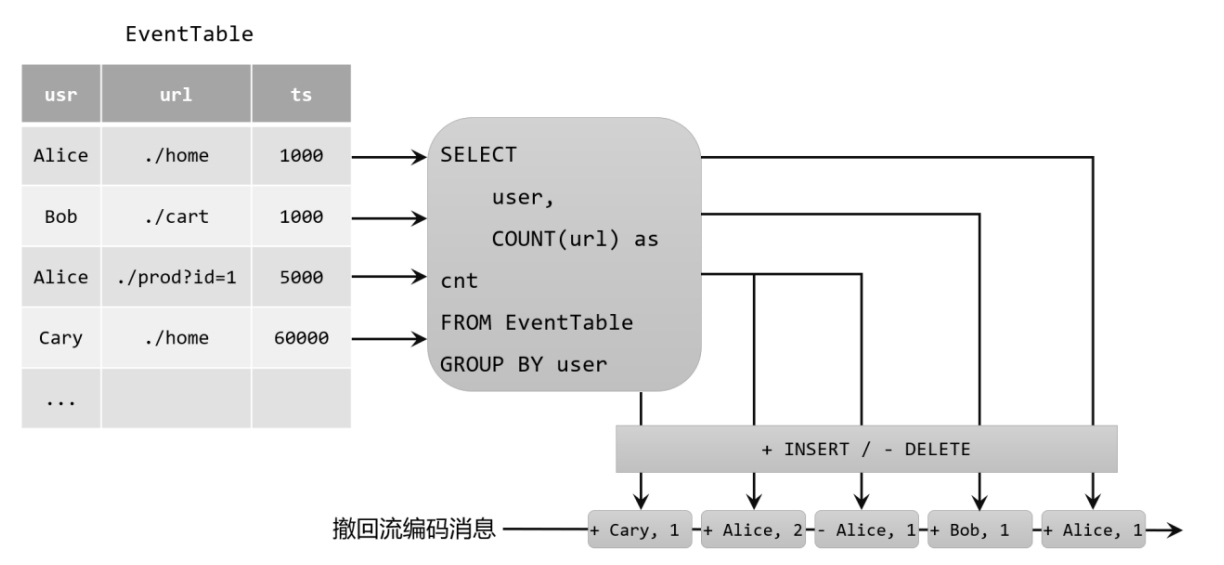
- 撤回(Retract)流: 撤回流是包含两类消息的流,添加(add)消息和撤回(retract)消息。 具体的编码规则是:INSERT插入操作编码为add消息;DELETE删除操作编码为retract消息;而UPDATE更新操作则编码为被更改行的retract消息,和更新后行(新行)的add消息。这样,我们可以通过编码后的消息指明所有的增删改操作,一个动态表就可以转换为撤回流了。
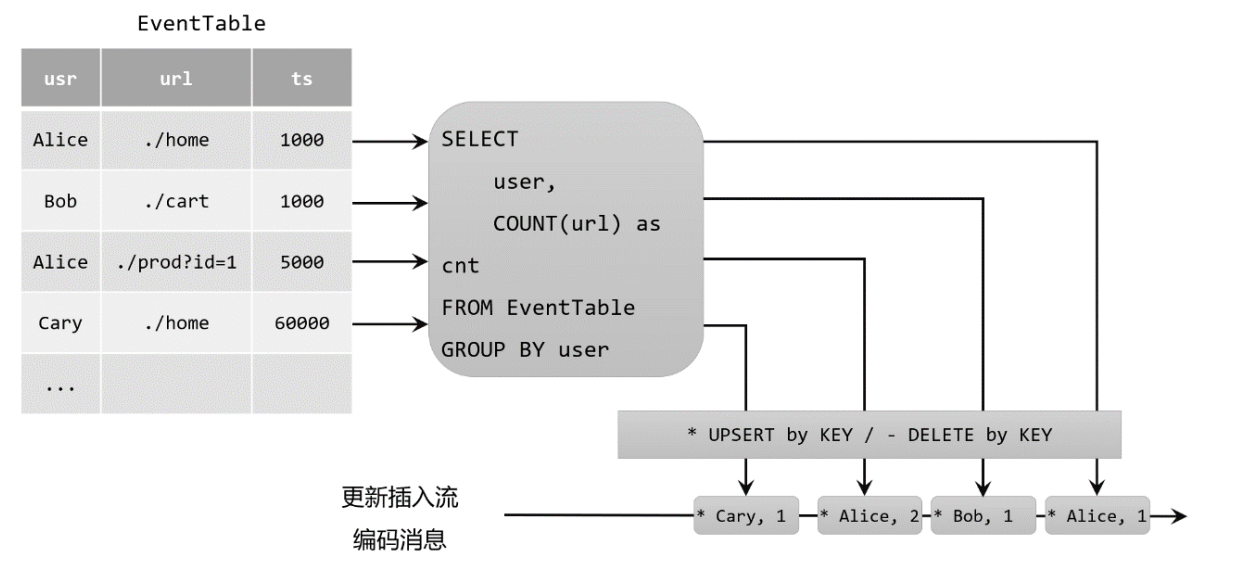
- 更新插入(Upsert)流: 更新插入流中只包含两种类型的消息:更新插入(upsert)消息和删除(delete)消息。 所谓的"upsert"其实是"update"和"insert"的合成词,所以对于更新插入流来说,INSERT插入操作和UPDATE更新操作,统一被编码为upsert消息;而DELETE删除操作则被编码为delete消息。
提示
编码码开发中,Flink提供的开发者API处理将动态表转换为DataStream时,只提供仅追加(append-only)和撤回(retract)流,我们调用toChangelogStream()得到的其实就是撤回流。而更新插入(Upsert)流在Flink的connector内部使用。
5. 用SQL持续查询
5.1 追加(Append)查询
比如在代码中定义了一个SQL查询:
Table aliceVisitTable = tableEnv.sqlQuery("SELECT url, user FROM EventTable WHERE user = 'Cary'");我们执行一个简单的条件查询,结果表中就会像原始表EventTable一样,但只有插入(Insert)操作了。这样的持续查询,就被称为追加查询(Append Query),它定义的结果表的更新日志(changelog)流中只有INSERT操作。
5.2 更新(Update)查询
我们在代码中定义了一个SQL查询:
Table urlCountTable = tableEnv.sqlQuery("SELECT user, COUNT(url) as cnt FROM EventTable GROUP BY user");当原始动态表不停地插入新的数据时,查询得到的urlCountTable会持续地进行更改。由于count数量可能会叠加增长,因此这里的更改操作可以是简单的插入(Insert),也可以是对之前数据的更新(Update)。这种持续查询被称为更新查询(Update Query),更新查询得到的结果表如果想要转换成DataStream,必须调用toChangelogStream()方法。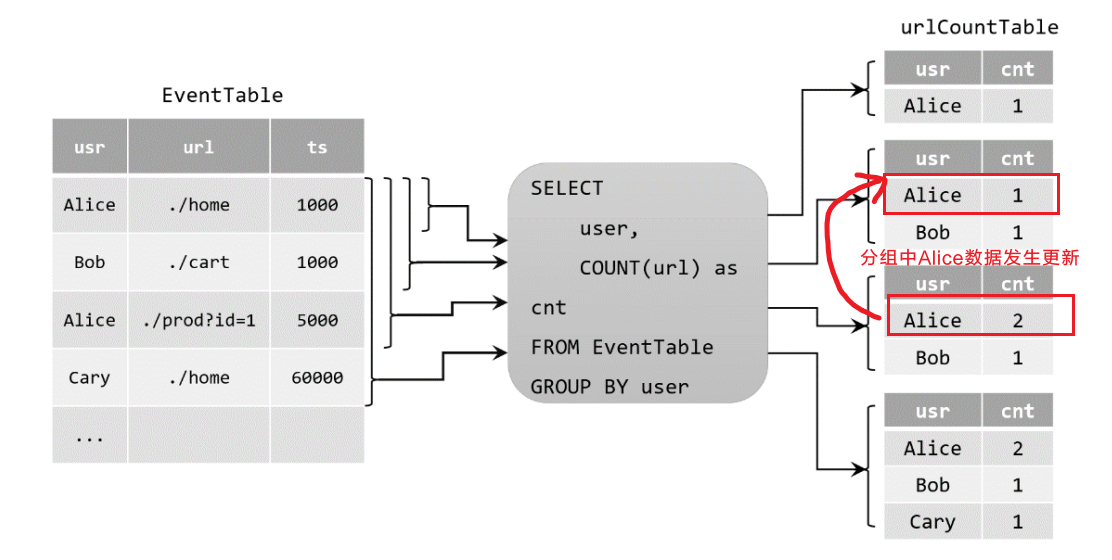
6. 时间属性
在Table API和SQL中,会给表单独提供一个逻辑上的时间字段,专门用来在表处理程序中指示时间。添加的时间属性字段的数据类型必须为TIMESTAMP,它的行为类似于常规时间戳,可以直接访问并且进行计算。
按照时间语义的不同,可以把时间属性的定义分成事件时间(event time)和处理时间(processing time)两种情况。
6.1 事件时间
事件时间属性可以在创建表DDL中定义,增加一个字段,通过WATERMARK语句来定义事件时间属性。具体定义方式如下:
CREATE TABLE EventTable(
user STRING,
url STRING,
ts TIMESTAMP(3),
WATERMARK FOR ts AS ts - INTERVAL '5' SECOND
) WITH (
... -- 属性
);这里我们把EventTable的ts字段定义为事件时间属性,而且基于ts设置了5秒的水位线延迟。时间戳类型必须是TIMESTAMP或者TIMESTAMP_LTZ类型(带了时区)。
6.2 处理时间
在创建表的DDL(CREATE TABLE语句)中,可以增加一个额外的字段,通过调用系统内置的PROCTIME()函数来指定当前的处理时间属性, 专门用来保存当前的处理时间。
CREATE TABLE EventTable(
user STRING,
url STRING,
ts AS PROCTIME()
) WITH (
...
);