Flink部署模式
1. 部署模式介绍
Flink为各种场景提供了不同的部署模式,主要有以下三种:会话模式(Session Mode)、单作业模式(Per-Job Mode)、应用模式(Application Mode)。它们的区别主要在于:集群的生命周期以及资源的分配方式;以及应用的main方法到底在哪里执行——客户端(Client)还是JobManager。
1.1 会话模式(Session Mode)
会话模式其实最符合常规思维。我们需要先启动一个集群,保持一个会话,在这个会话中通过客户端提交作业。集群启动时所有资源就都已经确定,所以所有提交的作业会竞争集群中的资源。 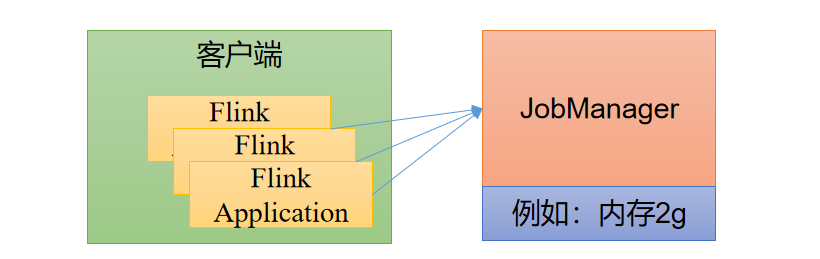 会话模式比较适合于单个规模小、执行时间短的大量作业。
会话模式比较适合于单个规模小、执行时间短的大量作业。
1.2 单作业模式(Per-Job Mode)
会话模式因为资源共享会导致很多问题,所以为了更好地隔离资源,我们可以考虑为每个提交的作业启动一个集群,这就是所谓的单作业(Per-Job)模式。 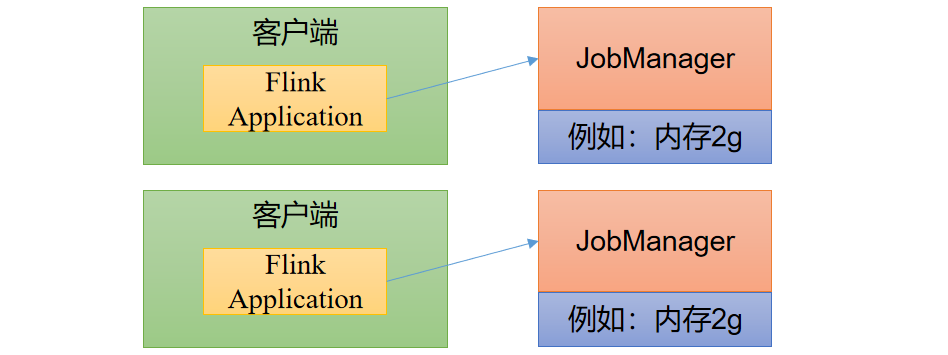 作业完成后,集群就会关闭,所有资源也会释放。这些特性使得单作业模式在生产环境运行更加稳定,所以是实际应用的首选模式。需要注意的是,Flink本身无法直接这样运行,所以单作业模式一般需要借助一些资源管理框架来启动集群,比如YARN、Kubernetes(K8S)。
作业完成后,集群就会关闭,所有资源也会释放。这些特性使得单作业模式在生产环境运行更加稳定,所以是实际应用的首选模式。需要注意的是,Flink本身无法直接这样运行,所以单作业模式一般需要借助一些资源管理框架来启动集群,比如YARN、Kubernetes(K8S)。
1.3 应用模式(Application Mode)
前面提到的两种模式下,应用代码都是在客户端上执行,然后由客户端提交给JobManager的。但是这种方式客户端需要占用大量网络带宽,去下载依赖和把二进制数据发送给JobManager;加上很多情况下我们提交作业用的是同一个客户端,就会加重客户端所在节点的资源消耗。
所以解决办法就是,我们不要客户端了,直接把应用提交到JobManger上运行。而这也就代表着,我们需要为每一个提交的应用单独启动一个JobManager,也就是创建一个集群。这个JobManager只为执行这一个应用而存在,执行结束之后JobManager也就关闭了,这就是所谓的应用模式。  应用模式与单作业模式,都是提交作业之后才创建集群;单作业模式是通过客户端来提交的,客户端解析出的每一个作业对应一个集群;而应用模式下,是直接由JobManager执行应用程序的。值得一提的是Per-Job模式已经被标记为过时了,后期可能被废弃。
应用模式与单作业模式,都是提交作业之后才创建集群;单作业模式是通过客户端来提交的,客户端解析出的每一个作业对应一个集群;而应用模式下,是直接由JobManager执行应用程序的。值得一提的是Per-Job模式已经被标记为过时了,后期可能被废弃。
提示
这里我们所讲到的部署模式,都是些比较抽象的概念。实际应用时,一般需要和资源管理平台结合起来,选择特定的模式来分配资源、部署应用。接下来,我们就针对不同的资源提供者的场景,具体介绍Flink的部署方式。
2. Standalone运行模式(了解)
独立模式是独立运行的,不依赖任何外部的资源管理平台;当然独立也是有代价的:如果资源不足,或者出现故障,没有自动扩展或重分配资源的保证,必须手动处理。所以独立模式一般只用在开发测试或作业非常少的场景下。
2.1 会话模式部署
我们在第二节集群搭建用的就是Standalone集群的会话模式部署。提前启动集群,并通过Web页面客户端提交任务(可以多个任务,但是集群资源固定)。 
2.2 单作业模式部署
Flink的Standalone集群并不支持单作业模式部署。因为单作业模式需要借助一些资源管理平台。
2.3 应用模式部署
应用模式下不会提前创建集群,所以不能调用start-cluster.sh脚本。我们可以使用同样在bin目录下的standalone-job.sh来创建一个JobManager。  具体步骤如下:
具体步骤如下:
- 先停掉之前的通过start-cluster.sh脚本搭建的集群。
[jack@hadoop102 flink-1.17.2]$ ./bin/stop-cluster.sh
Stopping taskexecutor daemon (pid: 104212) on host hadoop102.
Stopping taskexecutor daemon (pid: 91425) on host hadoop103.
Stopping taskexecutor daemon (pid: 50896) on host hadoop104.
Stopping standalonesession daemon (pid: 103801) on host hadoop102.- 环境准备。在hadoop102中执行以下命令启动netcat,如果已经启动好了可以跳过该步骤。
[jack@hadoop102 flink-1.17.2]$ nc -lk 7777- 进入到Flink的安装路径下,将应用程序的jar包放到lib/目录下,放到其他目录会不能识别😱。
[jack@hadoop102 flink-1.17.2]$ mv job_jars/flink-demo-1.0-SNAPSHOT.jar lib/- 执行以下命令,启动JobManager。
[jack@hadoop102 flink-1.17.2]$ bin/standalone-job.sh start --job-classname com.rocket.flink.SocketStreamWordCount
Starting standalonejob daemon on host hadoop102.这里我们直接指定作业入口类,脚本会到lib目录扫描所有的jar包。
5. 同样是使用bin目录下的脚本,启动TaskManager。
[jack@hadoop102 flink-1.17.2]$ bin/taskmanager.sh start
Starting taskexecutor daemon on host hadoop102.
## 可以查看所有linux的进程情况
[jack@hadoop102 flink-1.17.2]$ jpsall
============= hadoop102 ==========
1491 TaskManagerRunner
24740 Jps
126045 StandaloneApplicationClusterEntryPoint
============= hadoop103 ==========
4292 Jps
============= hadoop104 ==========
2539 Jps- 在hadoop102上模拟发送单词数据, 还是访问http://hadoop102:8081, 观察输出数据。
[jack@hadoop102 ~]$ nc -lk 7777
hello world由于standlone模式管理资源的能力有限,需要自己手动启动干活的小弟(taskmanager),目前只启动了一个,直接点击页面菜单taskmanagers,任务分配肯定就是这个taskmanager身上,点击Stdout的tab页面: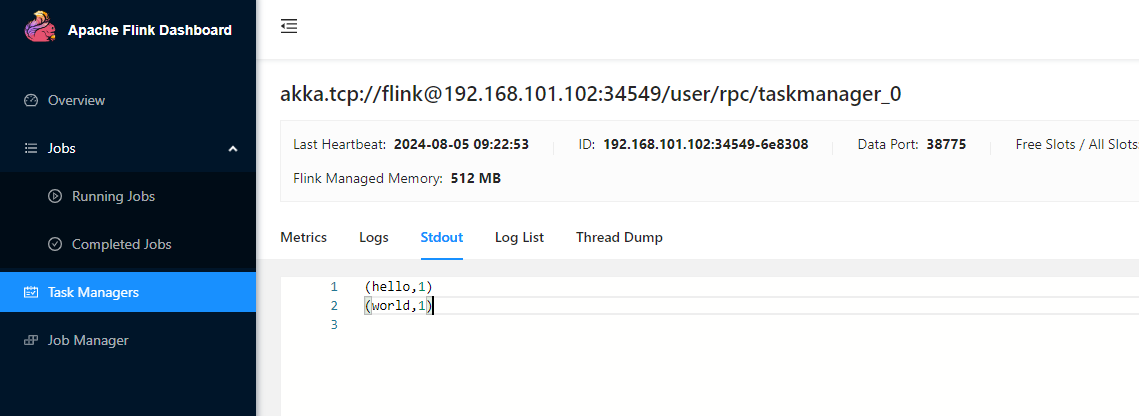 7. 如果希望停掉集群,同样可以使用脚本,命令如下。
7. 如果希望停掉集群,同样可以使用脚本,命令如下。
[jack@hadoop102 flink-1.17.2]$ bin/taskmanager.sh stop
[jack@hadoop102 flink-1.17.2]$ bin/standalone-job.sh stop或者可以直接的页面点击任务cancel按钮,整个集群也会停掉,而不是只会停到taskmanager,这也是该standlone运行下的应用模式特点✍️: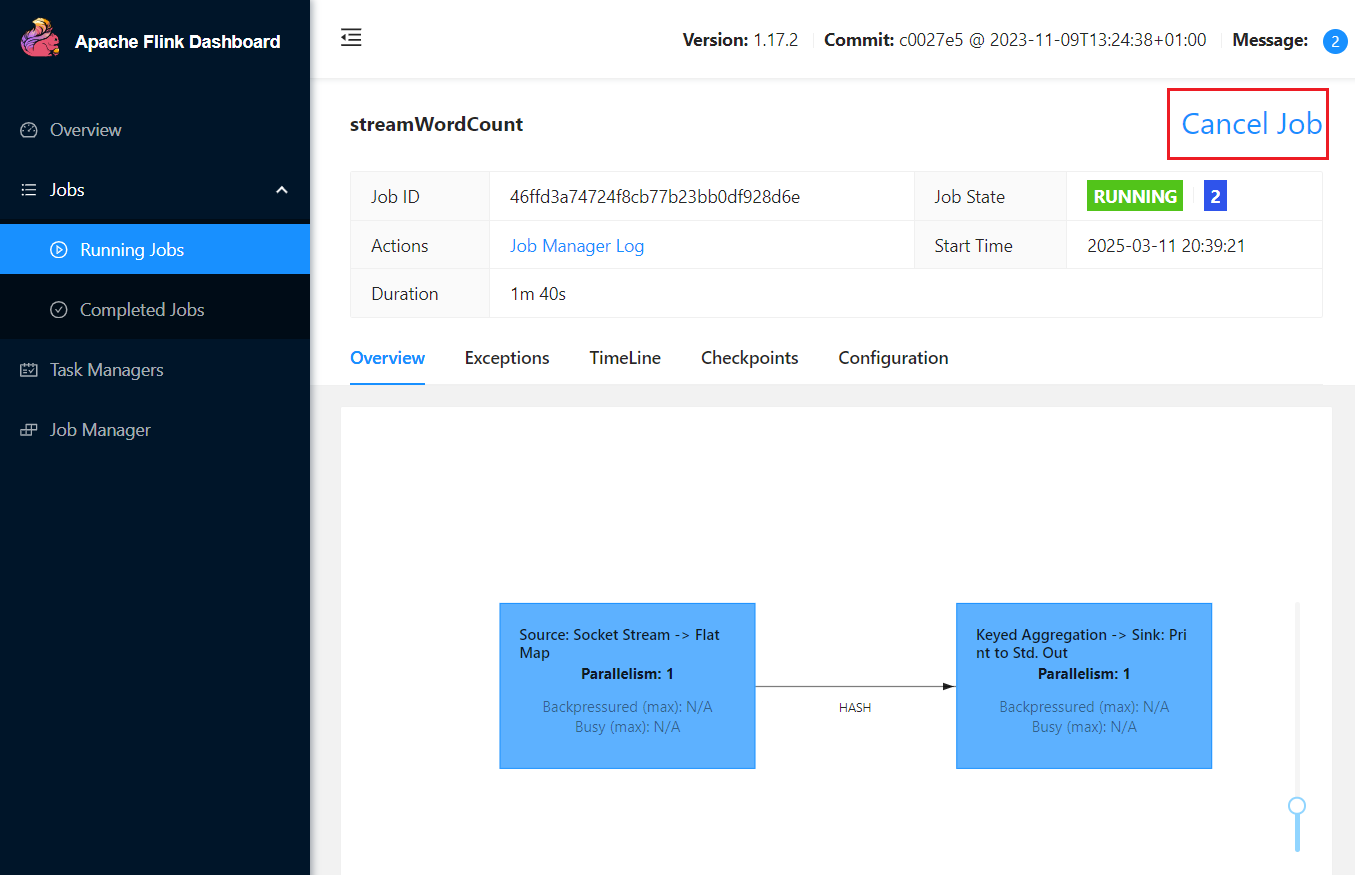
3. YARN运行模式(重点)
YARN上部署的过程是:客户端把Flink应用提交给Yarn的ResourceManager,Yarn的ResourceManager会向Yarn的NodeManager申请容器。在这些容器上,Flink会部署JobManager和TaskManager的实例,从而启动集群。Flink会根据运行在JobManger上的作业所需要的Slot数量动态分配TaskManager资源。
3.1 相关准备和配置
在将Flink任务部署至YARN集群之前,需要确认集群是否安装有Hadoop,保证Hadoop版本至少在2.2以上,并且集群中安装有HDFS服务。
具体配置步骤如下:
- 配置环境变量,增加环境变量配置如下,其中
HADOOP_CLASSPATH表示等于hadoop classpath命令执行的结果 :
$ sudo vim /etc/profile.d/my_env.sh
HADOOP_HOME=/opt/module/hadoop-3.3.6
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_CLASSPATH=`hadoop classpath`老版本的flink整合还有另外一种方式,需要适配编译hadoop版本包得到flink-hadoop-uber-shade.jar放到flink的lib目录方式整合,但缺点也很明显:它绑定了固定版本的hadoop不太灵活。官方推荐使用环境变量的方式整合。
- 启动Hadoop集群,包括HDFS和YARN。
************************************************************/
[jack@hadoop102 bin]$ hadoop_helper start
=================== 启动 hadoop集群 ===================
--------------- 启动 hdfs ---------------
Starting namenodes on [hadoop102]
Starting datanodes
Starting secondary namenodes [hadoop104]
--------------- 启动 yarn ---------------
Starting resourcemanager
Starting nodemanagers
--------------- 启动 historyserver ---------------- 在hadoop102中执行以下命令启动netcat
[jack@hadoop102 ~]$ nc -lk 77773.2 会话模式部署
YARN的会话模式与独立集群略有不同,需要首先申请一个YARN会话(YARN Session)来启动Flink集群。具体步骤如下:
- 执行脚本命令向YARN集群申请资源,开启一个YARN会话,启动Flink集群
[jack@hadoop102 flink-1.17.2]$ bin/yarn-session.sh -nm test -d
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/module/flink-1.17.2/lib/log4j-slf4j-impl-2.17.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/hadoop-3.3.6/share/hadoop/common/lib/slf4j-reload4j-1.7.36.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
2024-08-28 07:57:14,261 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: jobmanager.rpc.address, hadoop102
2024-08-28 07:57:14,267 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: jobmanager.rpc.port, 6123
2024-08-28 07:57:14,268 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: jobmanager.memory.process.size, 1600m
2024-08-28 07:57:14,268 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: taskmanager.memory.process.size, 1728m
2024-08-28 07:57:14,268 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: taskmanager.numberOfTaskSlots, 1
2024-08-28 07:57:14,269 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: parallelism.default, 1
2024-08-28 07:57:14,269 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: jobmanager.execution.failover-strategy, region
2024-08-28 07:57:14,270 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: rest.port, 8081
2024-08-28 07:57:14,270 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: rest.address, 0.0.0.0
2024-08-28 07:57:14,270 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: rest.bind-address, 0.0.0.0
2024-08-28 07:57:14,917 WARN org.apache.hadoop.util.NativeCodeLoader [] - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2024-08-28 07:57:14,999 INFO org.apache.flink.runtime.security.modules.HadoopModule [] - Hadoop user set to jack (auth:SIMPLE)
2024-08-28 07:57:15,053 INFO org.apache.flink.runtime.security.modules.JaasModule [] - Jaas file will be created as /tmp/jaas-8991792773347060979.conf.
2024-08-28 07:57:15,099 WARN org.apache.flink.yarn.configuration.YarnLogConfigUtil [] - The configuration directory ('/opt/module/flink-1.17.2/conf') already contains a LOG4J config file.If you want to use logback, then please delete or rename the log configuration file.
2024-08-28 07:57:15,227 INFO org.apache.hadoop.yarn.client.DefaultNoHARMFailoverProxyProvider [] - Connecting to ResourceManager at hadoop103/192.168.101.103:8032
2024-08-28 07:57:15,738 INFO org.apache.flink.runtime.util.config.memory.ProcessMemoryUtils [] - The derived from fraction jvm overhead memory (160.000mb (167772162 bytes)) is less than its min value 192.000mb (201326592 bytes), min value will be used instead
2024-08-28 07:57:15,772 INFO org.apache.flink.runtime.util.config.memory.ProcessMemoryUtils [] - The derived from fraction jvm overhead memory (172.800mb (181193935 bytes)) is less than its min value 192.000mb (201326592 bytes), min value will be used instead
2024-08-28 07:57:16,416 INFO org.apache.hadoop.conf.Configuration [] - resource-types.xml not found
2024-08-28 07:57:16,417 INFO org.apache.hadoop.yarn.util.resource.ResourceUtils [] - Unable to find 'resource-types.xml'.
2024-08-28 07:57:16,585 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - The configured JobManager memory is 1600 MB. YARN will allocate 2048 MB to make up an integer multiple of its minimum allocation memory (1024 MB, configured via 'yarn.scheduler.minimum-allocation-mb'). The extra 448 MB may not be used by Flink.
2024-08-28 07:57:16,585 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - The configured TaskManager memory is 1728 MB. YARN will allocate 2048 MB to make up an integer multiple of its minimum allocation memory (1024 MB, configured via 'yarn.scheduler.minimum-allocation-mb'). The extra 320 MB may not be used by Flink.
2024-08-28 07:57:16,586 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Cluster specification: ClusterSpecification{masterMemoryMB=1600, taskManagerMemoryMB=1728, slotsPerTaskManager=1}
2024-08-28 07:57:26,522 INFO org.apache.flink.runtime.util.config.memory.ProcessMemoryUtils [] - The derived from fraction jvm overhead memory (160.000mb (167772162 bytes)) is less than its min value 192.000mb (201326592 bytes), min value will be used instead
2024-08-28 07:57:26,556 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Submitting application master application_1723025832151_0002
2024-08-28 07:57:26,691 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl [] - Submitted application application_1723025832151_0002
2024-08-28 07:57:26,691 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Waiting for the cluster to be allocated
2024-08-28 07:57:26,695 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Deploying cluster, current state ACCEPTED
2024-08-28 07:57:41,991 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - YARN application has been deployed successfully.
2024-08-28 07:57:41,993 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface hadoop104:8081 of application 'application_1723025832151_0002'.
JobManager Web Interface: http://hadoop104:8081
2024-08-28 07:57:42,477 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli [] - The Flink YARN session cluster has been started in detached mode. In order to stop Flink gracefully, use the following command:
$ echo "stop" | ./bin/yarn-session.sh -id application_1723025832151_0002
If this should not be possible, then you can also kill Flink via YARN's web interface or via:
$ yarn application -kill application_1723025832151_0002
Note that killing Flink might not clean up all job artifacts and temporary files.可用参数解读:
-d:分离模式,如果你不想让Flink YARN客户端一直前台运行,可以使用这个参数,即使关掉当前对话窗口,YARN session也可以后台运行。-jm(--jobManagerMemory):配置JobManager所需内存,默认单位MB。-nm(--name):配置在YARN UI界面上显示的任务名。-qu(--queue):指定YARN队列名。-tm(--taskManager):配置每个TaskManager所使用内存。
提示
Flink1.11.0之后版本不再使用-n参数和-s参数分别指定TaskManager数量和slot数量,YARN会按照需求动态分配TaskManager和slot。所以从这个意义上讲,YARN的会话模式也不会把集群资源固定,同样是动态分配的。
YARN Session启动之后日志中会给出一个Web UI地址以及一个YARN application ID,另外在也可以在Yarn的管控页面看到flink程序启动信息,之前启动Flink需要修改flink-conf.yaml文件,在Yarn运行模式中,它会自动生成不用我们手动编写,端口是Yarn随机分配: 点击TrackingUI列下的ApplicationMaster超链接,即可进入flink的web ui页面:
点击TrackingUI列下的ApplicationMaster超链接,即可进入flink的web ui页面: 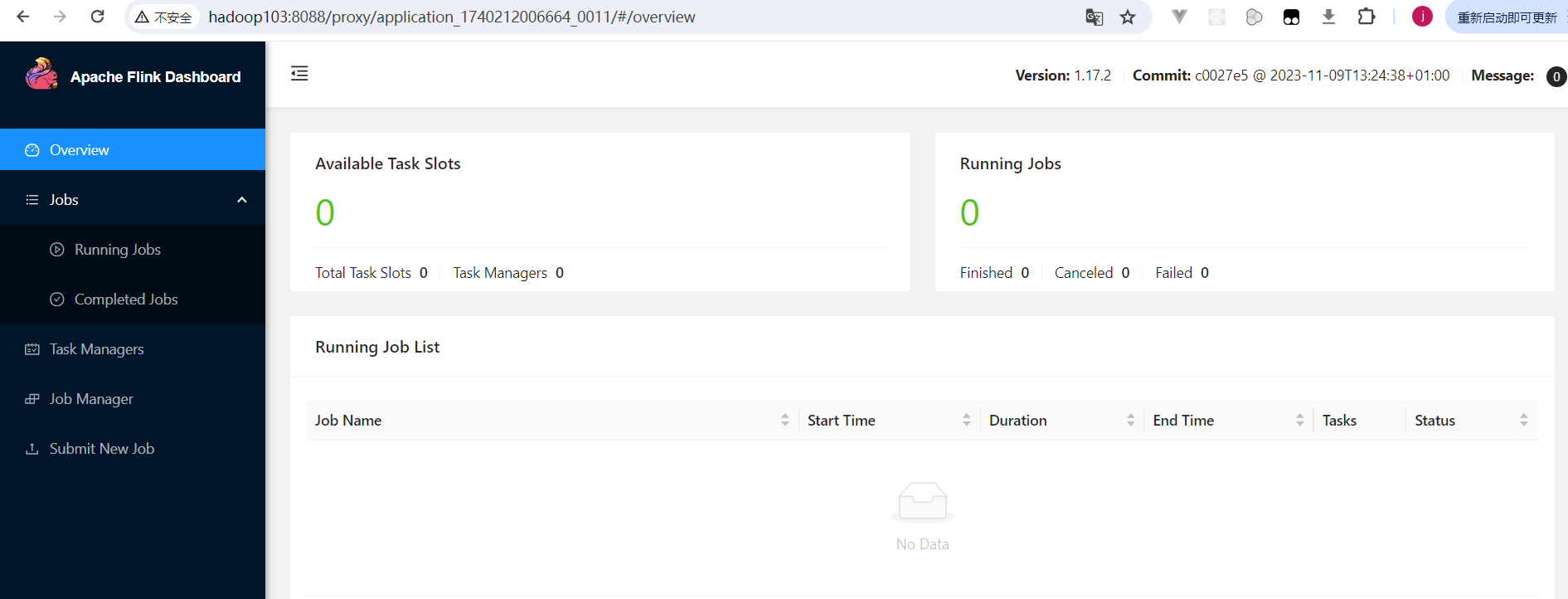 可以看到目前taskmanager为0,也就是在Yarn上面只部署了jobManager。
可以看到目前taskmanager为0,也就是在Yarn上面只部署了jobManager。
- 通过Web UI提交作业
与上文所述Standalone部署模式基本相同,进入Submit New Job菜单,点击Add New按钮,选择之前打好的flink-demo-1.0-SNAPSHOT.jar包,然后输入方法入口类即可。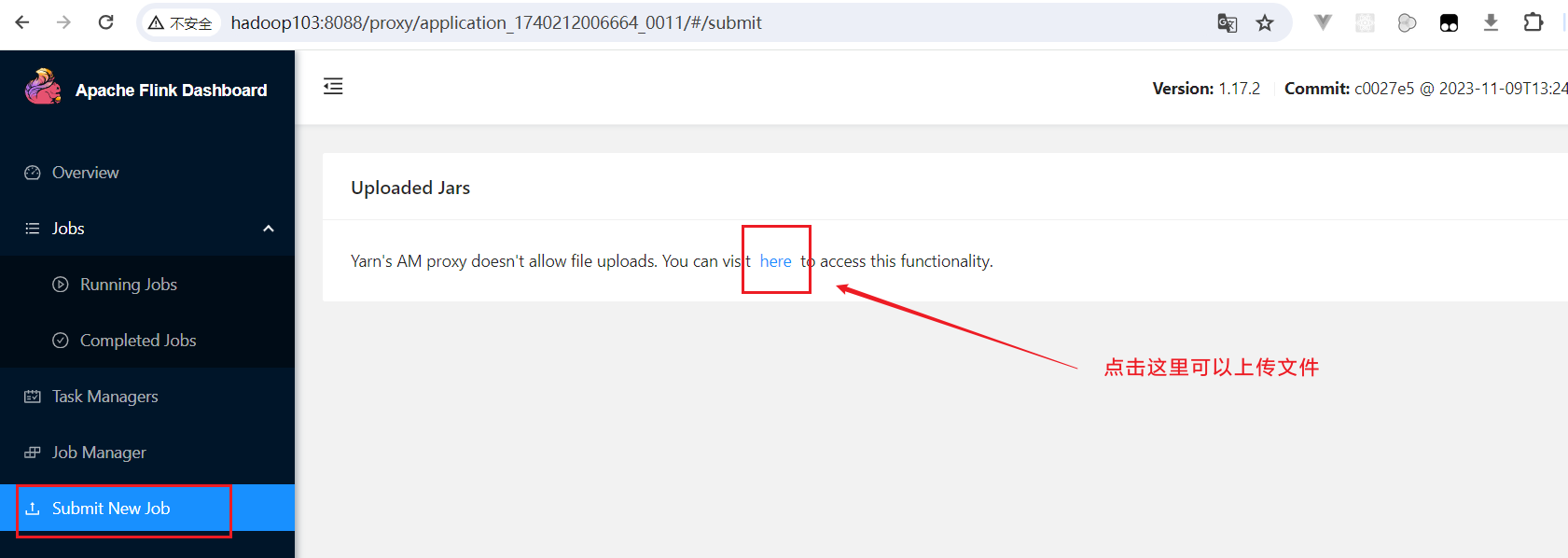 点击here超链接,就跳转到可以上传jar页面:
点击here超链接,就跳转到可以上传jar页面: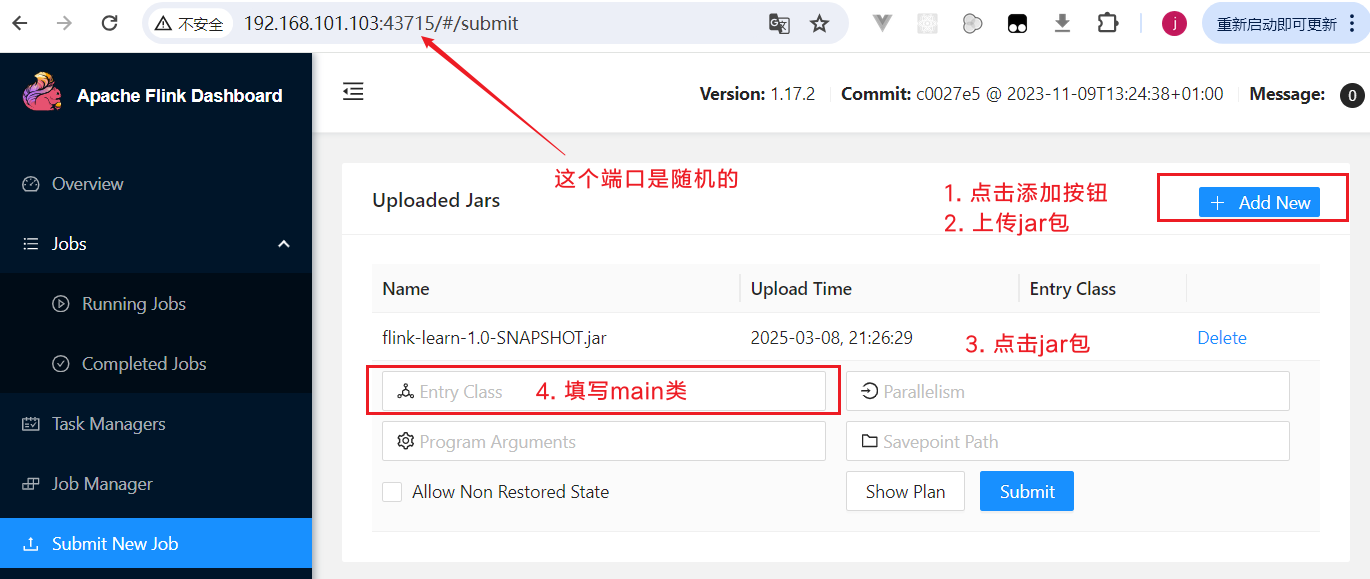 点击Submit按钮,可以看到任务开始创建:
点击Submit按钮,可以看到任务开始创建: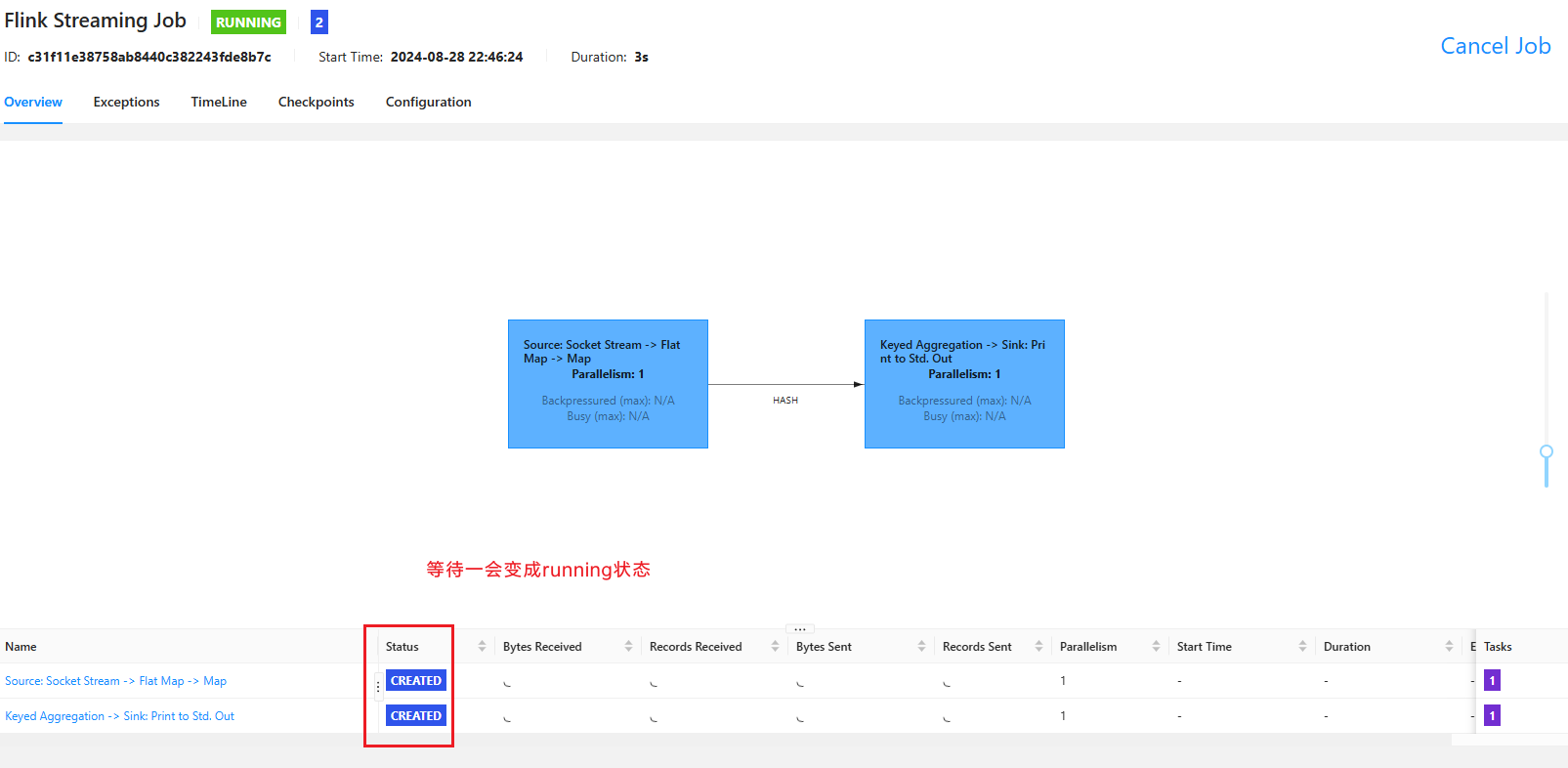 创建完毕后,任务就开始在执行了:
创建完毕后,任务就开始在执行了: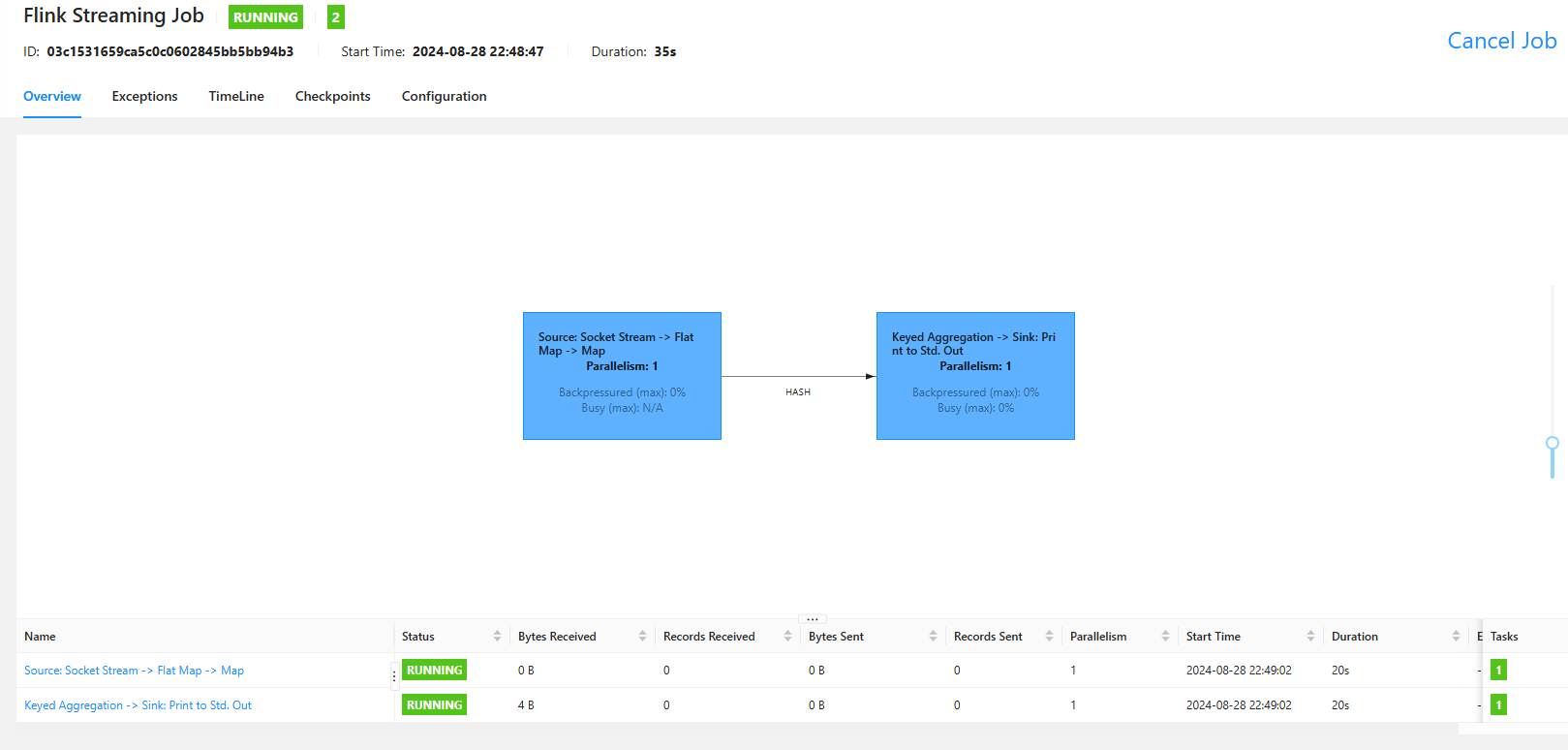 在nc控制台输入数据:hello world
在nc控制台输入数据:hello world  然后查看web ui的控制台输出:
然后查看web ui的控制台输出: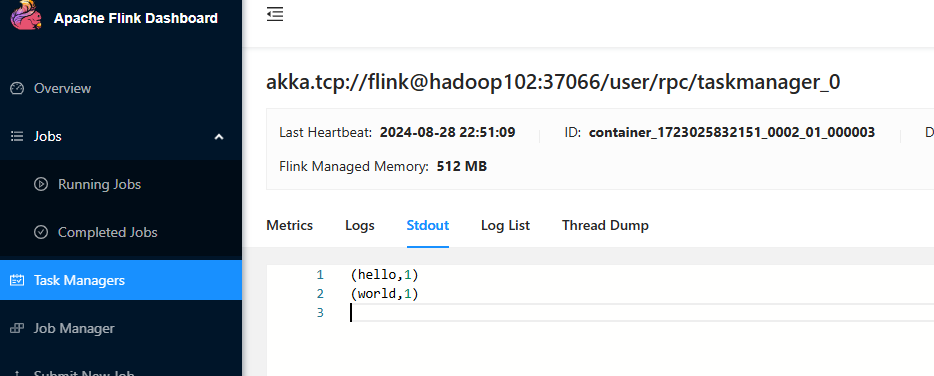 并且首页的taskmanager也变成了1:
并且首页的taskmanager也变成了1: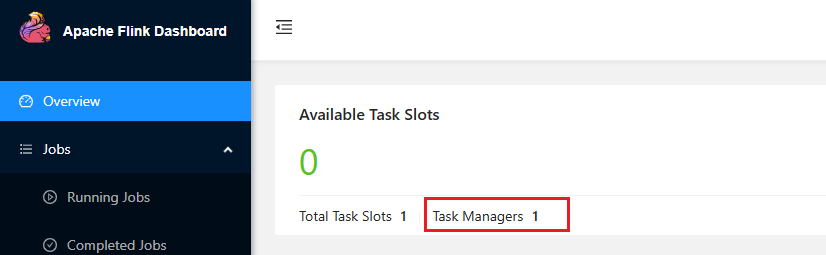 如果点击取消运行,查看首页taskmanager数量:
如果点击取消运行,查看首页taskmanager数量: 任务取消后,在首页可以看到当前可用的任务插槽为1:
任务取消后,在首页可以看到当前可用的任务插槽为1: 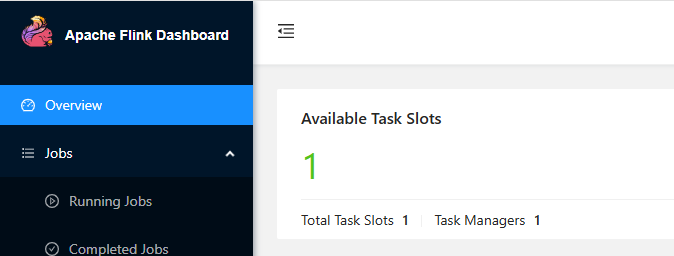 再等片刻可以看到插槽为0,taskmanager也为0,说明Yarn可以分配TaskManager资源。
再等片刻可以看到插槽为0,taskmanager也为0,说明Yarn可以分配TaskManager资源。 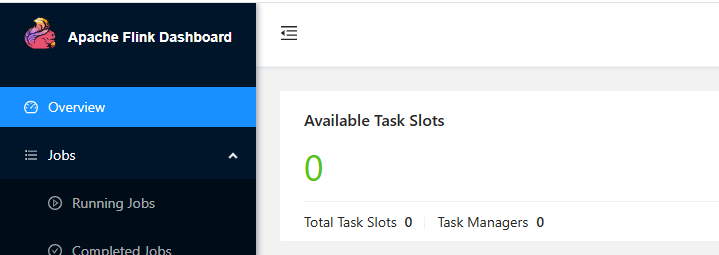
- 通过命令行提交作业 将flink-demo-1.0-SNAPSHOT.jar包上传至集群。
[jack@hadoop102 lib]$ pwd
/opt/module/flink-1.17.2/lib
[jack@hadoop102 lib]$ ll
总用量 181716
-rw-r--r--. 1 jack jack 85586 9月 10 2022 flink-csv-1.17.2.jar
-rw-rw-r--. 1 jack jack 23108 8月 5 02:37 flink-demo-1.0-SNAPSHOT.jar
-rw-r--r--. 1 jack jack 136097427 9月 10 2022 flink-dist_2.12-1.17.2.jar
-rw-r--r--. 1 jack jack 153148 9月 10 2022 flink-json-1.17.2.jar
-rw-r--r--. 1 jack jack 7709731 6月 9 2022 flink-shaded-zookeeper-3.4.14.jar
-rw-r--r--. 1 jack jack 39669327 9月 10 2022 flink-table_2.12-1.17.2.jar
-rw-r--r--. 1 jack jack 208006 6月 9 2022 log4j-1.2-api-2.17.1.jar
-rw-r--r--. 1 jack jack 301872 6月 9 2022 log4j-api-2.17.1.jar
-rw-r--r--. 1 jack jack 1790452 6月 9 2022 log4j-core-2.17.1.jar
-rw-r--r--. 1 jack jack 24279 6月 9 2022 log4j-slf4j-impl-2.17.1.jar执行以下命令将该任务提交到已经开启的Yarn-Session中运行。
[jack@hadoop102 flink-1.17.2]$ bin/flink run -d -c com.rocket.flink.SocketStreamWordCount lib/flink-demo-1.0-SNAPSHOT.jar
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/module/flink-1.17.2/lib/log4j-slf4j-impl-2.17.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/hadoop-3.3.6/share/hadoop/common/lib/slf4j-reload4j-1.7.36.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
2024-08-28 23:19:45,594 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli [] - Found Yarn properties file under /tmp/.yarn-properties-jack.
2024-08-28 23:19:45,594 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli [] - Found Yarn properties file under /tmp/.yarn-properties-jack.
2024-08-28 23:19:48,665 WARN org.apache.flink.yarn.configuration.YarnLogConfigUtil [] - The configuration directory ('/opt/module/flink-1.17.2/conf') already contains a LOG4J config file.If you want to use logback, then please delete or rename the log configuration file.
2024-08-28 23:19:48,783 INFO org.apache.hadoop.yarn.client.DefaultNoHARMFailoverProxyProvider [] - Connecting to ResourceManager at hadoop103/192.168.101.103:8032
2024-08-28 23:19:49,129 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
2024-08-28 23:19:49,278 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface hadoop104:8081 of application 'application_1723025832151_0002'.
Job has been submitted with JobID b74f7acd9e492e921f8d0610479f897cflink可以自行确定JobManager目的地,flink首先会去查看/tmp/.yarn-properties-jack文件有没有这个文件,有的话就说明当前使用的Yarn管理任务资源,JobManager的地址是通过读取/tmp/.yarn-properties-jack文件中内容进行确定。
[jack@hadoop102 flink-1.17.2]$ cat /tmp/.yarn-properties-jack
#Generated YARN properties file
#Wed Aug 28 07:57:42 CST 2024
dynamicPropertiesString=
applicationID=application_1723025832151_0002任务提交成功后,可在YARN的Web UI界面查看运行情况。 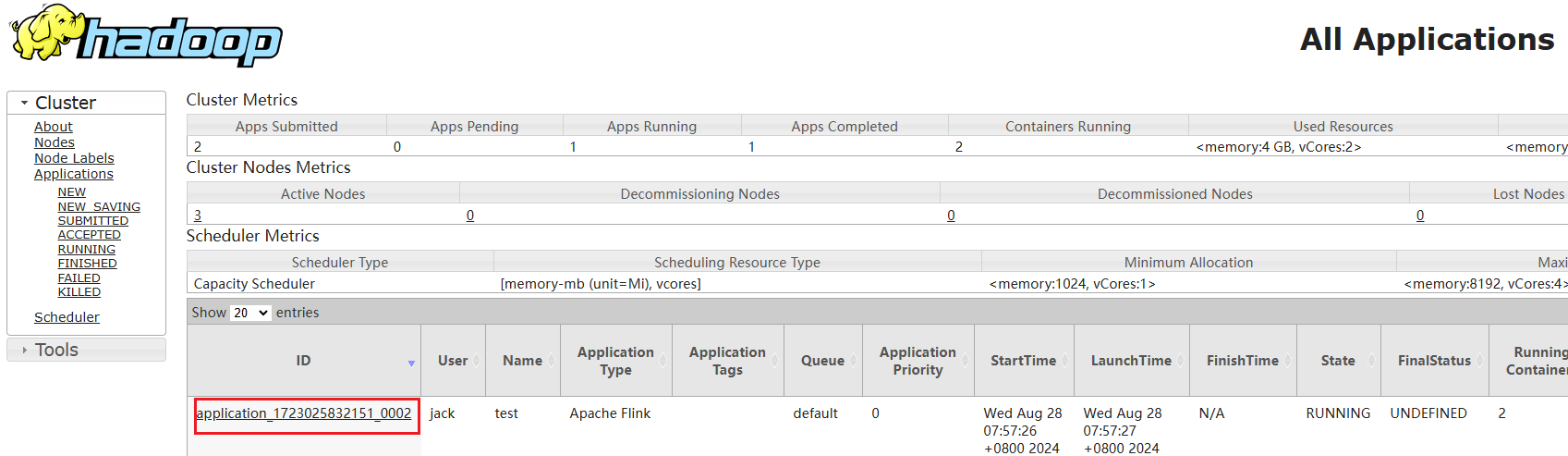 从上图中可以看到我们创建的Yarn-Session实际上是一个Yarn的Application,并且有唯一的Application ID,为application_1723025832151_0002,和命令行读取/tmp/.yarn-properties-jack文件中内容保持一致,也就是说flink命令会通过Application ID自动找到Yarn上Flink集群的地址。
从上图中可以看到我们创建的Yarn-Session实际上是一个Yarn的Application,并且有唯一的Application ID,为application_1723025832151_0002,和命令行读取/tmp/.yarn-properties-jack文件中内容保持一致,也就是说flink命令会通过Application ID自动找到Yarn上Flink集群的地址。
3.4 关闭会话模式部署
关闭会话模式有两种方式,第一种直接在yarn管控页面上关闭,第二种输入命令行关闭。
在yarn管控页面上关闭会话模式部署
进入yarn管控页面,点击applications菜单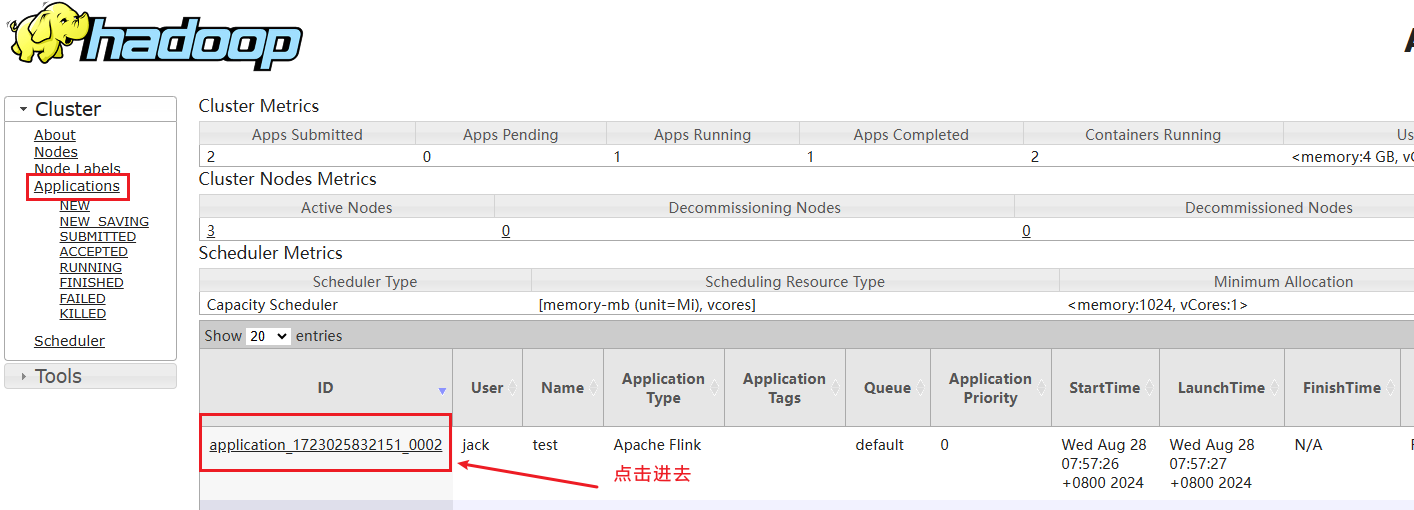 点击kill application按钮即可停止flink的jobmanager运行
点击kill application按钮即可停止flink的jobmanager运行 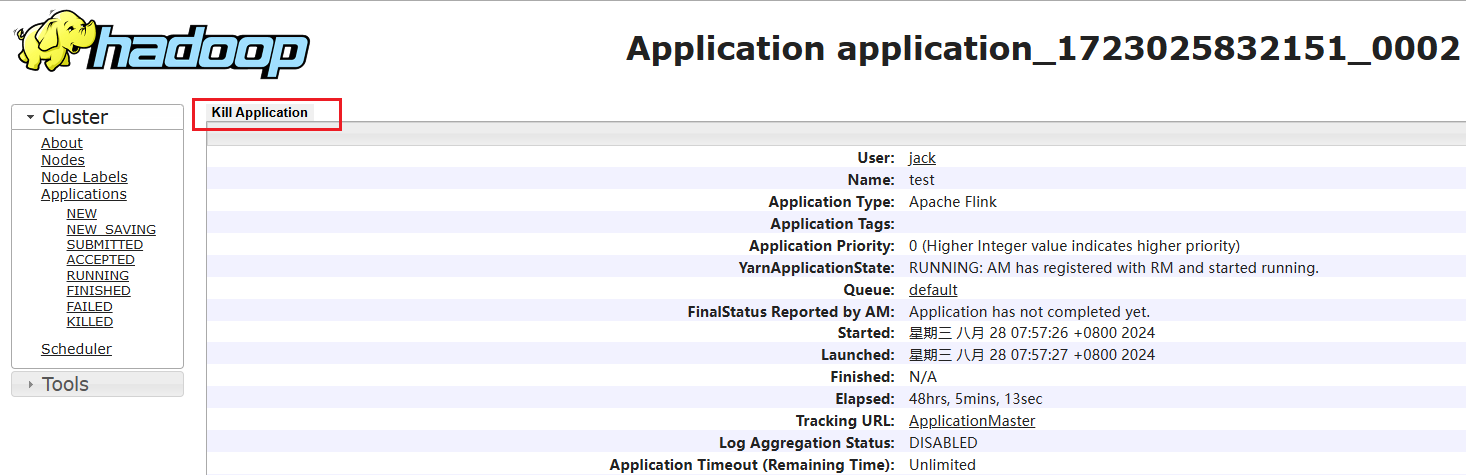
命令行关闭会话模式部署
在之前启动yarn-session命令之后,日志打印提示使用命令:echo "stop" | ./bin/yarn-session.sh -id application_1723025832151_0002。执行的时候需要在flink文件夹目录下即可,推荐使用第二种方式,优雅的关闭flink。
[jack@hadoop102 flink-1.17.2]$ echo "stop" | ./bin/yarn-session.sh -id application_1723025832151_0002
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/module/flink-1.17.2/lib/log4j-slf4j-impl-2.17.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/hadoop-3.3.6/share/hadoop/common/lib/slf4j-reload4j-1.7.36.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
2024-08-31 10:59:01,161 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: jobmanager.rpc.address, hadoop102
2024-08-31 10:59:01,166 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: jobmanager.rpc.port, 6123
2024-08-31 10:59:01,167 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: jobmanager.memory.process.size, 1600m
2024-08-31 10:59:01,167 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: taskmanager.memory.process.size, 1728m
2024-08-31 10:59:01,168 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: taskmanager.numberOfTaskSlots, 1
2024-08-31 10:59:01,168 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: parallelism.default, 1
2024-08-31 10:59:01,170 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: jobmanager.execution.failover-strategy, region
2024-08-31 10:59:01,170 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: rest.port, 8081
2024-08-31 10:59:01,170 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: rest.address, 0.0.0.0
2024-08-31 10:59:01,170 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: rest.bind-address, 0.0.0.0
2024-08-31 10:59:01,200 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli [] - Found Yarn properties file under /tmp/.yarn-properties-jack.
2024-08-31 10:59:01,615 WARN org.apache.hadoop.util.NativeCodeLoader [] - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2024-08-31 10:59:01,649 INFO org.apache.flink.runtime.security.modules.HadoopModule [] - Hadoop user set to jack (auth:SIMPLE)
2024-08-31 10:59:01,713 INFO org.apache.flink.runtime.security.modules.JaasModule [] - Jaas file will be created as /tmp/jaas-1825555713500602483.conf.
2024-08-31 10:59:01,752 WARN org.apache.flink.yarn.configuration.YarnLogConfigUtil [] - The configuration directory ('/opt/module/flink-1.17.2/conf') already contains a LOG4J config file.If you want to use logback, then please delete or rename the log configuration file.
2024-08-31 10:59:01,833 INFO org.apache.hadoop.yarn.client.DefaultNoHARMFailoverProxyProvider [] - Connecting to ResourceManager at hadoop103/192.168.101.103:8032
2024-08-31 10:59:02,463 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface hadoop104:8081 of application 'application_1723025832151_0002'.
2024-08-31 10:59:03,135 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli [] - Deleted Yarn properties file at /tmp/.yarn-properties-jack
2024-08-31 10:59:03,144 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli [] - Application application_1723025832151_0002 finished with state FINISHED and final state SUCCEEDED at 1725073143148查看yarn控制台页面: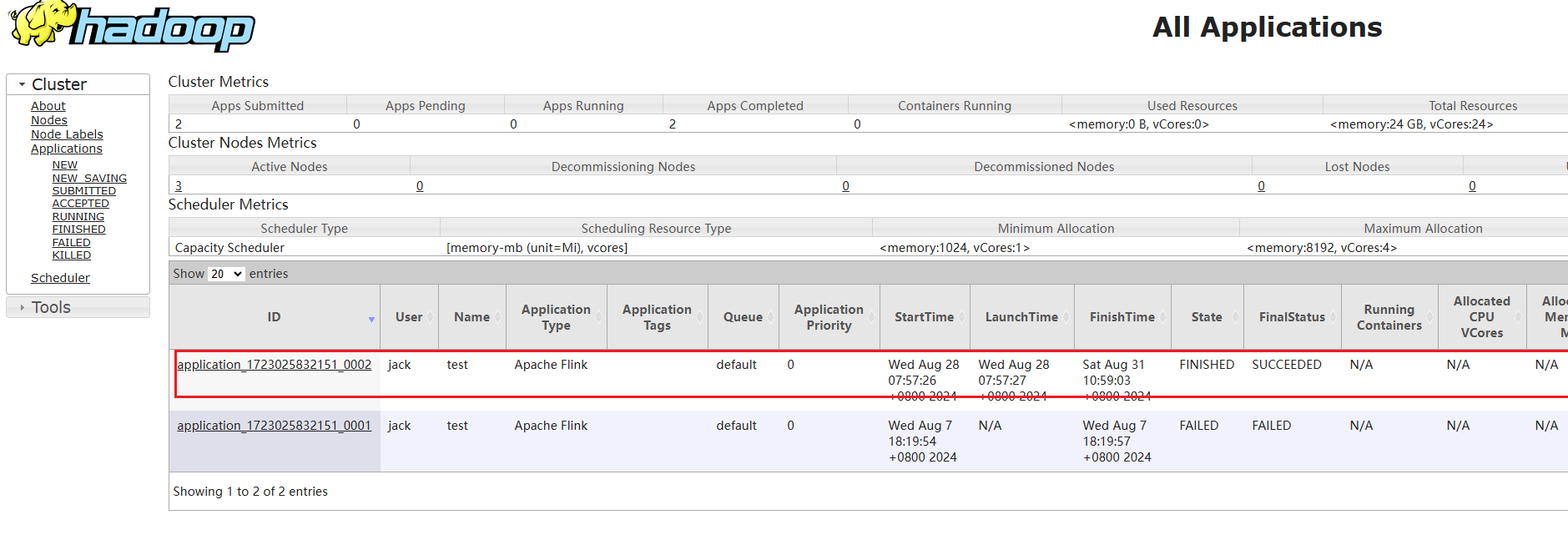
3.5 单作业模式部署
在YARN环境中,由于有了外部平台做资源调度,所以我们也可以直接向YARN提交一个单独的作业,从而启动一个Flink集群。
- 执行命令提交作业
[jack@hadoop102 flink-1.17.2]$ bin/flink run -d -t yarn-per-job -c com.rocket.flink.SocketStreamWordCount flink-demo-1.0-SNAPSHOT.jar提示
注意:如果启动过程中报如下异常。
Exception in thread "Thread-5" java.lang.IllegalStateException: Trying to access closed classloader. Please check if you store classloaders directly or indirectly in static fields. If the stacktrace suggests that the leak occurs in a third party library and cannot be fixed immediately, you can disable this check with the configuration ‘classloader.check-leaked-classloader’.
at org.apache.flink.runtime.execution.librarycache.FlinkUserCodeClassLoaders解决办法:在flink的/opt/module/flink-1.17.2/conf/flink-conf.yaml配置文件中设置
classloader.check-leaked-classloader: false- 在YARN的ResourceManager界面查看执行情况,点击ApplicationMaster跳转到flink的web ui界面。
 在flink的web ui界面,可以看到任务的执行情况:
在flink的web ui界面,可以看到任务的执行情况: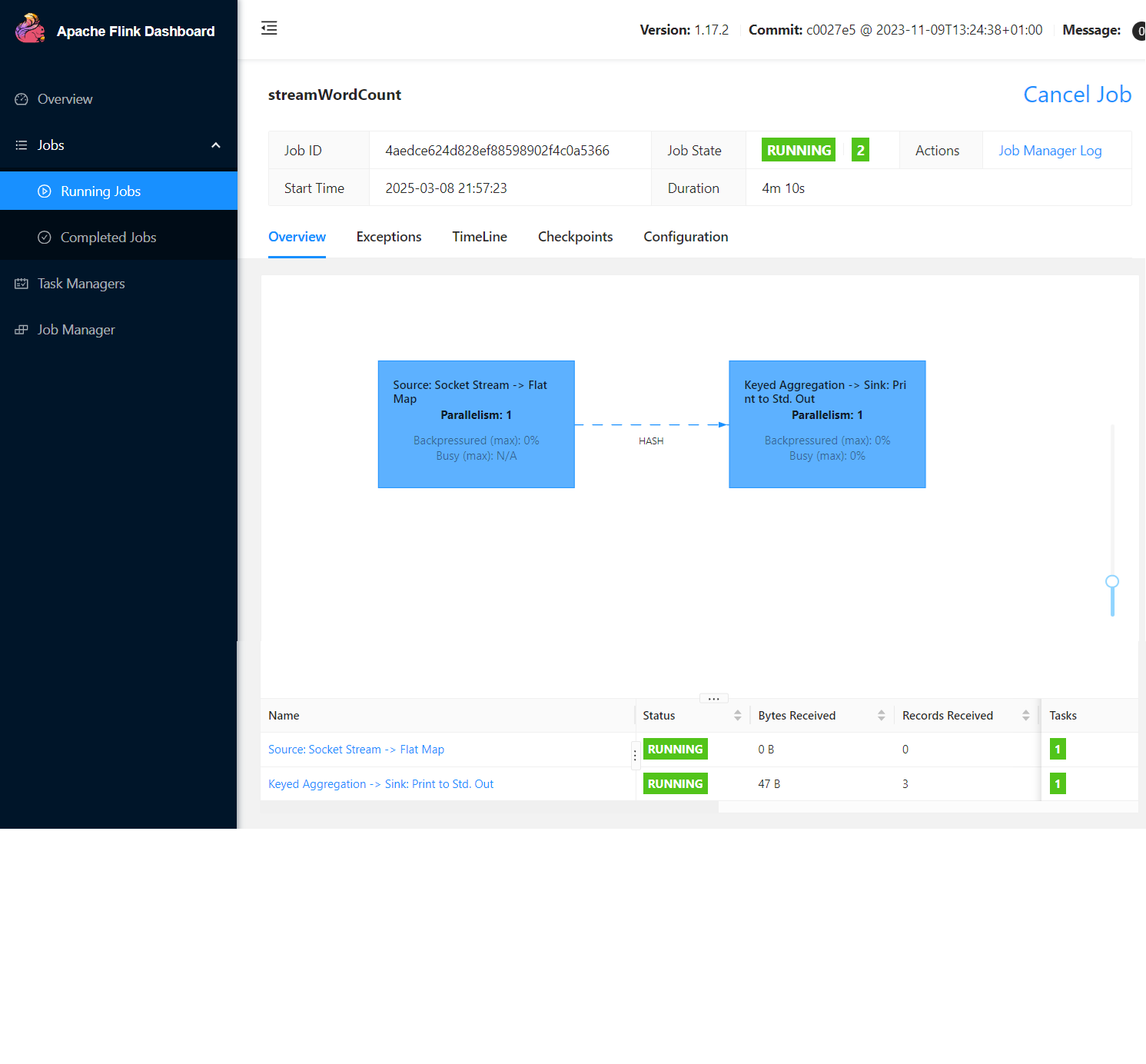
- 可以使用命令行查看或取消作业,命令如下:
[jack@hadoop102 flink-1.17.2]$ bin/flink list -t yarn-per-job -Dyarn.application.id=application_XXXX_YY
[jack@hadoop102 flink-1.17.2]$ bin/flink cancel -t yarn-per-job -Dyarn.application.id=application_XXXX_YY jobId这里的application_XXXX_YY是当前应用的ID,jobId是作业的ID。注意如果取消作业,整个Flink集群也会停掉。
3.6 应用模式部署
应用模式同样非常简单,与单作业模式类似,直接执行flink run-application命令即可。
- 命令行提交
执行命令提交作业:
[jack@hadoop102 flink-1.17.2]$ bin/flink run-application -d -t yarn-application -c com.rocket.flink.SocketStreamWordCount lib/flink-demo-1.0-SNAPSHOT.jar命令执行后,在Yarn的applications菜单中可以看到当前应用: 点击ApplicationMaster按钮,跳转到代理flink页面:
点击ApplicationMaster按钮,跳转到代理flink页面: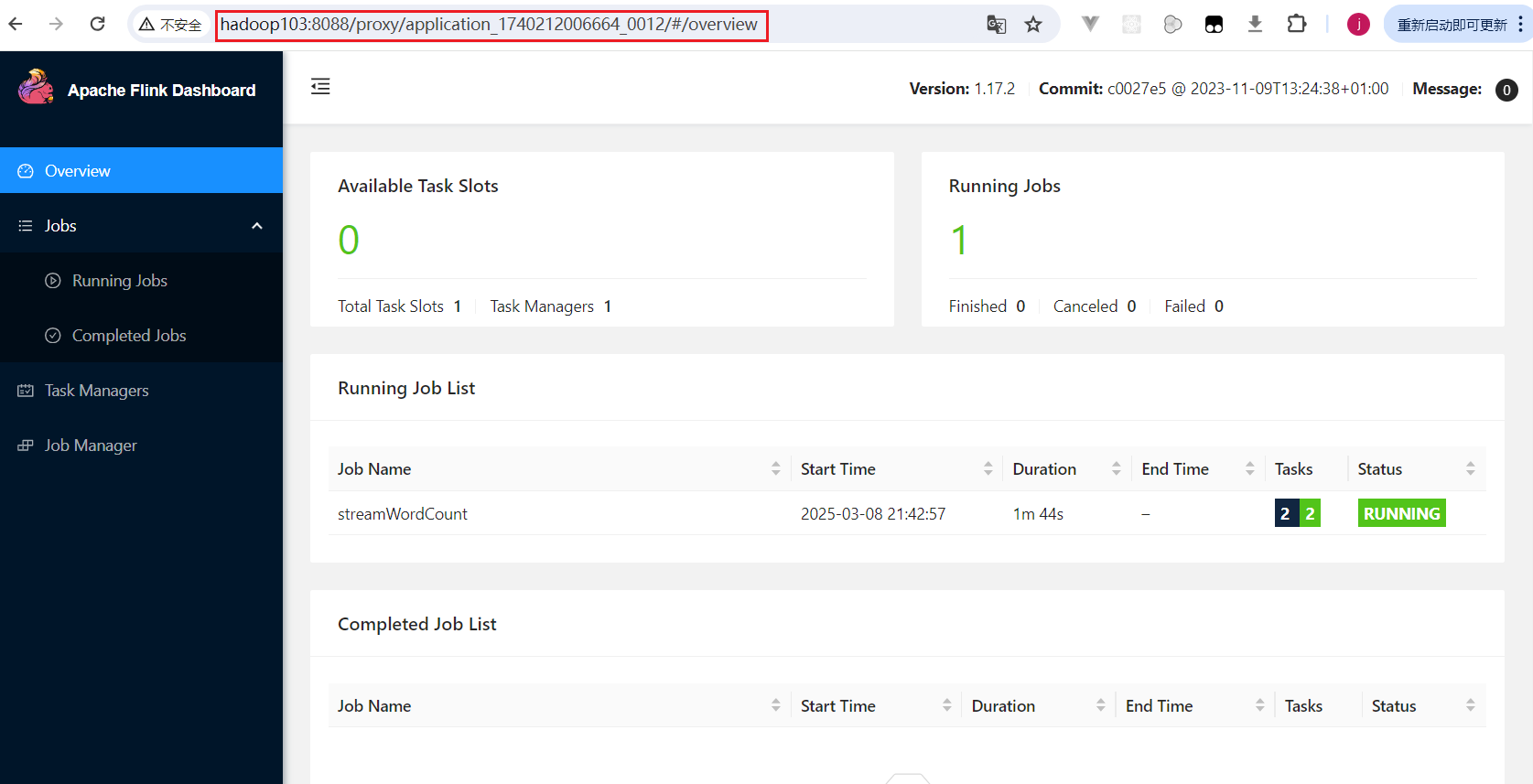 2. 在命令行中查看或取消作业:
2. 在命令行中查看或取消作业:
[jack@hadoop102 flink-1.17.2]$ bin/flink list -t yarn-application -Dyarn.application.id=application_XXXX_YY
[jack@hadoop102 flink-1.17.2]$ bin/flink cancel -t yarn-application -Dyarn.application.id=application_XXXX_YY <jobId>3.7 上传HDFS提交
可以通过yarn.provided.lib.dirs配置选项指定位置,将flink的依赖上传到远程。
- 上传flink的lib和plugins到HDFS上
[jack@hadoop102 flink-1.17.2]$ hadoop fs -mkdir /flink-dist
[jack@hadoop102 flink-1.17.2]$ hadoop fs -put lib/ /flink-dist
[jack@hadoop102 flink-1.17.2]$ hadoop fs -put plugins/ /flink-dist- 上传自己的jar包到HDFS
[jack@hadoop102 flink-1.17.2]$ hadoop fs -mkdir /flink-jars
[jack@hadoop102 flink-1.17.2]$ hadoop fs -put lib/flink-demo-1.0-SNAPSHOT.jar /flink-jars- 提交作业
[jack@hadoop102 flink-1.17.2]$ bin/flink run-application -t yarn-application -Dyarn.provided.lib.dirs="hdfs://hadoop102:8020/flink-dist" -c com.rocket.flink.SocketStreamWordCount hdfs://hadoop102:8020/flink-jars/flink-demo-1.0-SNAPSHOT.jar
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/module/flink-1.17.2/lib/log4j-slf4j-impl-2.17.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/hadoop-3.3.6/share/hadoop/common/lib/slf4j-reload4j-1.7.36.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
2024-09-01 15:34:35,668 WARN org.apache.flink.yarn.configuration.YarnLogConfigUtil [] - The configuration directory ('/opt/module/flink-1.17.2/conf') already contains a LOG4J config file.If you want to use logback, then please delete or rename the log configuration file.
2024-09-01 15:34:35,755 INFO org.apache.hadoop.yarn.client.DefaultNoHARMFailoverProxyProvider [] - Connecting to ResourceManager at hadoop103/192.168.101.103:8032
2024-09-01 15:34:36,070 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
2024-09-01 15:34:36,322 INFO org.apache.hadoop.conf.Configuration [] - resource-types.xml not found
2024-09-01 15:34:36,323 INFO org.apache.hadoop.yarn.util.resource.ResourceUtils [] - Unable to find 'resource-types.xml'.
2024-09-01 15:34:36,449 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - The configured JobManager memory is 1600 MB. YARN will allocate 2048 MB to make up an integer multiple of its minimum allocation memory (1024 MB, configured via 'yarn.scheduler.minimum-allocation-mb'). The extra 448 MB may not be used by Flink.
2024-09-01 15:34:36,450 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - The configured TaskManager memory is 1728 MB. YARN will allocate 2048 MB to make up an integer multiple of its minimum allocation memory (1024 MB, configured via 'yarn.scheduler.minimum-allocation-mb'). The extra 320 MB may not be used by Flink.
2024-09-01 15:34:36,450 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Cluster specification: ClusterSpecification{masterMemoryMB=1600, taskManagerMemoryMB=1728, slotsPerTaskManager=1}
2024-09-01 15:34:38,638 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Submitting application master application_1723025832151_0008
2024-09-01 15:34:38,702 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl [] - Submitted application application_1723025832151_0008
2024-09-01 15:34:38,702 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Waiting for the cluster to be allocated
2024-09-01 15:34:38,706 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Deploying cluster, current state ACCEPTED
2024-09-01 15:35:05,861 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - YARN application has been deployed successfully.
2024-09-01 15:35:05,862 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface hadoop102:8081 of application 'application_1723025832151_0008'.在这种方式下,flink本身的依赖和用户jar可以预先上传到HDFS,而不需要单独发送到集群,这就使得作业提交更加轻量了。
4. 历史服务器
运行Flink job的集群一旦停止,只能去yarn或本地磁盘上查看日志,不再可以查看作业挂掉之前的运行的Web UI,很难清楚知道作业在挂的那一刻到底发生了什么。如果我们还没有Metrics监控的话,那么完全就只能通过日志去分析和定位问题了,所以如果能还原之前的Web UI,我们可以通过UI发现和定位一些问题。
Flink提供了历史服务器,用来在相应的Flink集群关闭后查询已完成作业的统计信息。我们都知道只有当作业处于运行中的状态,才能够查看到相关的WebUI统计信息。通过History Server我们才能查询这些已完成作业的统计信息,无论是正常退出还是异常退出。
此外它对外提供了REST API,它接受HTTP请求并使用JSON数据进行响应。Flink任务停止后,JobManager会将已经完成任务的统计信息进行存档,History Server进程则在任务停止后可以对任务统计信息进行查询。比如:最后一次的 Checkpoint、任务运行时的相关配置。
4.1 创建存储日志目录
[jack@hadoop102 flink-1.17.2]$ hadoop fs -mkdir -p /flink/logs/flink-job4.2 在flink-conf.yaml中添加如下配置
jobmanager.archive.fs.dir: hdfs://hadoop102:8020/flink/logs/flink-job
historyserver.web.address: hadoop102
historyserver.web.port: 8082
historyserver.archive.fs.dir: hdfs://hadoop102:8020/flink/logs/flink-job
historyserver.archive.fs.refresh-interval: 50004.3 启动历史服务器
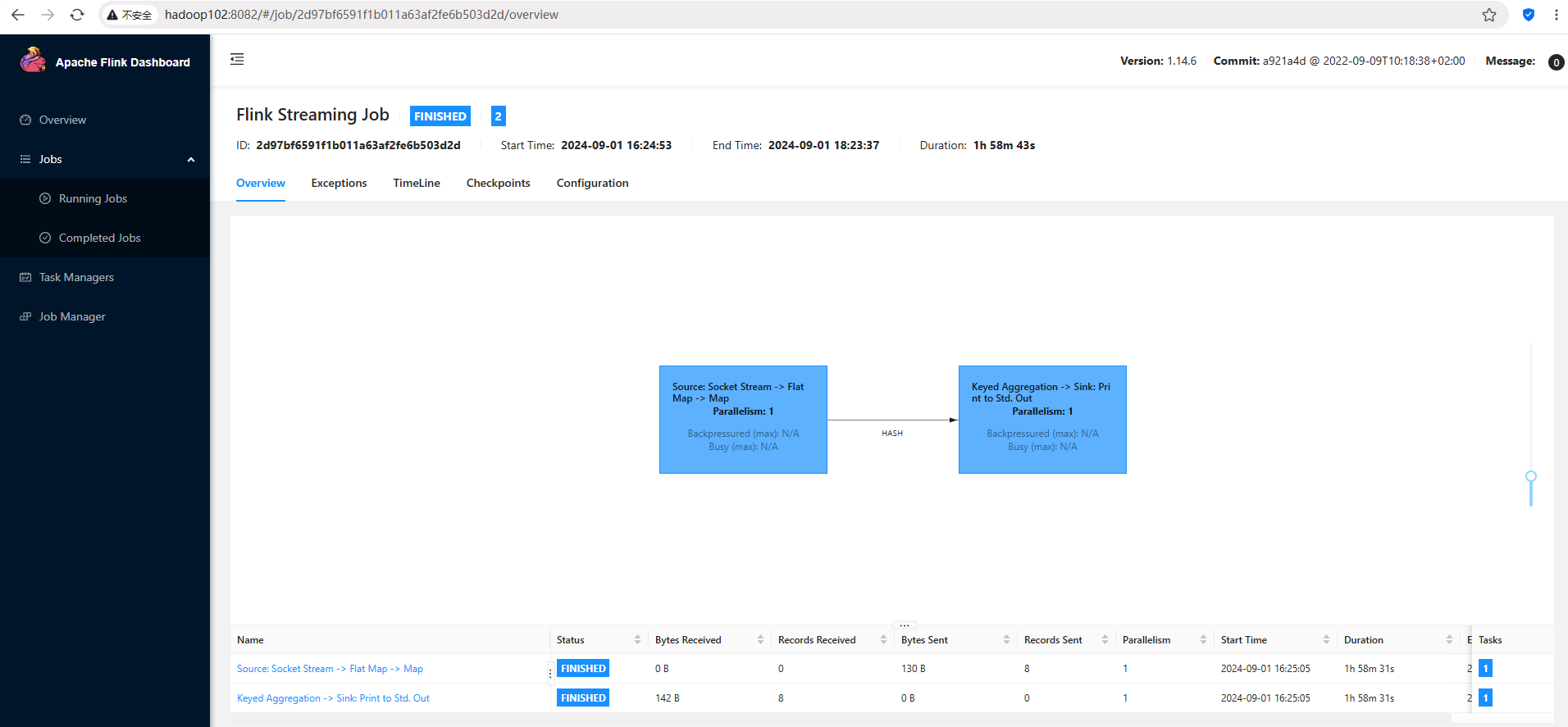
bin/historyserver.sh start在此之后的flink任务都会被自动记录到历史服务器里面:
# 启动flink任务,比如我启动应用模式任务:
[jack@hadoop102 flink-1.17.2]$ bin/flink run-application -t yarn-application -Dyarn.provided.lib.dirs="hdfs://hadoop102:8020/flink-dist" -c com.rocket.flink.SocketStreamWordCount hdfs://hadoop102:8020/flink-jars/flink-demo-1.0-SNAPSHOT.jar4.4 停止历史服务器
bin/historyserver.sh stop4.5 查看历史日志
在浏览器地址栏输入:http://hadoop102:8082, 查看已经停止的job的统计信息,中间等了差不多40分钟🙃,终于结果出来了: