FlinkSQL方式的应用
1. 添加依赖
相比前面的pom.xml,额外添加相关table api的依赖
xml
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-runtime</artifactId>
<version>1.17.2</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-loader</artifactId>
<version>1.17.2</version>
</dependency>2. 编写代码
java
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 使用连接器为mysql-cdc的连接器
tableEnv.executeSql("create table t1(\n" +
" id string primary key NOT ENFORCED,\n" +
" name string ) WITH (\n" +
" 'connector' = 'mysql-cdc',\n" +
" 'hostname' = 'hadoop104',\n" +
" 'port' = '3307',\n" +
" 'username' = 'root',\n" +
" 'password' = 'root',\n" +
" 'database-name' = 'test',\n" +
" 'table-name' = 't1'\n" +
")");
Table table = tableEnv.sqlQuery("select * from t1");
table.execute().print();
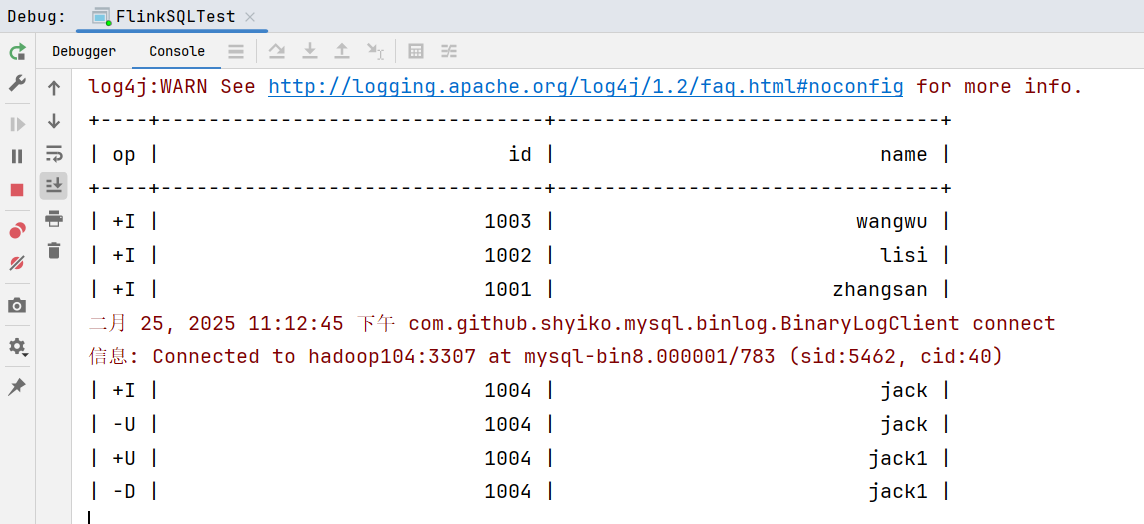
}运行效果: