使用Connector读写
1. Kafka
1.1 添加kafka连接器依赖
(1)将flink-sql-connector-kafka-1.17.2.jar上传到flink的lib目录下
(2)重启yarn-session、sql-client
1.2 普通Kafka表
sql
-- 创建Kafka的映射表
create table t1(
id int,
ts bigint,
vc int,
`event_time` timestamp(3) metadata from 'timestamp',
--列名和元数据名一致可以省略 FROM 'xxxx', VIRTUAL表示只读
`partition` bigint metadata virtual,
`offset` bigint metadata virtual
)
with (
'connector'= 'kafka',
'properties.bootstrap.servers'='hadoop103:9092',
'properties.group.id'='kafka',
-- 'earliest-offset', 'latest-offset', 'group-offsets', 'timestamp' and 'specific-offsets'
'scan.startup.mode'='earliest-offset',
-- fixed为flink实现的分区器,一个并行度只写往kafka一个分区
'sink.partitioner'='fixed',
'topic'='ws1',
'format'='json'
);1.3 插入Kafka表
sql
insert into t1(id,ts,vc) select * from source;1.4 查询Kafka表
sql
select * from t1;运行结果: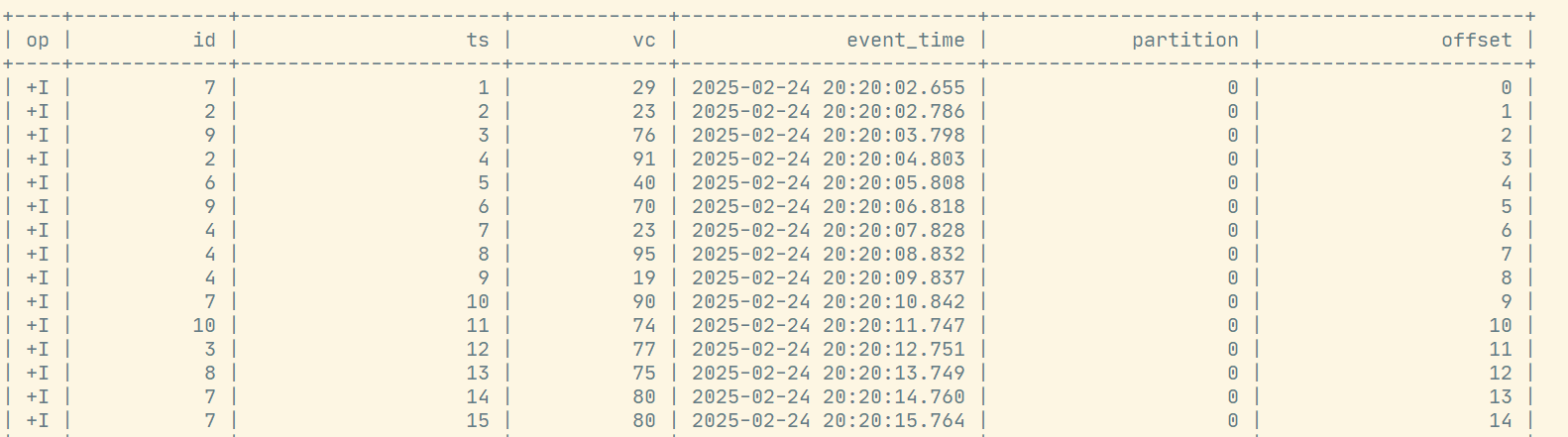
2. upsert-kafka表
如果当前表存在更新操作,那么普通的kafka连接器将无法满足,此时可以使用Upsert Kafka连接器。
作为source,upsert-kafka连接器生产changelog流,其中每条数据记录代表一个更新或删除事件。
作为sink,upsert-kafka连接器可以消费changelog流。它会将INSERT/UPDATE_AFTER数据作为正常的Kafka消息写入,并将DELETE数据以value为空的Kafka消息写入(表示对应key的消息被删除)。
2.1 创建upsert-kafka的映射表(必须定义主键)
sql
CREATE TABLE t2(
id int ,
sumVC int ,
primary key (id) NOT ENFORCED
)
WITH (
'connector' = 'upsert-kafka',
'properties.bootstrap.servers' = 'hadoop103:9092',
'topic' = 'ws2',
'key.format' = 'json',
'value.format' = 'json'
);2.2 插入upsert-kafka表
sql
insert into t2 select id,sum(vc) sumVC from source group by id;2.3 查询upsert-kafka表
upsert-kafka 无法从指定的偏移量读取,只会从主题的源读取。
sql
select * from t2;运行结果:
3. File
3.1 创建FileSystem映射表
sql
CREATE TABLE t3( id int, ts bigint , vc int )
WITH (
'connector'='filesystem',
'path'='hdfs://hadoop102:8020/warehouse/t3',
'format'='csv'
);3.2 写入
sql
insert into t3 select * from source;3.3 查询
sql
select * from t3 where id = '1';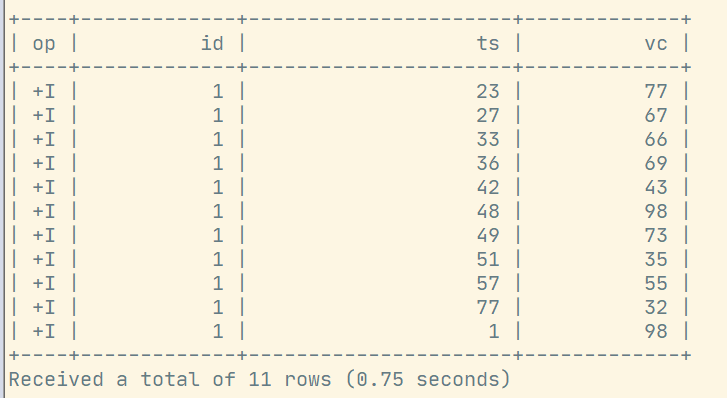 刚开始查询还在写入中,可能会查不到数据。
刚开始查询还在写入中,可能会查不到数据。
4. JDBC(MySQL)
Flink在将数据写入外部数据库时使用DDL中定义的主键。如果定义了主键,则连接器以upsert模式操作,否则,连接器以追加模式操作。
4.1 mysql的test库中建表
sql
CREATE TABLE `ws2` (
`id` int(11) NOT NULL,
`ts` bigint(20) DEFAULT NULL,
`vc` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;4.2 添加JDBC连接器依赖
上传jdbc连接器的jar包和mysql的连接驱动包到flink/lib下:
- flink-connector-jdbc-3.2.0-1.19.jar
- mysql-connector-j-8.0.31.jar
4.3 创建JDBC映射表
sql
CREATE TABLE t4
(
id INT,
ts BIGINT,
vc INT,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector'='jdbc',
'url' = 'jdbc:mysql://hadoop104:3307/test?useUnicode=true&characterEncoding=UTF-8',
'username' = 'root',
'password' = 'root',
'connection.max-retry-timeout' = '60s',
'table-name' = 'ws2',
'sink.buffer-flush.max-rows' = '500',
'sink.buffer-flush.interval' = '5s',
'sink.max-retries' = '3',
'sink.parallelism' = '1'
);4.4 查询
sql
select * from t4;4.5 写入
sql
insert into t4 select * from source;运行结果: