容错机制之状态一致性
1. 一致性的概念和级别
一致性其实就是结果的正确性,一般从数据丢失、数据重复来评估。流式计算本身就是一个一个来的,所以正常处理的过程中结果肯定是正确的;但在发生故障、需要恢复状态进行回滚时就需要更多的保障机制了。我们通过检查点的保存来保证状态恢复后结果的正确,所以主要讨论的就是"状态的一致性"。
一般说来,状态一致性有三种级别:
- 最多一次(At-Most-Once)
- 至少一次(At-Least-Once)
- 精确一次(Exactly-Once)
2. 端到端的状态一致性
我们不仅要考虑Flink内部数据的处理转换,还涉及到从外部数据源读取,以及写入外部持久化系统,整个应用处理流程从头到尾都应该是正确的。所以完整的流处理应用,应该包括了数据源、流处理器和外部存储系统三个部分。这个完整应用的一致性,就叫做"端到端(end-to-end)的状态一致性",它取决于三个组件中最弱的那一环。一般来说,能否达到at-least-once一致性级别,主要看数据源能够重放数据;而能否达到exactly-once级别,流处理器内部、数据源、外部存储都要有相应的保证机制。
3. 端到端精确一次
对于Flink内部来说,检查点机制可以保证故障恢复后数据不丢(在能够重放的前提下),并且只处理一次,所以已经可以做到exactly-once的一致性语义了。
所以端到端一致性的关键点,就在于输入的数据源端和输出的外部存储端。 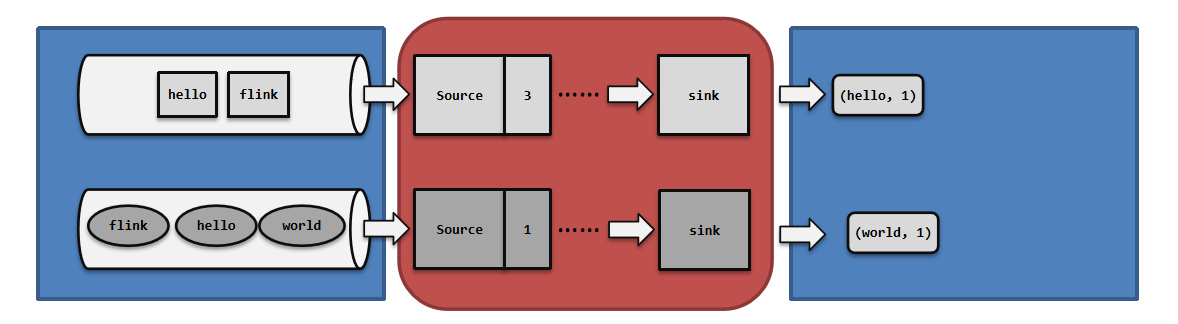
- 输入端:数据可重放。如Kafka,可重置读取数据偏移量
- Flink处理:开启checkpoint且精准一次
- barrier对齐精准一次
- 非barrier对齐精准一次
- 输出端:幂等或事务
- 幂等:利用mysql的主键upsert、hbase的rowkey唯一
- 事务(外部系统提供):两阶段提交写kafka、两阶段提交写MySQL(XA事务)
3.1 输入端保证
输入端主要指的就是Flink读取的外部数据源。想要在故障恢复后不丢数据,外部数据源就必须拥有重放数据的能力。常见的做法就是对数据进行持久化保存,并且可以重设数据的读取位置。
一个最经典的应用就是Kafka。在Flink的Source任务中将数据读取的偏移量保存为状态,这样就可以在故障恢复时从检查点中读取出来,对数据源重置偏移量,重新获取数据。数据源可重放数据,或者说可重置读取数据偏移量,加上Flink的Source算子将偏移量作为状态保存进检查点,就可以保证数据不丢。
3.2 输出端保证
为了实现端到端exactly-once,我们还需要对外部存储系统、以及Sink连接器有额外的要求。能够保证exactly-once一致性的写入方式有两种:幂等写入、事务写入
3.3 幂等(Idempotent)写入
所谓"幂等"操作,就是说一个操作可以重复执行很多次,但只导致一次结果更改。也就是说,后面再重复执行就不会对结果起作用了。这相当于说,我们并没有真正解决数据重复计算、写入的问题;而是说,重复写入也没关系,结果不会改变。所以这种方式主要的限制在于外部存储系统必须支持这样的幂等写入:比如Redis中键值存储,或者关系型数据库(如MySQL)中满足查询条件的更新操作。
需要注意,对于幂等写入,遇到故障进行恢复时,有可能会出现短暂的不一致。因为保存点完成之后到发生故障之间的数据,其实已经写入了一遍,回滚的时候并不能消除它们。
3.4 事务(Transactional)写入
在Flink流处理的结果写入外部系统时,如果能够构建一个事务,让写入操作可以随着检查点来提交和回滚,那么自然就可以解决重复写入的问题了。所以事务写入的基本思路就是:用一个事务来进行数据向外部系统的写入,这个事务是与检查点绑定在一起的。当Sink任务遇到barrier时,开始保存状态的同时就开启一个事务,接下来所有数据的写入都在这个事务中;待到当前检查点保存完毕时,将事务提交,所有写入的数据就真正可用了。如果中间过程出现故障,状态会回退到上一个检查点,而当前事务没有正常关闭(因为当前检查点没有保存完),所以也会回滚,写入到外部的数据就被撤销了。
具体来说,又有两种实现方式:预写日志(WAL)和两阶段提交(2PC)
3.5 预写日志(write-ahead-log,WAL)
我们发现,事务提交是需要外部存储系统支持事务的,否则没有办法真正实现写入的回撤。那对于一般不支持事务的存储系统,能够实现事务写入呢?预写日志(WAL)就是一种非常简单的方式。具体步骤是:
1️⃣先把结果数据作为日志(log)状态保存起来。
2️⃣进行检查点保存时,也会将这些结果数据一并做持久化存储。
3️⃣在收到检查点完成的通知时,将所有结果一次性写入外部系统。
4️⃣在成功写入所有数据后,在内部再次确认相应的检查点,将确认信息也进行持久化保存。这才代表着检查点的真正完成。
在Flink中DataStream API提供了一个模板类GenericWriteAheadSink,用来实现这种事务型的写入方式。需要注意的是,预写日志这种批写入的方式有可能会写入失败;比如最后"再次确认"的方式,也会有一些缺陷。如果我们的检查点已经成功保存、数据也成功地一批写入到了外部系统,但是最终保存确认信息时出现了故障,Flink最终还是会认为没有成功写入。于是发生故障时,不会使用这个检查点,而是需要回退到上一个;这样就会导致这批数据的重复写入。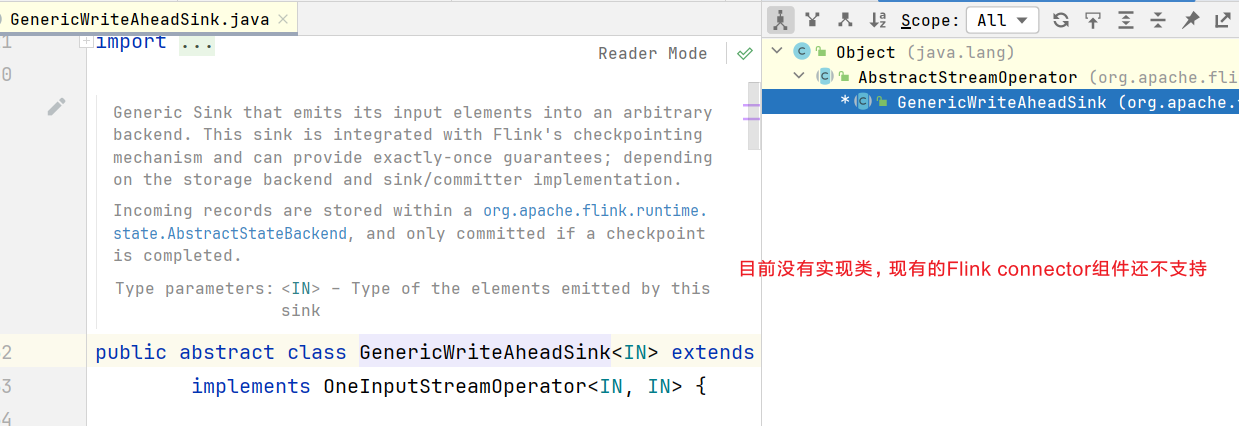
3.6 两阶段提交(two-phase-commit,2PC)
2PC分成两个阶段:先做"预提交",等检查点完成之后再正式提交。这种提交方式是真正基于事务的,它需要外部系统提供事务支持。具体的实现步骤为:
1️⃣ 当第一条数据到来时,或者收到检查点的分界线时,Sink任务都会启动一个事务。
2️⃣ 接下来接收到的所有数据,都通过这个事务写入外部系统;这时由于事务没有提交,所以数据尽管写入了外部系统,但是不可用,是"预提交"的状态。
3️⃣ 当Sink任务收到JobManager发来检查点完成的通知时,正式提交事务,写入的结果就真正可用了。
4️⃣ 当中间发生故障时,当前未提交的事务就会回滚,于是所有写入外部系统的数据也就实现了撤回。
Flink提供了TwoPhaseCommitSinkFunction接口,方便我们自定义实现两阶段提交的SinkFunction的实现,提供了真正端到端的exactly-once保证。新的Sink架构,使用的是TwoPhaseCommittingSink接口。2PC对外部系统的要求列举如下:
- 外部系统必须提供事务支持,或者Sink任务必须能够模拟外部系统上的事务。
- 在检查点的间隔期间里,必须能够开启一个事务并接受数据写入。
- 在收到检查点完成的通知之前,事务必须是"等待提交"的状态。在故障恢复的情况下,这可能需要一些时间。如果这个时候外部系统关闭事务(例如超时了),那么未提交的数据就会丢失。
- Sink任务必须能够在进程失败后恢复事务。
- 提交事务必须是幂等操作。也就是说,事务的重复提交应该是无效的。
可见,2PC在实际应用同样会受到比较大的限制。
4. Flink和Kafka连接时的精确一次保证
实际项目中经常会看到以Kafka作为数据源和写入的外部系统的应用。 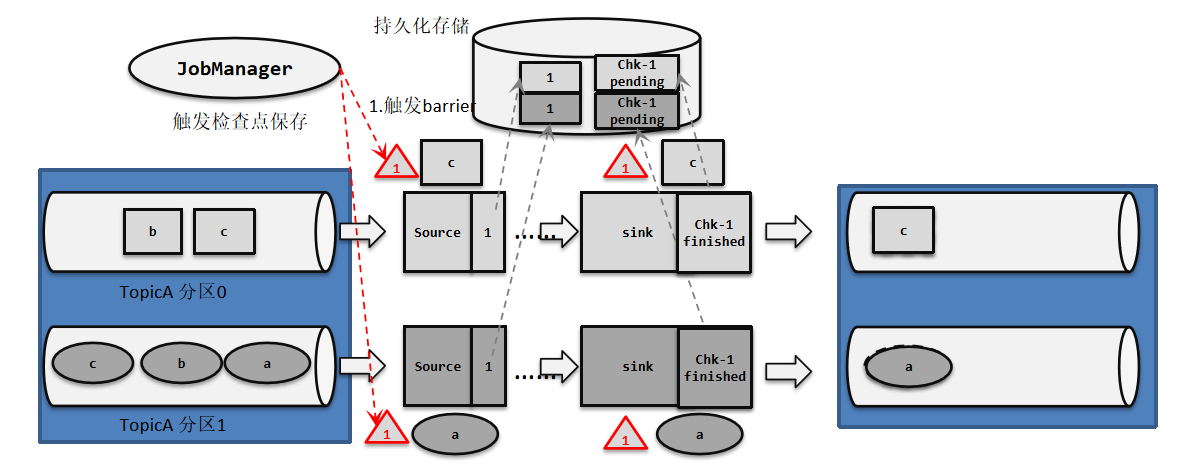 ①JobManager发送指令,触发检查点的保存:所有Source节点插入一个id=1的barrier,触发source节点将偏移量保存到远程的持久化存储中。
①JobManager发送指令,触发检查点的保存:所有Source节点插入一个id=1的barrier,触发source节点将偏移量保存到远程的持久化存储中。
②sink节点接收到Flink启动后的第一条数据,负责开启Kafka的第一次事务,预提交开始。同时会将事务的状态保存到状态里
③预提交阶段:到达sink的数据会调用kafka producer的send(),数据写入缓冲区,再flush()。此时数据写到kafka中,标记为"未提交"状态。如果任意一个sink节点预提交过程中出现失败,整个预提交会放弃。
④id=1的barrier到达sink节点,触发barrier节点的本地状态保存到hdfs本地状态包含自身的状态和事务快照。同时开启一个新的Kafka事务,用于该barrier后面数据的预提交,如:分区0的b,分区1的b、c。只有第一个事务由第一条数据开启,后面都是由barrier开启事务。
⑤全部节点做完本地checkpoint,jobmanager向所有节点发送一个本轮成功的回调消息,预提交结束。
⑥sink收到checkpoint完成的通知,进行事务正式提交,将写入kafka数据的标记修改成"已提交",如果发生故障,回滚到上次成功完成快照的时间点。
⑦成功正式提交后,kafka会返回一个消息给sink节点,sink节点会将存在状态里的事务状态,修改为finished状态。
4.1 整体介绍
既然是端到端的exactly-once,我们依然可以从三个组件的角度来进行分析:
- Flink内部
Flink内部可以通过检查点机制保证状态和处理结果的exactly-once语义。 - 输入端
输入数据源端的Kafka可以对数据进行持久化保存,并可以重置偏移量(offset)。所以我们可以在Source任务(FlinkKafkaConsumer)中将当前读取的偏移量保存为算子状态,写入到检查点中;当发生故障时,从检查点中读取恢复状态,并由连接器FlinkKafkaConsumer向Kafka重新提交偏移量,就可以重新消费数据、保证结果的一致性了。 - 输出端
输出端保证exactly-once的最佳实现,当然就是两阶段提交(2PC)。也就是说,我们写入Kafka的过程实际上是一个两段式的提交:处理完毕得到结果,写入Kafka时是基于事务的"预提交";等到检查点保存完毕,才会提交事务进行"正式提交"。如果中间出现故障,事务进行回滚,预提交就会被放弃;恢复状态之后,也只能恢复所有已经确认提交的操作。
4.2 需要的配置
在具体应用中,实现真正的端到端exactly-once,还需要有一些额外的配置:
(1)必须启用检查点
(2)指定KafkaSink的发送级别为DeliveryGuarantee.EXACTLY_ONCE
(3)配置Kafka读取数据的消费者的隔离级别
这里所说的Kafka,是写入的外部系统。预提交阶段数据已经写入,只是被标记为"未提交"(uncommitted),而Kafka中默认的隔离级别isolation.level是read_uncommitted,也就是可以读取未提交的数据。这样一来,外部应用就可以直接消费未提交的数据,对于事务性的保证就失效了。所以应该将隔离级别配置为read_committed,表示消费者遇到未提交的消息时,会停止从分区中消费数据,直到消息被标记为已提交才会再次恢复消费。当然,这样做的话,外部应用消费数据就会有显著的延迟。
(4)事务超时配置
Flink的Kafka连接器中配置的事务超时时间transaction.timeout.ms默认是1小时,而Kafka集群配置的事务最大超时时间transaction.max.timeout.ms默认是15分钟。需要设置两个超时时间,前者应该小于等于后者。
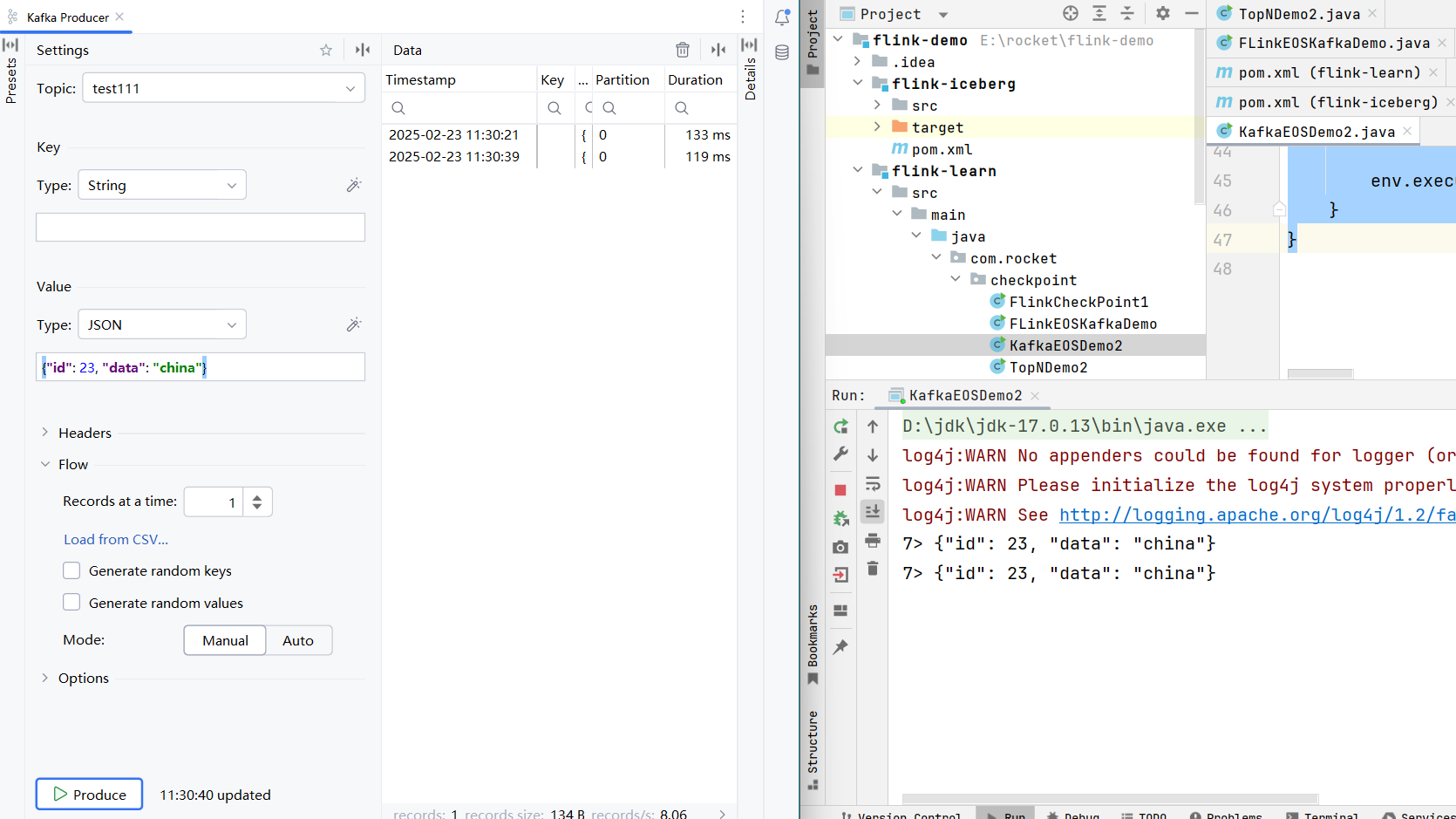
public class FLinkEOSKafkaDemo {
public static void main(String[] args) throws Exception {
// 只要用HDFS,需要指定用户名
System.setProperty("HADOOP_USER_NAME", "jack");
LocalStreamEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();
// 每隔5秒启动一次检查点保存, 不配置默认是EXACTLY_ONCE
env.enableCheckpointing(5000, CheckpointingMode.EXACTLY_ONCE);
CheckpointConfig checkpointConfig = env.getCheckpointConfig();
// 设置检查点保存的路径
checkpointConfig.setCheckpointStorage("hdfs://hadoop102:8020/flink/ckps");
// checkpoint的超时时间, 默认10分钟
checkpointConfig.setCheckpointTimeout(60000);
checkpointConfig.setExternalizedCheckpointCleanup(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
// 2.读取kafka
KafkaSource<String> kafkaSource = KafkaSource.<String>builder()
.setBootstrapServers("hadoop103:9092,hadoop104:9092")
.setGroupId("flink")
.setTopics("test111")
.setValueOnlyDeserializer(new SimpleStringSchema())
.setStartingOffsets(OffsetsInitializer.latest())
.build();
DataStreamSource<String> kafkaDS = env
.fromSource(kafkaSource, WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(3)), "kafkasource");
// 配置kafkaSink
KafkaSink<String> kafkaSink = KafkaSink.<String>builder().setBootstrapServers("hadoop103:9092")
.setRecordSerializer(KafkaRecordSerializationSchema.builder()
.setTopic("flink-topic")
.setValueSerializationSchema(new SimpleStringSchema())
.build())
.setDeliveryGuarantee(DeliveryGuarantee.EXACTLY_ONCE)
.setTransactionalIdPrefix("tx-")
// 精准一次,必须设置事务超时时间: 大于checkpoint间隔,小于 max 15分钟
.setProperty(ProducerConfig.TRANSACTION_TIMEOUT_CONFIG, 10 * 60 * 1000 + "")
.build();
kafkaDS.sinkTo(kafkaSink);
env
.fromSource(kafkaSource, WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(3)), "flink-topic")
.print();
env.execute("kafka2kafka");
}
}public class KafkaEOSDemo2 {
public static void main(String[] args) throws Exception {
// 只要用HDFS,需要指定用户名
System.setProperty("HADOOP_USER_NAME", "jack");
LocalStreamEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();
// 2.读取kafka
KafkaSource<String> kafkaSource = KafkaSource.<String>builder()
.setBootstrapServers("hadoop103:9092,hadoop104:9092")
.setGroupId("flink123")
.setTopics("flink-topic")
.setValueOnlyDeserializer(new SimpleStringSchema())
.setStartingOffsets(OffsetsInitializer.latest())
// 作为下游的消费者,要设置 事务的隔离级别 = 读已提交
.setProperty(ConsumerConfig.ISOLATION_LEVEL_CONFIG, "read_committed")
.build();
env
.fromSource(kafkaSource, WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(3)), "flink-topic")
.print();
env.execute("kafka2kafka");
}
}运行效果: